Seaborn - 快速指南
Seaborn - Introduction
在Google Analytics(分析)领域,获得洞察力的最佳方式是通过可视化数据。 可以通过将数据表示为易于理解,探索和掌握的图来可视化数据。 这些数据有助于吸引关键要素的注意力。
为了使用Python分析一组数据,我们使用了Matplotlib,这是一个广泛实现的2D绘图库。 同样,Seaborn是Python中的可视化库。 它建立在Matplotlib之上。
Seaborn与Matplotlib
总结一下,如果Matplotlib“试图让事情变得轻松而艰难,那么Seaborn也试图让一套定义明确的事情变得容易。”
Seaborn有助于解决Matplotlib面临的两个主要问题; 问题是 -
- 默认的Matplotlib参数
- 使用数据框架
随着Seaborn对Matplotlib的称赞和扩展,学习曲线非常渐进。 如果你知道Matplotlib,你已经在Seaborn的中途了。
Seaborn的重要特征
Seaborn构建于Python的核心可视化库Matplotlib之上。 它旨在作为补充,而不是替代。 然而,Seaborn带有一些非常重要的功能。 我们在这里看一些。 这些功能有助于 -
- 内置主题的样式matplotlib图形
- 可视化单变量和双变量数据
- 拟合并可视化线性回归模型
- 绘制统计时间序列数据
- Seaborn与NumPy和Pandas数据结构配合良好
- 它内置了Matplotlib图形样式的主题
在大多数情况下,您仍然可以使用Matplotlib进行简单的绘图。 建议使用Matplotlib的知识来调整Seaborn的默认图。
Seaborn - Environment Setup
在本章中,我们将讨论Seaborn的环境设置。 让我们从安装开始,了解如何在我们前进的过程中开始。
安装Seaborn并开始使用
在本节中,我们将了解安装Seaborn所涉及的步骤。
使用Pip安装程序
要安装最新版本的Seaborn,你可以使用pip -
pip install seaborn
适用于使用Anaconda的Windows,Linux和Mac
Anaconda(来自https://www.anaconda.com/是SciPy堆栈的免费Python发行版。它也适用于Linux和Mac。
也可以使用conda安装发布的版本 -
conda install seaborn
直接从github安装Seaborn的开发版本
https://github.com/mwaskom/seaborn"
依赖关系(Dependencies)
考虑一下Seaborn的以下依赖关系 -
- Python 2.7或3.4+
- numpy
- scipy
- pandas
- matplotlib
Seaborn - Importing Datasets and Libraries
在本章中,我们将讨论如何导入数据集和库。 让我们首先了解如何导入库。
导入库
让我们从导入Pandas开始,Pandas是一个用于管理关系(表格式)数据集的优秀库。 Seaborn在处理DataFrames时非常方便,DataFrames是用于数据分析的最广泛使用的数据结构。
以下命令将帮助您导入Pandas -
# Pandas for managing datasets
import pandas as pd
现在,让我们导入Matplotlib库,它可以帮助我们自定义绘图。
# Matplotlib for additional customization
from matplotlib import pyplot as plt
我们将使用以下命令导入Seaborn库 -
# Seaborn for plotting and styling
import seaborn as sb
导入数据集
我们已导入所需的库。 在本节中,我们将了解如何导入所需的数据集。
Seaborn在库中附带了一些重要的数据集。 安装Seaborn时,数据集会自动下载。
您可以使用这些数据集中的任何一个来学习。 借助以下功能,您可以加载所需的数据集
load_dataset()
将数据导入为Pandas DataFrame
在本节中,我们将导入数据集。 默认情况下,此数据集作为Pandas DataFrame加载。 如果Pandas DataFrame中有任何函数,则它适用于此DataFrame。
以下代码行将帮助您导入数据集 -
# Seaborn for plotting and styling
import seaborn as sb
df = sb.load_dataset('tips')
print df.head()
上面的代码行将生成以下输出 -
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
要查看Seaborn库中的所有可用数据集,可以使用以下命令和get_dataset_names()函数,如下所示 -
