快速指南
Python Deep Learning - Introduction
深度结构化学习或分层学习或简称深度学习是机器学习方法系列的一部分,这些方法本身就是更广泛的人工智能领域的一个子集。
深度学习是一类机器学习算法,它使用多层非线性处理单元进行特征提取和转换。 每个连续层使用前一层的输出作为输入。
深度神经网络,深度信念网络和递归神经网络已应用于计算机视觉,语音识别,自然语言处理,音频识别,社交网络过滤,机器翻译和生物信息学等领域,在这些领域中,他们产生的结果与某些情况下的结果相当比人类专家更好。
深度学习算法和网络 -
基于无监督学习多级特征或数据表示。 较高级别的特征源自较低级别的特征以形成分层表示。
使用某种形式的梯度下降进行训练。
Python Deep Learning - Environment
在本章中,我们将了解为Python深度学习设置的环境。 我们必须安装以下软件来制作深度学习算法。
- Python 2.7+
- Scipy和Numpy
- Matplotlib
- Theano
- Keras
- TensorFlow
强烈建议通过Anaconda发行版安装Python,NumPy,SciPy和Matplotlib。 它附带所有这些包。
我们需要确保正确安装不同类型的软件。
让我们转到我们的命令行程序并输入以下命令 -
$ python
Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34)
[GCC 7.2.0] on linux
接下来,我们可以导入所需的库并打印它们的版本 -
import numpy
print numpy.__version__
输出 (Output)
1.14.2
安装Theano,TensorFlow和Keras
在我们开始安装包 - Theano,TensorFlow和Keras之前,我们需要确认是否安装了pip 。 Anaconda的包裹管理系统被称为pip。
要确认pip的安装,请在命令行中键入以下内容 -
$ pip
一旦确认了pip的安装,我们就可以通过执行以下命令来安装TensorFlow和Keras -
$pip install theano
$pip install tensorflow
$pip install keras
执行以下代码行确认Theano的安装 -
$python –c “import theano: print (theano.__version__)”
输出 (Output)
1.0.1
通过执行以下代码行确认Tensorflow的安装 -
$python –c “import tensorflow: print tensorflow.__version__”
输出 (Output)
1.7.0
执行以下代码行确认Keras的安装 -
$python –c “import keras: print keras.__version__”
Using TensorFlow backend
输出 (Output)
2.1.5
Python Deep Basic Machine Learning
人工智能(AI)是使计算机能够模仿人类认知行为或智能的任何代码,算法或技术。 机器学习(ML)是AI的一个子集,它使用统计方法使机器能够通过经验学习和改进。 深度学习是机器学习的一个子集,它使多层神经网络的计算变得可行。 机器学习被视为浅层学习,而深度学习被视为具有抽象的层次学习。
机器学习涉及广泛的概念。 概念如下 -
- supervised
- unsupervised
- 强化学习
- linear regression
- 成本函数
- overfitting
- under-fitting
- hyper-parameter, etc.
在监督学习中,我们学会从标记数据中预测值。 一种有助于此的ML技术是分类,其中目标值是离散值; 例如,猫和狗。 机器学习中可能有帮助的另一种技术是回归。 回归适用于目标值。 目标值是连续值; 例如,可以使用回归分析股票市场数据。
在无监督学习中,我们根据未标记或结构化的输入数据进行推断。 如果我们有一百万个医疗记录并且我们必须弄清楚它,找到基础结构,异常值或检测异常,我们使用聚类技术将数据划分为广泛的聚类。
数据集分为训练集,测试集,验证集等。
2012年的突破使深度学习的概念突显出来。 一种算法使用2个GPU和大数据等最新技术成功地将100万个图像分类为1000个类别。
关于深度学习和传统机器学习
传统机器学习模型遇到的主要挑战之一是称为特征提取的过程。 程序员需要具体并告诉计算机要注意的功能。 这些功能有助于做出决策。
将原始数据输入算法很少有效,因此特征提取是传统机器学习工作流程的关键部分。
这给程序员带来了巨大的责任,算法的效率在很大程度上依赖于程序员的创造力。 对于诸如对象识别或手写识别之类的复杂问题,这是一个巨大的问题。
深度学习能够学习多层表示,是帮助我们自动进行特征提取的少数几种方法之一。 可以假设较低层执行自动特征提取,几乎不需要程序员的指导。
Artificial Neural Networks
人工神经网络,或简称神经网络,并不是一个新概念。 它已经存在了大约80年。
直到2011年,深度神经网络才开始流行使用新技术,庞大的数据集可用性和强大的计算机。
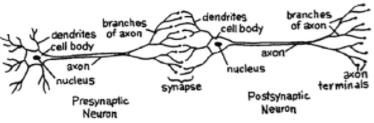
神经网络模仿神经元,其具有树突,核,轴突和末端轴突。
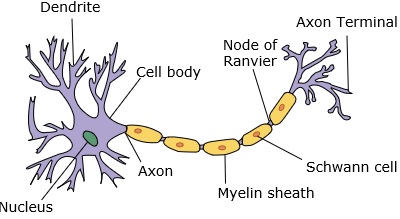
对于网络,我们需要两个神经元。 这些神经元通过一个的树突和另一个的末端轴突之间的突触传递信息。
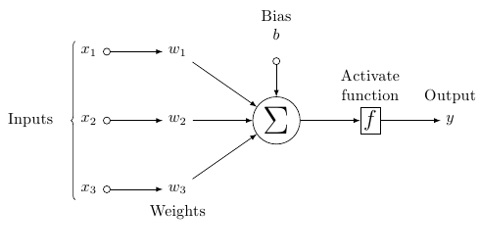
一个可能的人造神经元模型看起来像这样 -
神经网络如下图所示 -
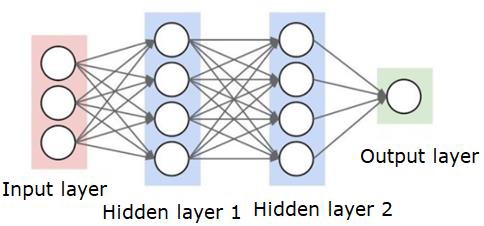
圆是神经元或节点,它们在数据上的功能和连接它们的线/边是传递的权重/信息。
每列都是一个图层。 数据的第一层是输入层。 然后,输入层和输出层之间的所有层都是隐藏层。
如果你有一个或几个隐藏层,那么你有一个浅层的神经网络。 如果你有许多隐藏层,那么你有一个深层神经网络。
在这个模型中,您有输入数据,您可以对其进行加权,并将其传递给神经元中称为阈值函数或激活函数的函数。
基本上,它是将某个值与某个值进行比较后的所有值的总和。 如果你发出一个信号,那么结果是(1)out,或者什么也没发出,然后是(0)。 然后将其加权并传递给下一个神经元,并运行相同类型的函数。
我们可以使用sigmoid(s形)函数作为激活函数。
至于权重,它们只是随机启动,并且每个输入到节点/神经元中它们是唯一的。
在典型的“前馈”中,最基本的神经网络类型,您可以直接通过您创建的网络传递信息,并将输出与您希望输出使用样本数据的内容进行比较。
从这里,您需要调整权重以帮助您使输出与您想要的输出相匹配。
直接通过神经网络发送数据的行为称为feed forward neural network.
