Seaborn - 统计估计( Statistical Estimation)
在大多数情况下,我们处理数据整体分布的估计。 但是当涉及到集中趋势估计时,我们需要一种特定的方式来总结分布。 平均值和中值是常用的估计分布集中趋势的技术。
在我们在上一节中学到的所有图中,我们对整个分布进行了可视化。 现在,让我们讨论一下我们可以用来估计分布集中趋势的图。
酒吧情节
barplot()显示分类变量和连续变量之间的关系。 数据以矩形条表示,条形的长度表示该类别中数据的比例。
条形图表示集中趋势的估计。 让我们使用'泰坦尼克'数据集来学习条形图。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
输出 (Output)
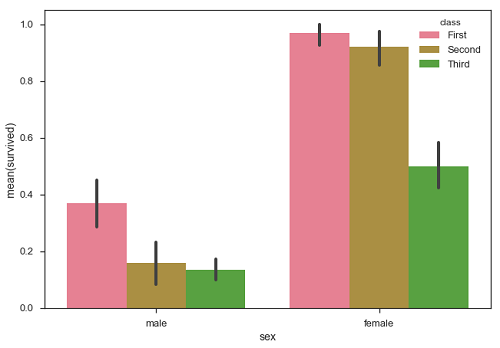
在上面的例子中,我们可以看到每个class中男性和女性的平均幸存数。 从情节我们可以理解,存活的男性比男性更多。 在男性和女性中,更多的幸存者来自头等舱。
条形图中的一个特例是显示每个类别中的观察结果,而不是计算第二个变量的统计数据。 为此,我们使用countplot().
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()
输出 (Output)
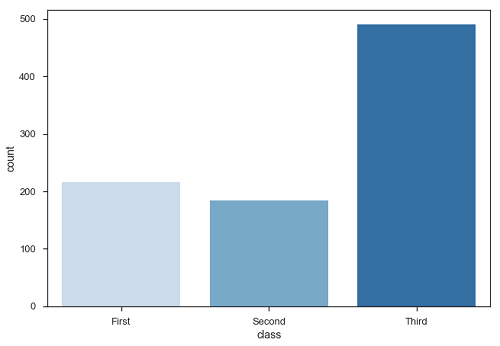
Plot说,三等舱的乘客数量高于一等舱和二等舱。
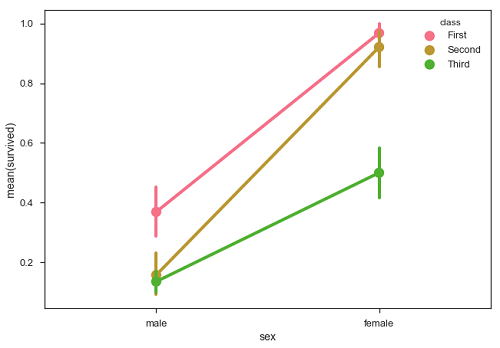
点图
点图与条形图相同,但风格不同。 而不是完整条,估计值由另一轴上某个高度处的点表示。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
输出 (Output)