import seaborn as sb
print sb.get_dataset_names()
上面的代码行将返回可用的数据集列表,如下所示
[u'anscombe', u'attention', u'brain_networks', u'car_crashes', u'dots',
u'exercise', u'flights', u'fmri', u'gammas', u'iris', u'planets', u'tips',
u'titanic']
DataFrames以矩形网格的形式存储数据,通过它可以轻松地查看数据。 矩形网格的每一行包含实例的值,并且网格的每一列是保存特定变量的数据的向量。 这意味着DataFrame的行不需要包含相同数据类型的值,它们可以是数字,字符,逻辑等。用于Python的DataFrames带有Pandas库,它们被定义为二维标记数据结构可能有不同类型的列。
有关DataFrames的更多详细信息,请访问我们的pandas tutorial 。
Seaborn - Figure Aesthetic
可视化数据是一步,进一步使可视化数据更令人愉悦是另一个步骤。 可视化在向观众传达量化见解以吸引他们的注意力方面起着至关重要的作用。
美学是指一系列与美的本质和欣赏有关的原则,特别是在艺术中。 可视化是一种以有效和最简单的方式表示数据的艺术。
Matplotlib库高度支持自定义,但知道要调整哪些设置来实现有吸引力和预期的情节是人们应该注意利用它。 与Matplotlib不同,Seaborn包含定制主题和高级界面,用于自定义和控制Matplotlib图形的外观。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
sinplot()
plt.show()
这是一个情节看起来如何使用默认值Matplotlib -
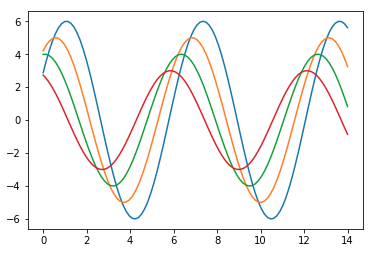
要将相同的绘图更改为Seaborn默认值,请使用set()函数 -
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set()
sinplot()
plt.show()
输出 (Output)
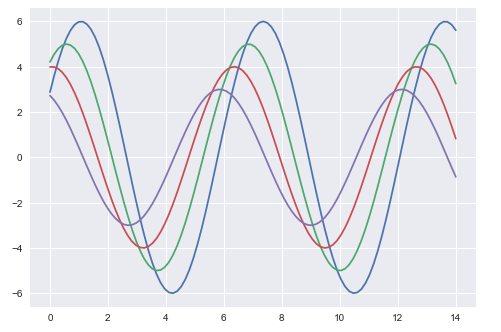
以上两个数字显示默认Matplotlib和Seaborn图的差异。 数据的表示是相同的,但表示风格在两者中都不同。
基本上,Seaborn将Matplotlib参数分成两组 -
- Plot styles
- Plot scale
Seaborn图样式
操作样式的界面是set_style() 。 使用此功能可以设置绘图的主题。 根据最新更新版本,以下是可用的五个主题。
- Darkgrid
- Whitegrid
- Dark
- White
- Ticks
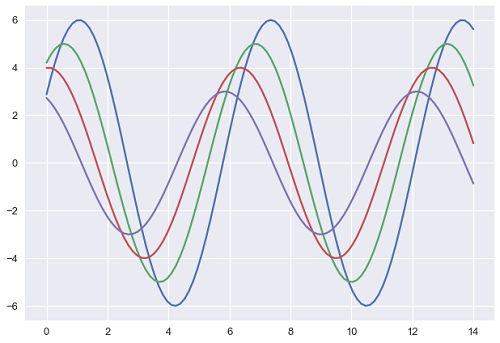
让我们尝试应用上述列表中的主题。 该图的默认主题是darkgrid ,我们在前面的例子中看到过。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()
输出 (Output)
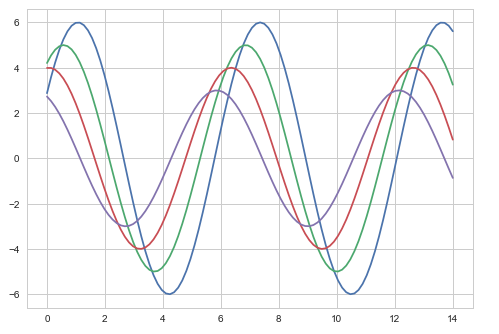
上述两个图之间的差异是背景颜色
去除轴刺
在白色和刻度主题中,我们可以使用despine()函数移除顶轴和右轴刺。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sinplot()
sb.despine()
plt.show()
输出 (Output)
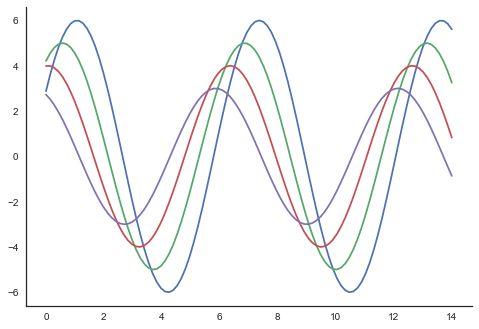
在常规图中,我们仅使用左轴和下轴。 使用despine()函数,我们可以避免不必要的右轴和顶轴刺,这在Matplotlib中是不受支持的。
覆盖元素
如果要自定义Seaborn样式,可以将参数字典传递给set_style()函数。 可用的参数使用axes_style()函数查看。
例子 (Example)
import seaborn as sb
print sb.axes_style
输出 (Output)
{'axes.axisbelow' : False,
'axes.edgecolor' : 'white',
'axes.facecolor' : '#EAEAF2',
'axes.grid' : True,
'axes.labelcolor' : '.15',
'axes.linewidth' : 0.0,
'figure.facecolor' : 'white',
'font.family' : [u'sans-serif'],
'font.sans-serif' : [u'Arial', u'Liberation