我们的数据从输入,到层,按顺序,然后到输出。
当我们向后并开始调整权重以最小化损失/成本时,这称为back propagation.
这是一个optimization problem. 使用神经网络,在实际操作中,我们必须处理数十万个变量,或数百万或更多。
第一种解决方案是使用随机梯度下降作为优化方法。 现在,有AdaGrad,Adam Optimizer等选项。 无论哪种方式,这都是一个庞大的计算操作。 这就是为什么神经网络大多数被搁置半个多世纪的原因。 直到最近,我们甚至在我们的机器中拥有功能和架构,甚至考虑进行这些操作,以及匹配的适当大小的数据集。
对于简单的分类任务,神经网络在性能上与其他简单算法(如K Nearest Neighbors)相对接近。 当我们拥有更大的数据和更复杂的问题时,实现了神经网络的真正实用性,这两个问题都优于其他机器学习模型。
Deep Neural Networks
深度神经网络(DNN)是在输入和输出层之间具有多个隐藏层的ANN。 与浅层神经网络类似,DNN可以模拟复杂的非线性关系。
神经网络的主要目的是接收一组输入,对它们执行逐步复杂的计算,并提供输出以解决诸如分类之类的现实世界问题。 我们限制自己前馈神经网络。
我们在深层网络中有输入,输出和顺序数据流。
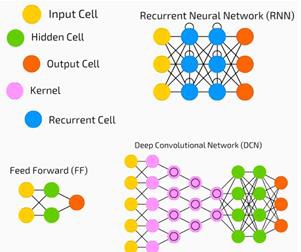
神经网络广泛用于监督学习和强化学习问题。 这些网络基于彼此连接的一组层。
在深度学习中,隐藏层的数量(大多数是非线性的)可能很大; 说大约1000层。
DL模型比普通ML网络产生更好的结果。
我们主要使用梯度下降法来优化网络并最小化损失函数。
我们可以使用Imagenet ,这是一个包含数百万个数字图像的存储库,可以将数据集分类为猫和狗等类别。 除了静态图像以及时间序列和文本分析之外,DL网络越来越多地用于动态图像。
训练数据集是深度学习模型的重要组成部分。 此外,反向传播是训练DL模型的主要算法。
DL涉及训练具有复杂输入输出变换的大型神经网络。
DL的一个示例是将照片映射到照片中的人的姓名,就像他们在社交网络上那样,并且用短语描述图片是DL的另一个近期应用。
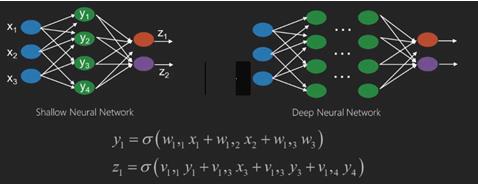
神经网络是具有x1,x2,x3等输入的函数,它们在两个(浅网络)或几个中间操作(也称为层(深层网络))中转换为输出,如z1,z2,z3等。
权重和偏差在层与层之间变化。 'w'和'v'是神经网络层的权重或突触。
深度学习的最佳用例是监督学习问题。在这里,我们有大量的数据输入和一组期望的输出。
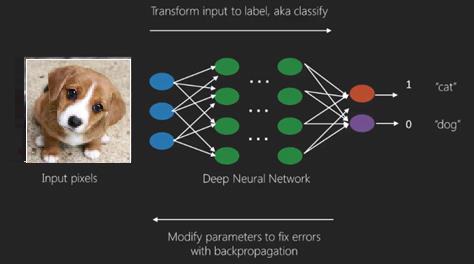
这里我们应用反向传播算法来获得正确的输出预测。
深度学习的最基本数据集是MNIST,即手写数字的数据集。
我们可以用Keras训练深度卷积神经网络,从这个数据集中分类手写数字的图像。
神经网络分类器的激活或激活产生分数。 例如,为了将患者分类为生病和健康,我们考虑身高,体重和体温,血压等参数。
高分意味着患者生病,低分意味着他健康。
输出和隐藏层中的每个节点都有自己的分类器。 输入层接收输入并将其分数传递到下一个隐藏层以进一步激活,并且这一直持续到达到输出。
从正向输入到输出从左到右的这种进展称为forward propagation.
神经网络中的信用分配路径(CAP)是从输入到输出的一系列变换。 CAP详细说明了输入和输出之间可能的因果关系。
给定前馈神经网络的CAP深度或CAP深度是隐藏层的数量加上包含输出层的一个。 对于递归神经网络,其中信号可以多次传播通过层,CAP深度可能是无限的。
深网和浅网
没有明确的深度阈值将浅层学习与深度学习分开; 但大多数人认为,对于具有多个非线性层的深度学习,CAP必须大于2。
神经网络中的基本节点是模仿生物神经网络中的神经元的感知。 然后我们有多层Perception或MLP。 每组输入都由一组权重和偏差修改; 每个边缘都有一个独特的重量,每个节点都有一个独特的偏差。
神经网络的预测accuracy取决于其weights and biases.
提高神经网络精度的过程称为training. 将前向道路网的输出与已知正确的值进行比较。
cost function or the loss function是生成的输出和实际输出之间的差异。
培训的目的是在数百万个培训示例中尽可能减少培训成本。为此,网络会调整权重和偏差,直到预测与正确的输出相匹配。
一旦训练好,神经网络就有可能每次都做出准确的预测。
当模式变得复杂并且您希望计算机识别它们时,您必须选择神经网络。在这种复杂的模式场景中,神经网络优于其他竞争算法。
现在有GPU可以比以前更快地训练它们。 深度神经网络已经彻底改变了人工智能领域
事实证明,计算机擅长执行重复计算并遵循详细说明,但并不擅长识别复杂模式。
如果存在识别简单模式的问题,支持向量机(svm)或逻辑回归分类器可以很好地完成工作,但随着模式的复杂性增加,除了深入的神经网络之外别无他法。
因此,对于像人脸这样的复杂模式,浅层神经网络会失败并且别无选择,只能选择具有更多层的深层神经网络。 深网能够通过将复杂的模式分解为更简单的模式来完成它们的工作。 例如,人脸; adeep net会使用边缘来检测嘴唇,鼻子,眼睛,耳朵等部位,然后将它们重新组合在一起形成一个人脸
正确预测的准确性已经变得如此准确,以至于最近在Google模式识别挑战赛中,一个深度网络击败了人类。
这种分层感知器网络的想法已经存在了一段时间; 在这个区域,深网模仿人类的大脑。 但其中一个缺点是它们需要很长时间才能进行训练,这是一个硬件约束
然而,最近的高性能GPU已经能够在一周内训练这样的深网; 虽然快速cpus可能需要数周或数月才能完成同样的工作。
选择一个深网
如何选择深网? 我们必须决定是否正在构建分类器,或者我们是否正在尝试在数据中查找模式以及是否要使用无监督学习。 要从一组未标记的数据中提取模式,我们使用Restricted Boltzman机器或Auto编码器。
选择深网时请考虑以下几点 -
对于文本处理,情感分析,解析和名称实体识别,我们使用递归网络或递归神经张量网络或RNTN;
对于在角色级别操作的任何语言模型,我们使用经常性网络。
对于图像识别,我们使用深信念网络DBN或卷积网络。
对于对象识别,我们使用RNTN或卷积网络。
对于语音识别,我们使用经常性网络。
一般而言,深度置信网络和具有整流线性单元或RELU的多层感知器都是分类的良好选择。
对于时间序列分析,始终建议使用循环网络。
神经网已经存在了50多年; 但直到现在他们才变得突出。 原因是他们很难训练; 当我们尝试使用一种称为反向传播的方法来训练它们时,我们会遇到一个称为消失或爆炸渐变的问题。当发生这种情况时,训练需要更长的时间,而准确性则会落后。 在训练数据集时,我们不断计算成本函数,即预测输出与一组标记训练数据的实际输出之间的差异。然后通过调整权重和偏差值将成本函数最小化,直到最低值得到了。 训练过程使用梯度,该梯度是成本相对于重量或偏差值的变化而变化的速率。
受限制的Boltzman网络或自动编码器-RBN
2006年,在解决消失梯度问题方面取得了突破。 杰夫·辛顿(Geoff Hinton)设计了一种新策略,该策略导致了Restricted Boltzman Machine - RBM的发展,这是一种浅层双层网络。
第一层是visible层,第二层是hidden层。 可见层中的每个节点都连接到隐藏层中的每个节点。 网络被称为限制,因为同一层内不允许两个层共享连接。
自动编码器是将输入数据编码为矢量的网络。 它们创建原始数据的隐藏或压缩表示。 这些向量可用于降维; 向量将原始数据压缩为较少数量的基本维度。 自动编码器与解码器配对,允许基于其隐藏表示重建输入数据。
RBM是双向翻译器的数学等价物。 正向传递接收输入并将它们转换为一组编码输入的数字。 同时,后向传递采用这组数字并将它们转换回重建输入。 训练有素的网络可以高精度地执行背部支撑。
在任何一个步骤中,权重和偏见都起着至关重要的作用; 它们有助于RBM解码输入之间的相互关系,并决定哪些输入对于检测模式至关重要。 通过前向和后向通过,RBM被训练以重新构造具有不同权重和偏差的输入,直到输入和构造尽可能接近。 RBM的一个有趣方面是不需要标记数据。 这对于真实世界的数据集非常重要,例如照片,视频,声音和传感器数据,所有这些数据都往往没有标记。 RBM不是通过人工手动标记数据,而是自动对数据进行排序; 通过适当调整权重和偏差,RBM能够提取重要特征并重建输入。 RBM是特征提取器神经网络系列的一部分,旨在识别数据中的固有模式。 这些也称为自动编码器,因为它们必须编码自己的结构。

深信仰网络 - DBN
深层信念网络(DBN)是通过结合RBM和引入一种聪明的训练方法形成的。 我们有一个新模型,最终解决了渐变消失的问题。 Geoff Hinton发明了RBMs和Deep Belief Nets作为反向传播的替代品。
DBN在结构上类似于MLP(多层感知器),但在培训方面却非常不同。 正是这种培训使DBN能够超越浅薄的同行
可以将DBN可视化为RBM的堆栈,其中一个RBM的隐藏层是其上方的RBM的可见层。 训练第一RBM以尽可能准确地重建其输入。
将第一RBM的隐藏层作为第二RBM的可见层,并使用来自第一RBM的输出训练第二RBM。 迭代该过程直到训练网络中的每个层。
在DBN中,每个RBM学习整个输入。 DBN通过连续微调整个输入来全球工作,因为模型慢慢改善,就像一个慢慢聚焦图像的相机镜头。 由于多层感知器MLP优于单个感知器,因此一堆RBM优于单个RBM。
在此阶段,RBM已检测到数据中的固有模式,但没有任何名称或标签。 为了完成DBN的培训,我们必须为模式引入标签,并通过监督学习对网进行微调。
我们需要一小组标记样本,以便功能和模式可以与名称相关联。 这个小标记的数据集用于训练。 与原始数据集相比,这组标记数据可以非常小。
重量和偏差略有改变,导致网络对图案的感知发生微小变化,并且总体精度通常略有增加。
与浅网相比,通过使用GPU可以在合理的时间内完成培训,得到非常准确的结果,我们也看到了消除梯度问题的解决方案。
生成性对抗网络 - GAN
生成对抗网络是深度神经网络,包括两个网络,一个相对于另一个网格,因此是“对抗性”名称。
2014年,蒙特利尔大学的研究人员发表了一篇论文,介绍了GAN.Facebook的人工智能专家Yann LeCun在谈到GAN时称,对抗性训练是“过去10年ML中最有趣的想法”。
GAN的潜力巨大,因为网络扫描学会模仿任何数据分布。 可以教导GAN创建与我们在任何领域惊人相似的平行世界:图像,音乐,演讲,散文。 他们在某种程度上是机器人艺术家,他们的作品令人印象深刻。
在GAN中,一个神经网络(称为生成器)生成新的数据实例,而另一个神经网络(鉴别器)评估它们的真实性。
让我们说我们正在尝试生成手写的数字,就像在MNIST数据集中找到的数字一样,它取自现实世界。 当从真实的MNIST数据集中显示实例时,鉴别器的工作是将它们识别为真实的。
现在考虑GAN的以下步骤 -