Sans', u'Bitstream Vera Sans', u'sans-serif'],
'grid.color' : 'white',
'grid.linestyle' : u'-',
'image.cmap' : u'Greys',
'legend.frameon' : False,
'legend.numpoints' : 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': u'round',
'text.color' : '.15',
'xtick.color' : '.15',
'xtick.direction' : u'out',
'xtick.major.size' : 0.0,
'xtick.minor.size' : 0.0,
'ytick.color' : '.15',
'ytick.direction' : u'out',
'ytick.major.size' : 0.0,
'ytick.minor.size' : 0.0}
更改任何参数的值将改变打印样式。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()
输出 (Output)
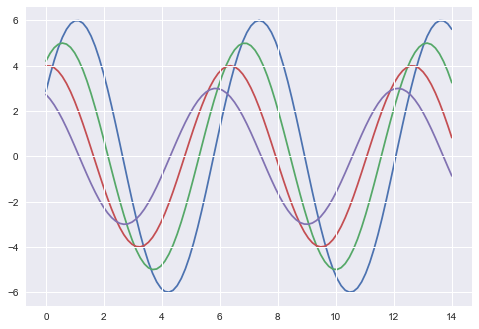
缩放绘图元素
我们还可以控制绘图元素,并可以使用set_context()函数控制绘图的比例。 我们有四个用于上下文的预设模板,基于相对大小,上下文命名如下
- Paper
- Notebook
- Talk
- Poster
默认情况下,上下文设置为notebook; 并用于上面的地块。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()
输出 (Output)
与上面的图相比,实际图的输出尺寸更大。
Note - 由于我们网页上的图像缩放,您可能会错过我们示例图中的实际差异。
Seaborn - Color Palette
颜色在可视化中起着比任何其他方面更重要的作用。 有效使用时,颜色为绘图增加了更多价值。 调色板是指平面,画家在其上排列和混合涂料。
建筑调色板
Seaborn提供了一个名为color_palette()的函数,可用于为图表添加颜色并为其添加更多美学价值。
用法 (Usage)
seaborn.color_palette(palette = None, n_colors = None, desat = None)
参数(Parameter)
下表列出了构建调色板的参数 -
| Sr.No. | Palatte&Description |
|---|---|
| 1 | n_colors 调色板中的颜色数。 如果为None,则默认值取决于指定调色板的方式。 默认情况下, n_colors值为6种颜色。 |
| 2 | desat 每种颜色去饱和的比例。 |
Return
返回指的是RGB元组列表。 以下是现成的Seaborn调色板 -
- Deep
- Muted
- Bright
- Pastel
- Dark
- Colorblind
除此之外,还可以生成新的调色板
在不知道数据特征的情况下,很难确定哪个调色板应该用于给定的数据集。 意识到这一点,我们将分类使用color_palette()类型的不同方法 -
- qualitative
- sequential
- diverging
我们有另一个功能seaborn.palplot()处理调色板。 此函数将调色板绘制为水平阵列。 在接下来的例子中,我们将更多地了解seaborn.palplot() 。
定性调色板
定性或分类调色板最适合绘制分类数据。
例子 (Example)
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(current_palette)
plt.show()
输出 (Output)
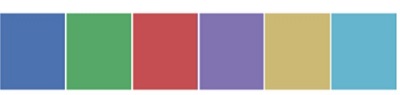
我们没有在color_palette();传递任何参数color_palette(); 默认情况下,我们看到6种颜色。 通过将值传递给n_colors参数,可以看到所需的颜色数。 这里, palplot()用于水平绘制颜色数组。
连续调色板
顺序图适合于表示从相对较低值到范围内的较高值的数据分布。
在传递给颜色参数的颜色上附加一个附加字符''将绘制顺序图。
例子 (Example)
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("Greens"))
plt.show()

Note −我们需要在上面的例子中将's'附加到像'Greens'这样的参数。
发散的调色板
不同的调色板使用两种不同的颜色。 每种颜色代表值的变化,范围从任一方向的公共点。
假设绘制范围从-1到1的数据。从-1到0的值采用一种颜色,0到+1采用另一种颜色。
默认情况下,值以零为中心。 您可以通过传递值来控制参数中心。
例子 (Example)
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("BrBG", 7))
plt.show()
输出 (Output)

设置默认调色板
函数color_palette()有一个名为set_palette()的伴侣。它们之间的关系类似于美学章节中涵盖的对。 set_palette()和color_palette(),的参数相同color_palette(),但默认的Matplotlib参数已更改,因此调色板用于所有绘图。
例子 (Example)
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
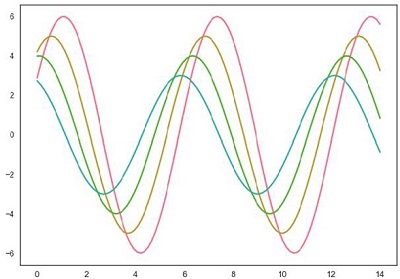
sb.set_palette("husl")
sinplot()
plt.show()
输出 (Output)
绘制单变量分布
在分析数据时,数据分布是我们需要了解的最重要的事情。 在这里,我们将看到seaborn如何帮助我们理解数据的单变量分布。
函数distplot()提供了一种快速查看单变量分布的最便捷方法。 此函数将绘制符合数据核密度估计的直方图。
用法 (Usage)
seaborn.distplot()
参数 (Parameters)
下表列出了参数及其说明 -
| Sr.No. | 参数和描述 |
|---|---|
| 1 | data 系列,1d数组或列表 |
| 2 | bins 组织箱的规格 |
| 3 | hist 布尔 |
| 4 | kde 布尔 |
这些是需要研究的基本和重要参数。
Seaborn - Histogram
直方图表示通过沿数据范围形成箱的数据分布,然后绘制条以显示落入每个箱中的观察数。
Seaborn附带了一些数据集,我们在前面的章节中使用了很少的数据集。 我们已经学习了如何加载数据集以及如何查找可用数据集列表。
Seaborn附带了一些数据集,我们在前面的章节中使用了很少的数据集。 我们已经学习了如何加载数据集以及如何查找可用数据集列表。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()
输出 (Output)
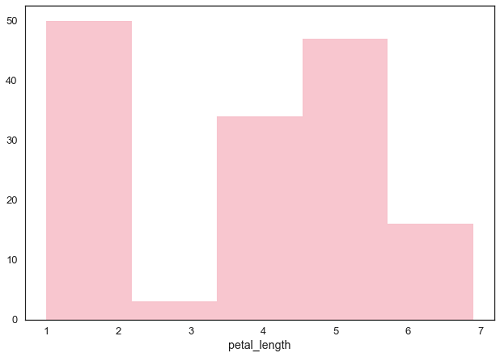
这里, kde标志设置为False。 结果,将去除核估计图的表示并且仅绘制直方图。
Seaborn - Kernel Density Estimates
核密度估计(KDE)是一种估计连续随机变量的概率密度函数的方法。 它用于非参数分析。
在distplot中将hist标志设置为False将产生核密度估计图。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()
输出 (Output)
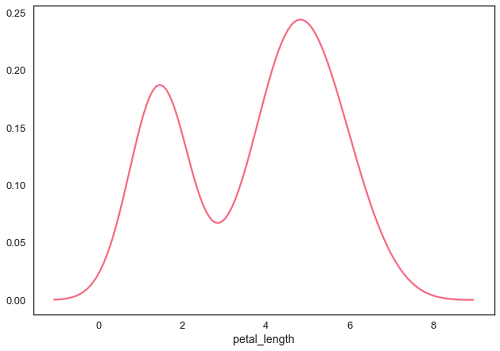
拟合参数分布
distplot()用于可视化数据集的参数分布。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()
输出 (Output)
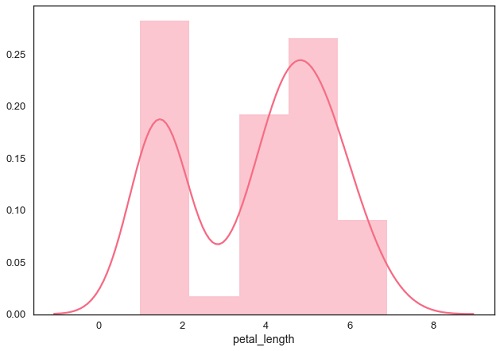
绘制双变量分布
双变量分布用于确定两个变量之间的关系。 这主要涉及两个变量之间的关系以及一个变量相对于另一个变量的行为。
分析seaborn中双变量分布的最佳方法是使用jointplot()函数。
Jointplot创建了一个多面板图形,用于投影两个变量之间的双变量关系,以及每个变量在不同轴上的单变量分布。
散点图
散点图是可视化分布的最方便的方式,其中每个观察通过x和y轴在二维图中表示。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()
输出 (Output)
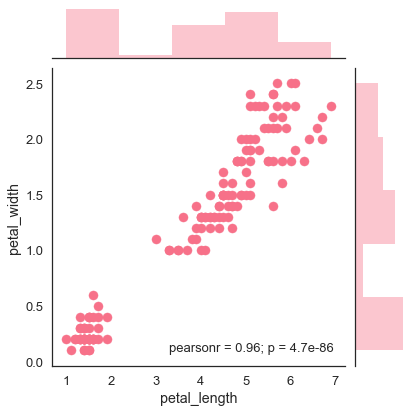
上图显示了Iris数据中petal_length和petal_width之间的关系。 该图中的趋势表明,研究中的变量之间存在正相关关系。
Hexbin Plot
当数据密度稀疏时,即当数据非常分散且难以通过散点图分析时,六边形分箱用于双变量数据分析。
名为“kind”和值“hex”的附加参数绘制了hexbin图。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
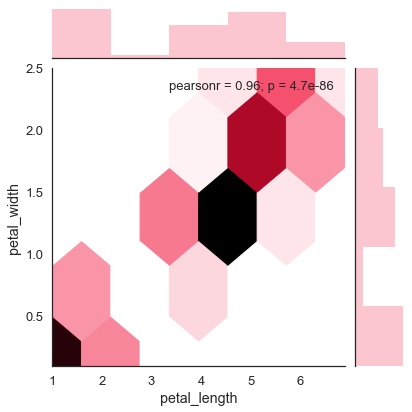
核密度估计
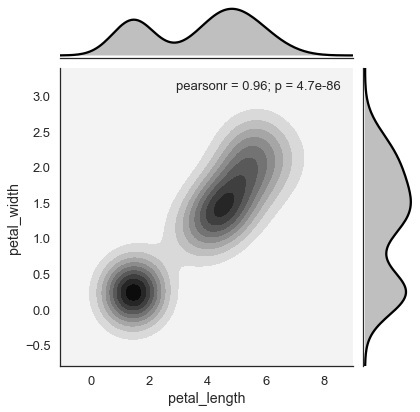
核密度估计是估计变量分布的非参数方法。 在seaborn中,我们可以使用jointplot().绘制kde jointplot().