生成器网络以随机数的形式获取输入并返回图像。
该生成的图像作为输入提供给鉴别器网络以及从实际数据集中获取的图像流。
鉴别器接收真实和假图像并返回概率,0到1之间的数字,1表示真实性的预测,0表示假。
所以你有一个双反馈循环 -
鉴别器处于反馈循环中,具有图像的基本事实,我们知道这一点。
发生器与鉴别器一起处于反馈回路中。
递归神经网络 - RNN
RNN Sare神经网络,数据可以在任何方向上流动。 这些网络用于语言建模或自然语言处理(NLP)等应用程序。
RNN的基本概念是利用顺序信息。 在正常的神经网络中,假设所有输入和输出彼此独立。 如果我们想要预测句子中的下一个单词,我们必须知道在它之前出现了哪些单词。
RNN被称为循环,因为它们对序列的每个元素重复相同的任务,输出基于先前的计算。 因此可以说RNN具有“存储器”,其捕获关于先前已经计算的信息。 从理论上讲,RNN可以在很长的序列中使用信息,但实际上,它们只能回顾几个步骤。
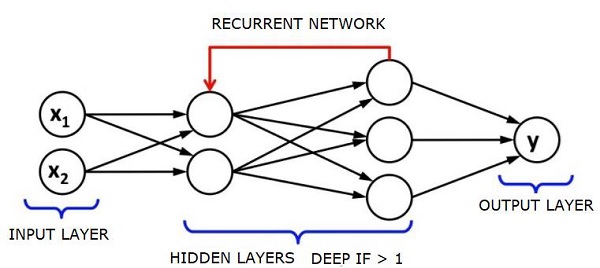
长期短期记忆网络(LSTM)是最常用的RNN。
与卷积神经网络一起,RNN已被用作模型的一部分,以生成未标记图像的描述。 令人惊讶的是,这看起来有多好。
卷积深度神经网络 - CNN
如果我们增加神经网络中的层数以使其更深,则会增加网络的复杂性,并允许我们对更复杂的函数进行建模。 但是,权重和偏差的数量将呈指数增长。 事实上,对于正常的神经网络来说,学习这些难题是不可能的。 这导致了解决方案,即卷积神经网络。
CNN广泛用于计算机视觉; 已经应用于自动语音识别的声学建模中。
卷积神经网络背后的想法是通过图像的“移动滤波器”的想法。 该移动滤波器或卷积适用于某些节点邻域,例如可能是像素,其中所应用的滤波器是节点值的0.5倍 -
着名研究员Yann LeCun开创了卷积神经网络。 Facebook作为面部识别软件使用这些网络。 CNN一直致力于机器视觉项目的解决方案。 卷积网络有很多层。 在Imagenet的挑战中,一台机器在2015年能够在物体识别中击败人类。
简而言之,卷积神经网络(CNN)是多层神经网络。 这些层有时最多为17或更多,并假设输入数据为图像。
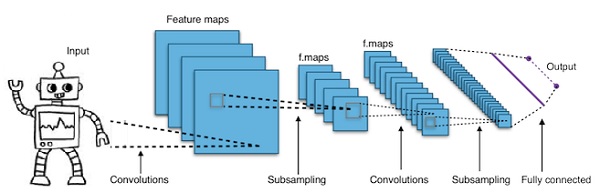
CNN大大减少了需要调整的参数数量。 因此,CNN有效地处理原始图像的高维度。
Python Deep Learning - Fundamentals
在本章中,我们将研究Python深度学习的基础知识。
深度学习模型/算法
现在让我们了解不同的深度学习模型/算法。
深度学习中的一些流行模型如下 -
- 卷积神经网络
- 循环神经网络
- 深刻的信念网络
- 生成对抗性网络
- Auto-encoders and so on
输入和输出表示为向量或张量。 例如,神经网络可以具有输入,其中图像中的各个像素RGB值被表示为矢量。
位于输入层和输出层之间的神经元层称为隐藏层。 这是大多数工作在神经网络试图解决问题时发生的地方。 仔细研究隐藏层可以揭示网络学习从数据中提取的功能。
通过选择哪个神经元连接到下一层中的其他神经元来形成神经网络的不同架构。
用于计算输出的伪代码
以下是用于计算Forward-propagating Neural Network输出的伪码 -
- #node []:=拓扑排序节点的数组
- #从a到b的边表示a在b的左边
- #如果神经网络有R输入和S输出,
- #然后,第一个R节点是输入节点,最后一个S节点是输出节点。
- #incoming [x]:=连接到节点x的节点
- #weight [x]:=传入边缘的权重为x
对于每个神经元x,从左到右 -
- 如果x <= R:什么都不做#它是一个输入节点
- 输入[x] = [输入[i]为输入[x]中的i]
- weighted_sum = dot_product(weights [x],inputs [x])
- output [x] = Activation_function(weighted_sum)
Training a Neural Network
我们现在将学习如何训练神经网络。 我们还将学习Python深度学习中的反向传播算法和反向传递。
我们必须找到神经网络权重的最佳值,以获得所需的输出。 为了训练神经网络,我们使用迭代梯度下降法。 我们最初从权重的随机初始化开始。 在随机初始化之后,我们使用前向传播过程对数据的某个子集进行预测,计算相应的成本函数C,并将每个权重w更新为与dC/dw成比例的量,即成本函数的导数。重量。 比例常数称为学习率。
可以使用反向传播算法有效地计算梯度。 向后传播或反向传播的关键观察是,由于分化的链规则,神经网络中每个神经元的梯度可以使用神经元的梯度来计算,它具有向外的边缘。 因此,我们向后计算梯度,即首先计算输出层的梯度,然后计算最顶层的隐藏层,然后是前面的隐藏层,依此类推,以输入层结束。
反向传播算法主要使用计算图的思想来实现,其中每个神经元被扩展到计算图中的许多节点并执行诸如加法,乘法之类的简单数学运算。 计算图在边缘上没有任何权重; 所有权重都分配给节点,因此权重成为它们自己的节点。 然后在计算图上运行后向传播算法。 计算完成后,只需要权重节点的梯度进行更新。 其余的梯度可以丢弃。
梯度下降优化技术
一种常用的优化函数根据它们引起的误差调整权重,称为“梯度下降”。
渐变是斜率的另一个名称,斜率在xy图上表示两个变量如何相互关联:运行时的上升,距离随时间变化的变化等。在这种情况下,斜率是网络错误与单一权重之间的比率; 也就是说,当重量变化时,误差如何变化。
更准确地说,我们希望找到哪个权重产生的误差最小。 我们希望找到正确表示输入数据中包含的信号的权重,并将它们转换为正确的分类。
当神经网络学习时,它会慢慢调整许多权重,以便它们可以正确地将信号映射到意义。 网络误差与每个权重之间的比率是导数dE/dw,它计算重量轻微变化导致误差轻微变化的程度。
每个权重只是涉及许多变换的深层网络中的一个因素; 权重的信号通过激活并在多个层上求和,因此我们使用微积分的链规则通过网络激活和输出来回溯。这导致我们所讨论的权重及其与总体误差的关系。
给定两个变量,即误差和重量,由第三个变量activation ,通过该变量传递权重。 我们可以通过首先计算激活变化如何影响误差变化,以及体重变化如何影响激活变化来计算体重变化如何影响误差变化。
深度学习的基本思想仅仅是:调整模型的权重以响应它产生的错误,直到你不能再减少错误为止。
如果梯度值很小则深网络缓慢训练,如果值很高则深度训练。 训练中的任何不准确都会导致输出不准确。 从输出回到输入的网络训练过程称为反向传播或反向传播。 我们知道前向传播从输入开始并向前发展。 后支撑反向/反向计算从右到左的梯度。
每次我们计算一个渐变时,我们都会使用之前的所有渐变。
让我们从输出层中的一个节点开始。 边使用该节点处的渐变。 当我们回到隐藏层时,它变得更加复杂。 两个数字在0和1之间的乘积给出了较小的数字。 渐变值不断变小,因此后支撑需要花费大量时间进行训练并且精度受到影响。
深度学习算法面临的挑战
浅层神经网络和深度神经网络都存在一些挑战,如过度拟合和计算时间。 DNN受到过度拟合的影响,因为使用了额外的抽象层,这使得它们可以对训练数据中的罕见依赖关系进行建模。
在训练期间应用诸如辍学,早期停止,数据增强,转移学习等Regularization方法来对抗过度拟合。 退出正则化在训练期间随机省略隐藏层中的单元,这有助于避免罕见的依赖性。 DNN考虑了几个训练参数,例如大小,即层数和每层单位数,学习率和初始权重。 由于时间和计算资源的高成本,寻找最佳参数并不总是实用的。 诸如批处理之类的几个黑客可以加速计算。 GPU的大处理能力极大地帮助了训练过程,因为所需的矩阵和向量计算在GPU上得到了很好的执行。
Dropout
Dropout是一种流行的神经网络正则化技术。 深度神经网络特别容易过度拟合。
现在让我们看看辍学是什么以及它是如何运作的。
用深度学习的先驱之一杰弗里·辛顿(Geoffrey Hinton)的话来说,“如果你有一个深度神经网络并且它不会过度拟合,你应该使用更大的一个并使用辍学”。
Dropout是一种技术,在每次梯度下降迭代期间,我们删除一组随机选择的节点。 这意味着我们随机忽略一些节点,就好像它们不存在一样。
每个神经元保持q的概率并随机地以概率1-q下降。 对于神经网络中的每个层,值q可以是不同的。 隐藏层的值为0.5,输入层的值为0,适用于各种任务。
在评估和预测期间,不使用丢失。 每个神经元的输出乘以q,以便下一层的输入具有相同的预期值。
Dropout背后的想法如下 - 在没有退出正则化的神经网络中,神经元在彼此之间产生共同依赖性,导致过度拟合。
实施技巧
通过将随机选择的神经元的输出保持为0,在诸如TensorFlow和Pytorch的库中实现丢失。即,虽然神经元存在,但其输出被覆盖为0。
提前停止
我们使用称为梯度下降的迭代算法训练神经网络。
早期停止背后的想法是直观的; 当错误开始增加时我们停止训练。 这里,错误是指在验证数据上测量的误差,验证数据是用于调整超参数的训练数据的一部分。 在这种情况下,超参数是停止标准。
数据扩充
我们通过使用现有数据并对其应用一些转换来增加数据量或增加数据量的过程。 使用的确切转换取决于我们打算实现的任务。 而且,帮助神经网络的转换依赖于它的架构。
例如,在诸如对象分类的许多计算机视觉任务中,有效的数据增强技术是添加作为原始数据的裁剪或翻译版本的新数据点。
当计算机接受图像作为输入时,它会接收像素值数组。 让我们说整个图像向左移动15个像素。 我们在不同方向上应用了许多不同的移位,从而产生了比原始数据集大许多倍的扩充数据集。
转学习
采用预训练模型并使用我们自己的数据集“微调”模型的过程称为转移学习。 有几种方法可以做到这一点。下面介绍几种方法 -
我们在大型数据集上训练预训练模型。 然后,我们删除网络的最后一层,并用一个随机权重的新图层替换它。
然后我们冻结所有其他层的权重并正常训练网络。 这里冻结层不会在梯度下降或优化期间改变权重。
这背后的概念是预训练的模型将作为特征提取器,并且只有最后一层将被训练当前任务。
Computational Graphs
反向传播通过使用计算图在Tensorflow,Torch,Theano等深度学习框架中实现。 更重要的是,理解计算图上的反向传播结合了几种不同的算法及其变体,例如通过时间的backprop和具有共享权重的backprop。 一旦将所有内容转换为计算图,它们仍然是相同的算法 - 只是在计算图上反向传播。
什么是计算图
计算图被定义为有向图,其中节点对应于数学运算。 计算图是表达和评估数学表达式的一种方式。
例如,这是一个简单的数学方程式 -
$$p = x+y$$
我们可以如下绘制上述等式的计算图。
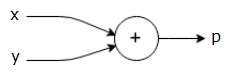
上述计算图具有加法节点(具有“+”符号的节点),其具有两个输入变量x和y以及一个输出q。
让我们再举一个例子,稍微复杂一些。 我们有以下等式。
$$g = \left (x+y \right ) \ast z $$
上述等式由以下计算图表示。
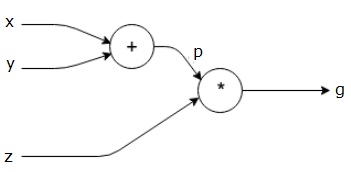
计算图和反向传播
计算图和反向传播都是深度学习训练神经网络的重要核心概念。
前进通行证
前向传递是用于评估由计算图表示的数学表达式的值的过程。 执行正向传递意味着我们将变量的值从左(输入)向前传递到输出所在的右侧。
让我们通过给所有输入赋予一些价值来考虑一个例子。 假设,所有输入都给出以下值。
$$x=1, y=3, z=−3$$
通过将这些值赋给输入,我们可以执行正向传递并为每个节点上的输出获取以下值。
首先,我们使用x = 1和y = 3的值,得到p = 4。
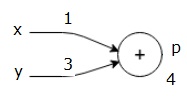
然后我们使用p = 4和z = -3来得到g = -12。 我们从左到右前进。
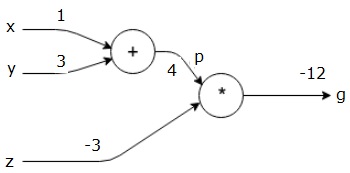
落后目标
在向后传递中,我们的目的是计算每个输入相对于最终输出的梯度。 这些梯度对于使用梯度下降训练神经网络至关重要。
例如,我们需要以下渐变。
期望的渐变
$$\frac{\partial x}{\partial f}, \frac{\partial y}{\partial f}, \frac{\partial z}{\partial f}$$
Backward pass (backpropagation)
我们通过找到最终输出相对于最终输出(本身!)的导数来开始向后传递。 因此,它将导致身份派生,并且该值等于1。
$$\frac{\partial g}{\partial g} = 1$$
我们的计算图现在看起来如下所示 -
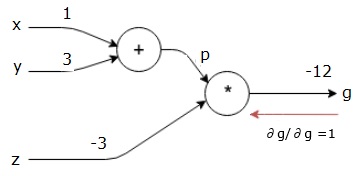
接下来,我们将执行向后传递“*”操作。 我们将计算p和z处的梯度。 由于g = p * z,我们知道 -
$$\frac{\partial g}{\partial z} = p$$
$$\frac{\partial g}{\partial p} = z$$
我们已经知道了前向传球中z和p的值。 因此,我们得到 -
$$\frac{\partial g}{\partial z} = p = 4$$
和
$$\frac{\partial g}{\partial p} = z = -3$$
我们想要计算x和y处的梯度 -
$$\frac{\partial g}{\partial x}, \frac{\partial g}{\partial y}$$
但是,我们希望有效地做到这一点(尽管在此图中x和g只有两跳,想象它们彼此相距很远)。 为了有效地计算这些值,我们将使用区分链规则。 从连锁规则来看,我们有 -