将值“kde”传递给参数种类以绘制内核图。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
输出 (Output)
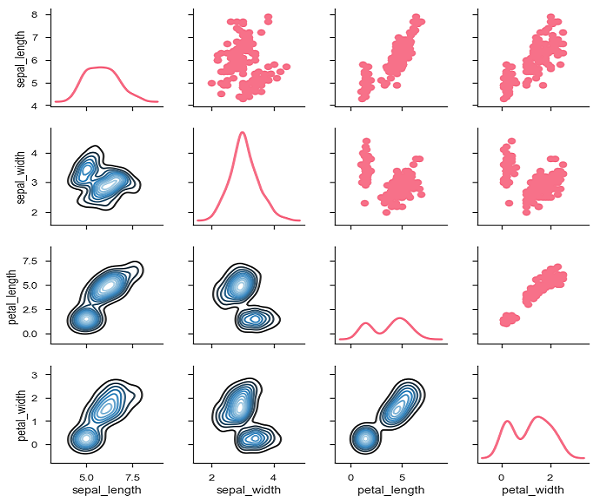
Seaborn - Visualizing Pairwise Relationship
实时研究中的数据集包含许多变量。 在这种情况下,应分析每个变量之间的关系。 绘制(n,2)组合的双变量分布将是一个非常复杂和耗时的过程。
要在数据集中绘制多个成对的双变量分布,可以使用pairplot()函数。 这显示了DataFrame中变量(n,2)组合作为图表矩阵的关系,对角线图是单变量图。
Axes
在本节中,我们将了解轴是什么,它们的用法,参数等等。
用法 (Usage)
seaborn.pairplot(data,…)
参数 (Parameters)
下表列出了Axes的参数 -
| Sr.No. | 参数和描述 |
|---|---|
| 1 | data 数据帧 |
| 2 | hue 数据变量将绘图方面映射到不同的颜色。 |
| 3 | palette 用于映射色调变量的颜色集 |
| 4 | kind 一种非身份关系的情节。 {'scatter','reg'} |
| 5 | diag_kind 对角子图的一种情节。 {'hist','kde'} |
除数据外,所有其他参数均为可选参数。 pairplot可以接受的其他参数很少。 上面提到的常用params。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()
输出 (Output)
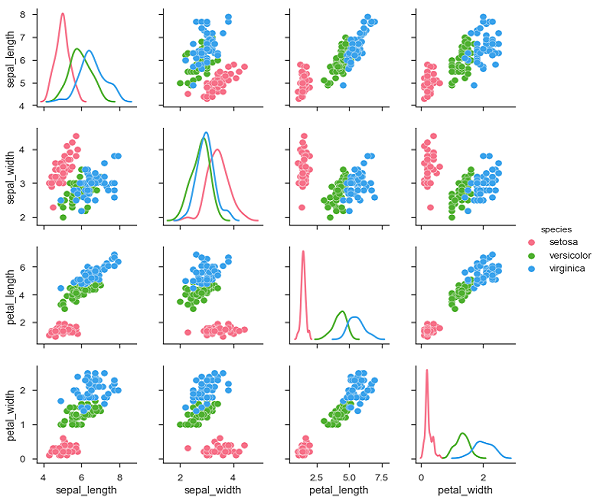
我们可以观察每个图中的变化。 图表采用矩阵格式,行名称表示x轴,列名称表示y轴。
对角线图是核密度图,其他图是如上所述的散点图。
Seaborn - Plotting Categorical Data
在前面的章节中,我们学习了散点图,hexbin图和kde图,用于分析研究中的连续变量。 当研究中的变量是分类时,这些图不适合。
当研究中的一个或两个变量是分类时,我们使用像striplot(),swarmplot()等那样的图。 Seaborn提供了这样做的界面。
分类散点图
在本节中,我们将了解分类散点图。
stripplot()
当研究中的一个变量是分类时,使用stripplot()。 它表示沿任意一个轴排序的数据。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()
输出 (Output)
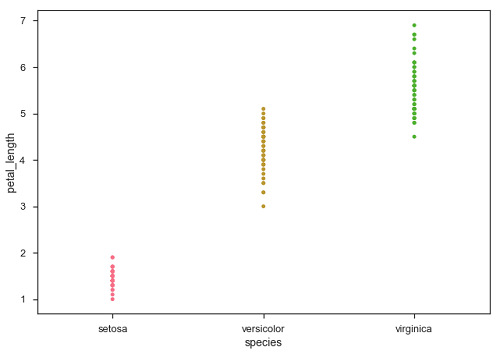
在上图中,我们可以清楚地看到每个物种中petal_length的差异。 但是,上述散点图的主要问题是散点图上的点是重叠的。 我们使用'Jitter'参数来处理这种情况。
抖动会为数据添加一些随机噪声。 此参数将调整沿分类轴的位置。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()
输出 (Output)
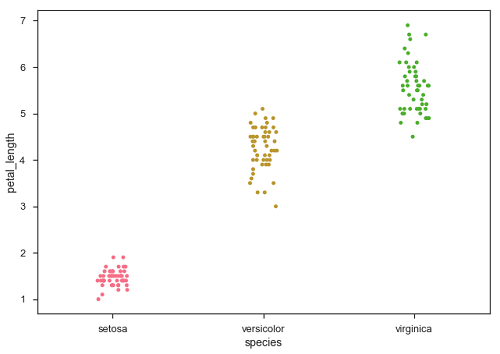
现在,可以很容易地看到点的分布。
Swarmplot()
另一个可以用作'抖动'替代的选项是函数swarmplot() 。 此功能将散点图的每个点定位在分类轴上,从而避免重叠点 -
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
输出 (Output)
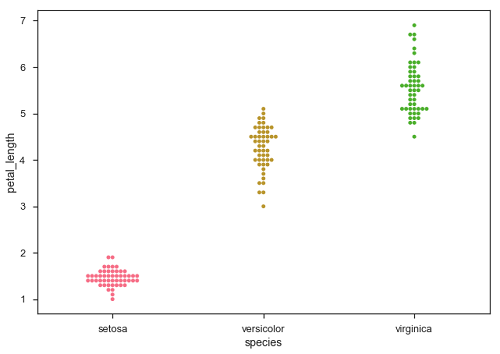
Seaborn - Distribution of Observations
在我们在前一章中讨论的分类散点图中,该方法在它可以提供的关于每个类别中的值分布的信息中受到限制。 现在,进一步说,让我们看看什么可以促进我们与类别进行比较。
方块图
Boxplot是一种通过四分位数可视化数据分布的便捷方式。
箱形图通常具有从箱子延伸的垂直线,其被称为晶须。 这些晶须表明在上下四分位数之外的可变性,因此Box Plots也被称为box-and-whisker图和box-and-whisker图。 数据中的任何异常值都被绘制为单个点。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
输出 (Output)
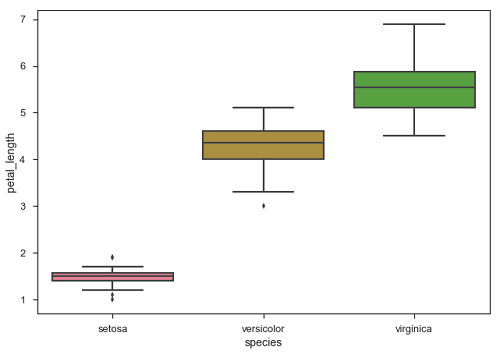
图中的点表示异常值。
小提琴情节
小提琴图是箱形图与核密度估计的组合。 因此,这些图更容易分析和理解数据的分布。
让我们使用提示数据集来学习更多小提琴图。 此数据集包含与餐厅客户提供的提示相关的信息。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()
输出 (Output)
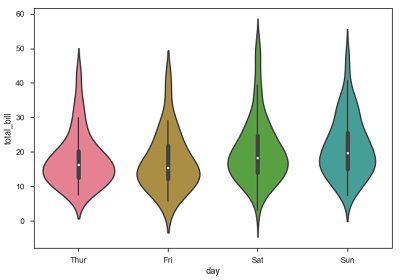
箱形图中的四分位数和胡须值显示在小提琴内。 由于小提琴曲线使用KDE,小提琴的较宽部分表示较高的密度,较窄的区域表示相对较低的密度。 箱形图中的四分位数范围和kde中的较高密度部分落在每类小提琴图的相同区域中。
上图显示了一周中四天的total_bill分布情况。 但是,除此之外,如果我们想看看分布在性别方面的表现如何,让我们在下面的例子中探讨它。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill",hue = 'sex', data = df)
plt.show()
输出 (Output)
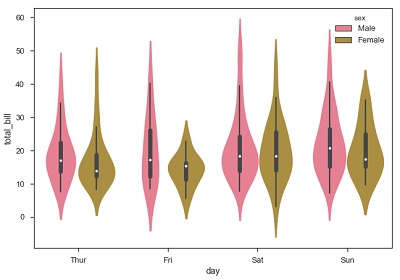
现在我们可以清楚地看到男性和女性之间的消费行为。 我们可以很容易地说,通过观察情节,男性比女性赚更多的账单。
并且,如果色调变量只有两个类,我们可以通过在给定的一天将每个小提琴分成两个而不是两个小提琴来美化该情节。 小提琴的任何一部分都是指色调变量中的每个类。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y="total_bill",hue = 'sex', data = df)
plt.show()
输出 (Output)
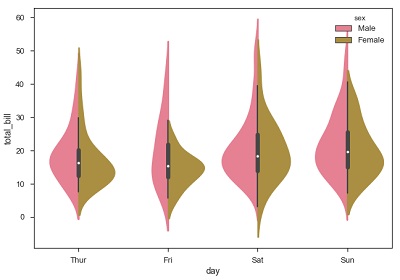
Seaborn - Statistical Estimation
在大多数情况下,我们处理数据整体分布的估计。 但是当涉及到集中趋势估计时,我们需要一种特定的方式来总结分布。 平均值和中值是常用的估计分布集中趋势的技术。
在我们在上一节中学到的所有图中,我们对整个分布进行了可视化。 现在,让我们讨论一下我们可以用来估计分布集中趋势的图。
酒吧情节
barplot()显示分类变量和连续变量之间的关系。 数据以矩形条表示,条形的长度表示该类别中数据的比例。
条形图表示集中趋势的估计。 让我们使用'泰坦尼克'数据集来学习条形图。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
输出 (Output)
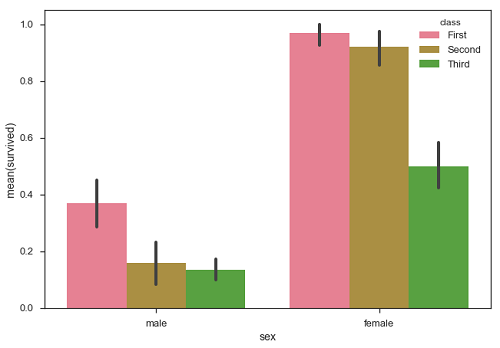
在上面的例子中,我们可以看到每个class中男性和女性的平均幸存数。 从情节我们可以理解,存活的男性比男性更多。 在男性和女性中,更多的幸存者来自头等舱。
条形图中的一个特例是显示每个类别中的观察结果,而不是计算第二个变量的统计数据。 为此,我们使用countplot().