$$\frac{\partial g}{\partial x}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial x}$$
$$\frac{\partial g}{\partial y}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial y}$$
但我们已经知道dg/dp = -3,dp/dx和dp/dy很容易,因为p直接取决于x和y。 我们有 -
$$p=x+y\Rightarrow \frac{\partial x}{\partial p} = 1, \frac{\partial y}{\partial p} = 1$$
因此,我们得到 -
$$\frac{\partial g} {\partial f} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial x} = \left ( -3 \right ).1 = -3$$
另外,对于输入y -
$$\frac{\partial g} {\partial y} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial y} = \left ( -3 \right ).1 = -3$$
向后执行此操作的主要原因是,当我们必须计算x处的梯度时,我们仅使用已计算的值和dq/dx(节点输出相对于同一节点输入的导数)。 我们使用本地信息来计算全球价值。
训练神经网络的步骤
按照以下步骤训练神经网络 -
对于数据集中的数据点x,我们使用x作为输入进行正向传递,并将成本c计算为输出。
我们从c开始向后传递,并计算图中所有节点的渐变。 这包括表示神经网络权重的节点。
然后我们通过W = W-学习率*梯度来更新权重。
我们重复此过程,直到满足停止标准。
Python Deep Learning - Applications
深度学习为一些应用产生了良好的效果,如计算机视觉,语言翻译,图像字幕,音频转录,分子生物学,语音识别,自然语言处理,自动驾驶汽车,脑肿瘤检测,实时语音翻译,音乐构图,自动游戏等。
深度学习是机器学习之后的下一个重大飞跃,具有更高级的实施。 目前,它正朝着成为行业标准的方向发展,在处理原始非结构化数据时带来了改变游戏规则的强烈希望。
深度学习目前是解决各种现实问题的最佳解决方案提供商之一。 开发人员正在构建AI程序,而不是使用以前给定的规则,从示例中学习以解决复杂的任务。 随着许多数据科学家使用深度学习,更深层的神经网络正在提供更加准确的结果。
我们的想法是通过增加每个网络的训练层数来开发深度神经网络; 机器学习更多关于数据的知识,直到它尽可能准确。 开发人员可以使用深度学习技术来实现复杂的机器学习任务,并培训AI网络以获得高水平的感知识别。
深度学习在计算机视觉中得到了普及。 这里实现的任务之一是图像分类,其中给定的输入图像被分类为猫,狗等,或者作为最佳描述图像的类或标签。 我们作为人类在我们的生活中很早就学会了如何完成这项任务,并具备快速识别模式,从先前知识推广和适应不同图像环境的这些技能。
Libraries and Frameworks
在本章中,我们将深度学习与不同的库和框架联系起来。
深度学习和Theano
如果我们想要开始编码深度神经网络,我们最好知道不同的框架如Theano,TensorFlow,Keras,PyTorch等是如何工作的。
Theano是python库,它提供了一系列功能,用于构建可在我们的机器上快速训练的深网。
Theano是在加拿大蒙特利尔大学开发的,由Yoshua Bengio领导,是一个深厚的网络先驱。
Theano让我们用矢量和矩阵定义和评估数学表达式,这些矩阵是矩形数组。
从技术上讲,神经网络和输入数据都可以表示为矩阵,所有标准网络操作都可以重新定义为矩阵运算。 这很重要,因为计算机可以非常快速地执行矩阵运算。
我们可以并行处理多个矩阵值,如果我们构建一个具有这种底层结构的神经网络,我们可以使用一台带有GPU的机器在合理的时间窗口内训练大量的网络。
但是,如果我们使用Theano,我们必须从头开始构建深网。 该库不提供用于创建特定类型的深网的完整功能。
相反,我们必须编码深层网的每个方面,如模型,图层,激活,训练方法和任何特殊方法来停止过度拟合。
然而,好消息是Theano允许在矢量化功能的顶部构建我们的实现,为我们提供高度优化的解决方案。
还有许多其他库扩展了Theano的功能。 TensorFlow和Keras可以与Theano一起用作后端。
使用TensorFlow进行深度学习
Googles TensorFlow是一个python库。 该库是构建商业级深度学习应用程序的绝佳选择。
TensorFlow来自另一个图书馆DistBelief V2,它是Google Brain Project的一部分。 该库旨在扩展机器学习的可移植性,以便研究模型可以应用于商业级应用程序。
与Theano库非常相似,TensorFlow基于计算图,其中节点表示持久数据或数学运算,边表示节点之间的数据流,这是一个多维数组或张量; 因此称为TensorFlow
来自一个操作或一组操作的输出作为输入馈送到下一个操作。
尽管TensorFlow是为神经网络设计的,但它适用于其他网络,其中计算可以建模为数据流图。
TensorFlow还使用了Theano的一些功能,例如常见和子表达式消除,自动区分,共享和符号变量。
可以使用TensorFlow构建不同类型的深网,如卷积网,自动编码器,RNTN,RNN,RBM,DBM/MLP等。
但是,TensorFlow中不支持超参数配置。对于此功能,我们可以使用Keras。
与Keras深度学习
Keras是一个功能强大且易于使用的Python库,用于开发和评估深度学习模型。
它采用简约设计,允许我们逐层构建网络; 训练它,并运行它。
它包含了高效的数值计算库Theano和TensorFlow,并允许我们在几行代码中定义和训练神经网络模型。
它是一个高级神经网络API,有助于广泛使用深度学习和人工智能。 它运行在许多较低级别的库之上,包括TensorFlow,Theano等。 Keras代码是便携式的; 我们可以使用Theano或TensorFlow在Keras中实现神经网络作为后端而不需要对代码进行任何更改。
Python Deep Learning - Implementations
在深度学习的实施中,我们的目标是预测某个银行的客户流失或流失数据 - 客户可能会离开此银行服务。 使用的数据集相对较小,包含10000行,14列。 我们正在使用Anaconda发行版,以及Theano,TensorFlow和Keras等框架。 Keras建立在Tensorflow和Theano之上,后者作为其后端。
# Artificial Neural Network
# Installing Theano
pip install --upgrade theano