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()
输出 (Output)
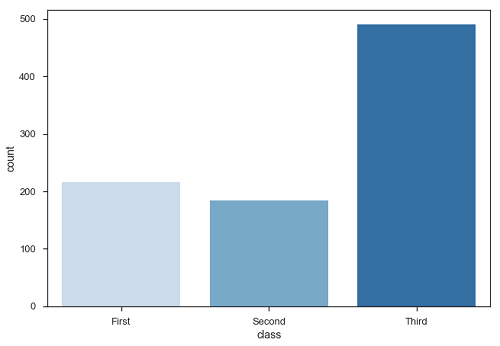
Plot说,三等舱的乘客数量高于一等舱和二等舱。
点图
点图与条形图相同,但风格不同。 而不是完整条,估计值由另一轴上某个高度处的点表示。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
输出 (Output)
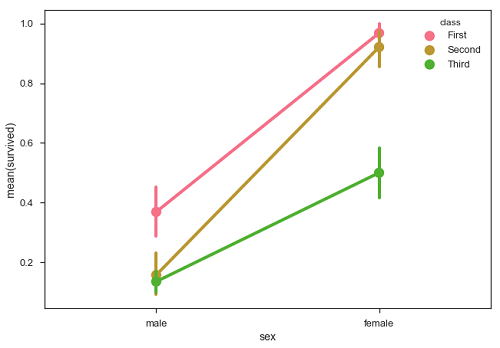
Seaborn - Plotting Wide Form Data
最好使用'long-from'或'tidy'数据集。 但有时当我们没有选择而不是使用“宽格式”数据集时,相同的功能也可以应用于各种格式的“宽格式”数据,包括Pandas数据帧或二维NumPy阵列。 这些对象应直接传递给data参数,x和y变量必须指定为字符串
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()
输出 (Output)
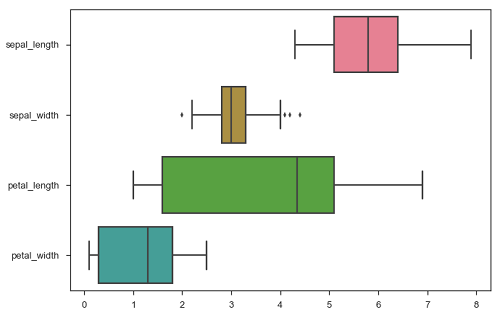
此外,这些函数接受Pandas或NumPy对象的向量,而不是DataFrame中的变量。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()
输出 (Output)
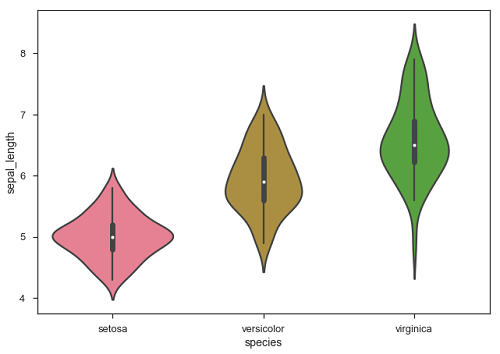
在Python世界中为许多开发人员使用Seaborn的主要优点是因为它可以将pandas DataFrame对象作为参数。
Seaborn - Multi Panel Categorical Plots
我们可以使用两个图表来显示分类数据,您可以使用函数pointplot()或更高级别的函数factorplot() 。
Factorplot (Factorplot)
Factorplot在FacetGrid上绘制了一个分类图。 使用'kind'参数,我们可以选择像boxplot,violinplot,barplot和stripplot这样的情节。 FacetGrid默认使用pointplot。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = pulse", hue = "kind",data = df);
plt.show()
输出 (Output)
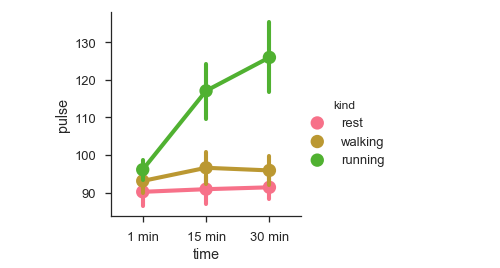
我们可以使用不同的图来使用kind参数可视化相同的数据。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()
输出 (Output)
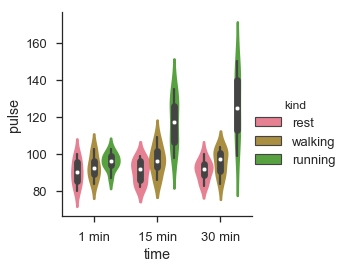
实际上,数据被绘制在小平面网格上。
什么是Facet Grid?