# Installing Tensorflow
pip install –upgrade tensorflow
# Installing Keras
pip install --upgrade keras
第1步:数据预处理
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')
Step 2
我们创建数据集和目标变量的特征矩阵,即第14列,标记为“已退出”。
数据的初始外观如下所示 -
In[]:
X = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
X
输出 (Output)
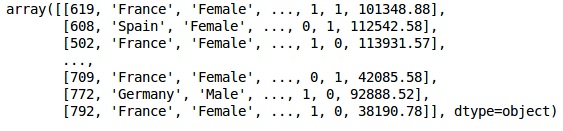
Step 3
Y
输出 (Output)
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)
Step 4
我们通过编码字符串变量使分析更简单。 我们使用ScikitLearn函数'LabelEncoder'自动编码列中不同的标签,其值介于0到n_classes-1之间。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:,1] = labelencoder_X_1.fit_transform(X[:,1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
X
输出 (Output)
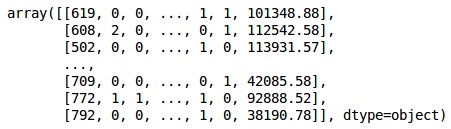
在上面的输出中,国家名称被替换为0,1和2; 男性和女性被0和1取代。
Step 5
Labelling Encoded Data
我们使用相同的ScikitLearn库和另一个名为OneHotEncoder函数来传递创建虚拟变量的列号。
onehotencoder = OneHotEncoder(categorical features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
X
现在,前2列代表国家,第4列代表性别。
输出 (Output)
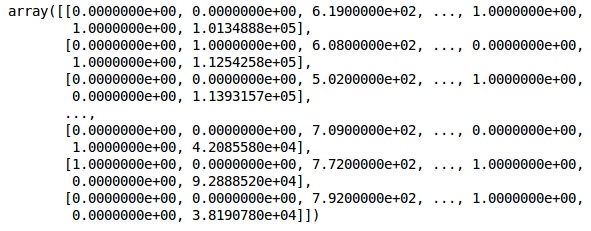
我们总是将数据划分为培训和测试部分; 我们在训练数据上训练我们的模型,然后检查模型在测试数据上的准确性,这有助于评估模型的效率。
Step 6
我们使用ScikitLearn的train_test_split函数将我们的数据分成训练集和测试集。 我们将列车 - 测试分流比保持在80:20。
#Splitting the dataset into the Training set and the Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
一些变量的值为千,而一些变量的值为十或一。 我们扩展数据以使它们更具代表性。
Step 7
在此代码中,我们使用StandardScaler函数拟合和转换训练数据。 我们标准化我们的缩放比例,以便我们使用相同的拟合方法来转换/缩放测试数据。
# Feature Scaling
fromsklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
输出 (Output)
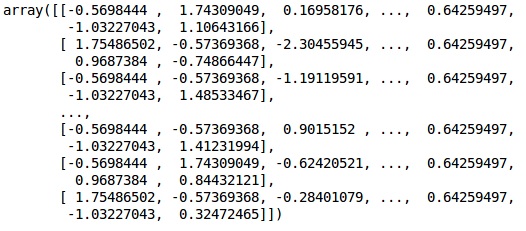
现在可以正确缩放数据。 最后,我们完成了数据预处理。 现在,我们将从我们的模型开始。
Step 8
我们在这里导入所需的模块。 我们需要Sequential模块来初始化神经网络,而密集模块则需要添加隐藏层。
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Dense
Step 9
我们将该模型命名为Classifier,因为我们的目标是对客户流失进行分类。 然后我们使用Sequential模块进行初始化。
#Initializing Neural Network
classifier = Sequential()
第10步
我们使用密集函数逐个添加隐藏层。 在下面的代码中,我们将看到许多参数。
我们的第一个参数是output_dim 。 它是我们添加到该层的节点数。 init是Stochastic Gradient Decent的初始化。 在神经网络中,我们为每个节点分配权重。 在初始化时,权重应接近零,我们使用统一函数随机初始化权重。 input_dim参数仅适用于第一层,因为模型不知道输入变量的数量。 这里输入变量的总数是11.在第二层中,模型自动知道来自第一个隐藏层的输入变量的数量。
执行以下代码行来添加输入图层和第一个隐藏图层 -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu', input_dim = 11))
执行以下代码行添加第二个隐藏层 -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu'))
执行以下代码行来添加输出层 -
classifier.add(Dense(units = 1, kernel_initializer = 'uniform',
activation = 'sigmoid'))
第11步
Compiling the ANN
到目前为止,我们已经为分类器添加了多个图层。 我们现在将使用compile方法编译它们。 在最终编译控件中添加的参数完成了神经网络。因此,我们需要在此步骤中小心。
以下是对这些论点的简要解释。
第一个参数是Optimizer 。这是一个用于查找最佳权重集的算法。 该算法称为Stochastic Gradient Descent (SGD) 。 在这里,我们使用了几种类型中的一种,称为“亚当优化器”。 新元取决于损失,因此我们的第二个参数是损失。 如果我们的因变量是二进制的,我们使用称为'binary_crossentropy'对数损失函数,如果我们的因变量在输出中有两个以上的类别,那么我们使用'categorical_crossentropy' 。 我们希望基于accuracy来提高神经网络的性能,因此我们将metrics添加为准确性。
# Compiling Neural Network
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
第12步
在此步骤中需要执行许多代码。
将ANN安装到训练集
我们现在在训练数据上训练我们的模型。 我们使用fit方法来拟合我们的模型。 我们还优化了重量以提高模型效率。 为此,我们必须更新权重。 Batch size是我们更新权重之后的观察数量。 Epoch是迭代的总数。 批量大小和时期的值通过试错法选择。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)
进行预测并评估模型
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
预测一个新的观察
# Predicting a single new observation
"""Our goal is to predict if the customer with the following data will leave the bank:
Geography: Spain
Credit Score: 500
Gender: Female
Age: 40
Tenure: 3
Balance: 50000
Number of Products: 2
Has Credit Card: Yes
Is Active Member: Yes
第13步
Predicting the test set result
预测结果将为您提供客户离开公司的概率。 我们将该概率转换为二进制0和1。
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
new_prediction = classifier.predict(sc.transform
(np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]])))
new_prediction = (new_prediction > 0.5)
第14步
这是我们评估模型性能的最后一步。 我们已经有了原始结果,因此我们可以构建混淆矩阵来检查模型的准确性。
Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print (cm)
输出 (Output)
loss: 0.3384 acc: 0.8605
[ [1541 54]
[230 175] ]
从混淆矩阵中,我们模型的精度可以计算为 -
Accuracy = 1541+175/2000=0.858
We achieved 85.8% accuracy ,这很好。
前向传播算法
在本节中,我们将学习如何编写代码来进行简单神经网络的前向传播(预测) -
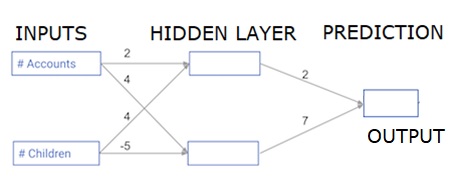
每个数据点都是客户。 第一个输入是他们有多少个帐户,第二个输入是他们有多少个孩子。 该模型将预测用户在明年进行的交易数量。
输入数据被预加载为输入数据,并且权重在称为权重的字典中。 隐藏层中第一个节点的权重数组为权重['node_0'],隐藏层中第二个节点的权重数据分别为权重['node_1']。
馈入输出节点的权重可用于权重。
整流线性激活函数
“激活功能”是在每个节点上工作的功能。 它将节点的输入转换为某个输出。
经过整流的线性激活功能(称为ReLU )广泛用于非常高性能的网络中。 此函数将单个数字作为输入,如果输入为负,则返回0;如果输入为正,则输入为输出。
以下是一些例子 -
- relu(4)= 4
- relu(-2)= 0
我们填写relu()函数的定义 -
- 我们使用max()函数计算relu()输出的值。
- 我们将relu()函数应用于node_0_input以计算node_0_output。
- 我们将relu()函数应用于node_1_input以计算node_1_output。
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model output
输出 (Output)
0.9950547536867305
-3
将网络应用于许多观察/行数据
在本节中,我们将学习如何定义名为predict_with_network()的函数。 此函数将生成多个数据观测的预测,从上面的网络中获取input_data。 正在使用上述网络中给出的权重。 还使用了relu()函数定义。
让我们定义一个名为predict_with_network()的函数,它接受两个参数 - input_data_row和weights - 并从网络返回一个预测作为输出。
我们计算每个节点的输入和输出值,将它们存储为:node_0_input,node_0_output,node_1_input和node_1_output。
要计算节点的输入值,我们将相关数组相乘并计算它们的总和。
要计算节点的输出值,我们将relu()函数应用于节点的输入值。 我们使用'for循环'来迭代input_data -
我们还使用predict_with_network()为input_data的每一行生成预测 - input_data_row。 我们还将每个预测附加到结果中。
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs*weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
print(results)# Print results
输出 (Output)
[0, 12]
深层多层神经网络
在这里,我们编写代码来为具有两个隐藏层的神经网络进行前向传播。 每个隐藏层都有两个节点。 输入数据已预先加载为input_data 。 第一个隐藏层中的节点称为node_0_0和node_0_1。
它们的权重分别作为权重['node_0_0']和权重['node_0_1']预先加载。
第二个隐藏层中的节点称为node_1_0 and node_1_1 。 它们的权重分别作为weights['node_1_0']和weights['node_1_1']预先加载。
然后,我们使用预加载为weights['output']从隐藏节点创建模型输出。
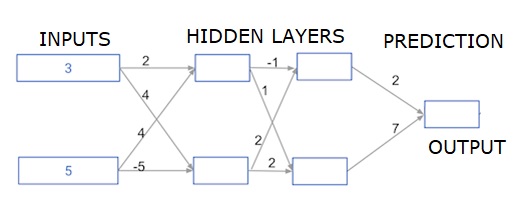
我们使用权重权重['node_0_0']和给定的input_data来计算node_0_0_input。 然后应用relu()函数获取node_0_0_output。
我们对node_0_1_input执行与上面相同的操作以获取node_0_1_output。
我们使用权重权重['node_1_0']和第一个隐藏层的输出 - hidden_0_outputs来计算node_1_0_input。 然后我们应用relu()函数来获取node_1_0_output。
我们对node_1_1_input执行与上述相同的操作以获取node_1_1_output。
我们使用权重['output']和第二个隐藏层hidden_1_outputs数组的输出计算model_output。 我们不将relu()函数应用于此输出。
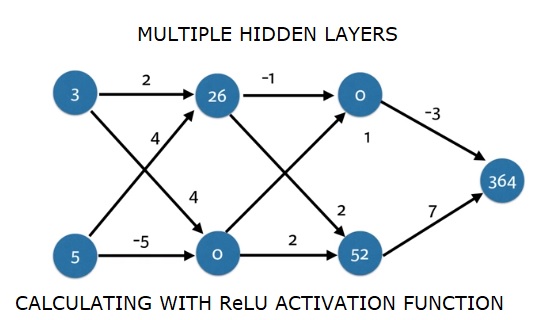
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)
输出 (Output)
364