Facet grid通过划分变量形成由行和列定义的面板矩阵。 由于面板,单个图看起来像多个图。 分析两个离散变量中的所有组合非常有用。
让我们通过一个例子可视化上面的定义
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()
输出 (Output)
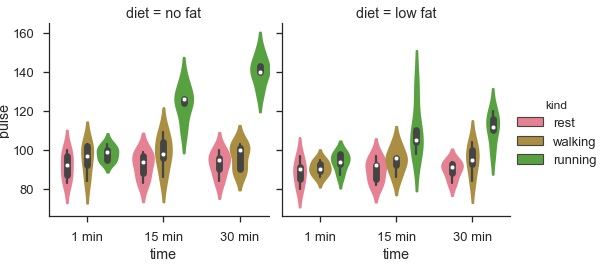
使用Facet的优点是,我们可以在绘图中输入另一个变量。 上面的图分为两个图,基于第三个变量,称为'diet',使用'col'参数。
我们可以制作许多列面并将它们与网格的行对齐 -
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.factorplot("alive", col = "deck", col_wrap = 3,data = df[df.deck.notnull()],kind = "count")
plt.show()
产量
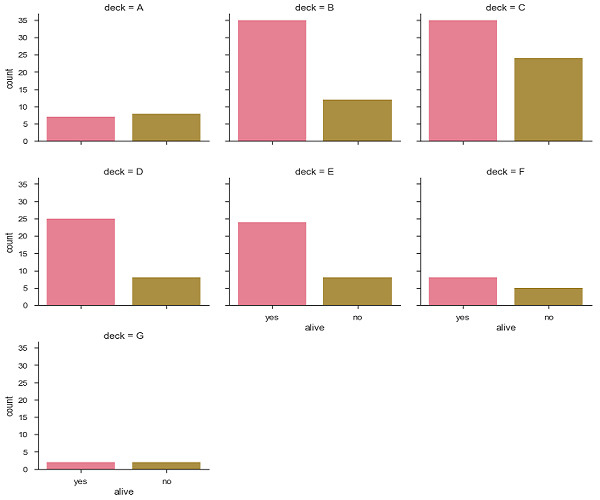
Seaborn - Linear Relationships
大多数情况下,我们使用包含多个定量变量的数据集,而分析的目标通常是将这些变量相互关联。 这可以通过回归线来完成。
在构建回归模型时,我们经常检查multicollinearity,我们必须看到连续变量的所有组合之间的相关性,并且如果存在,将采取必要的行动来消除多重共线性。 在这种情况下,以下技术会有所帮助。
绘制线性回归模型的函数
Seaborn中有两个主要功能可视化通过回归确定的线性关系。 这些函数是regplot()和lmplot() 。
regplot vs lmplot
| regplot | lmplot |
|---|---|
| 接受各种格式的x和y变量,包括简单的numpy数组,pandas Series对象,或者作为pandas DataFrame中变量的引用 | 将数据作为必需参数,并且必须将x和y变量指定为字符串。 该数据格式称为“长格式”数据 |
现在让我们绘制情节。
例子 (Example)
绘制regplot,然后在此示例中使用相同的数据进行lmplot
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()
输出 (Output)
您可以看到两个图之间的大小差异。
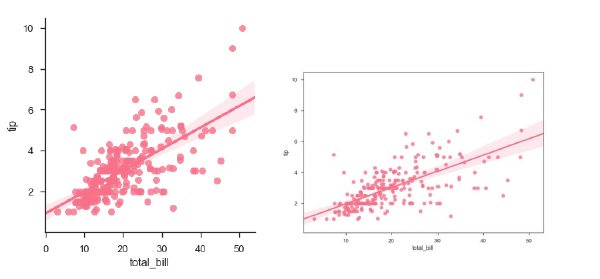
当其中一个变量采用离散值时,我们也可以拟合线性回归
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()
输出 (Output)
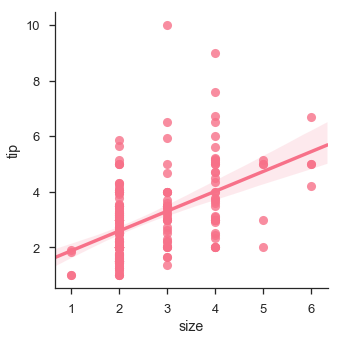
适合不同种类的模型
上面使用的简单线性回归模型非常容易拟合,但在大多数情况下,数据是非线性的,并且上述方法不能概括回归线。
让我们使用Anscombe的数据集和回归图 -
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()
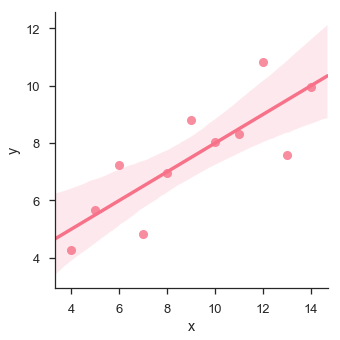
在这种情况下,数据非常适合具有较小方差的线性回归模型。
让我们看另一个例子,其中数据偏差很大,表明最佳拟合线不好。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()
输出 (Output)
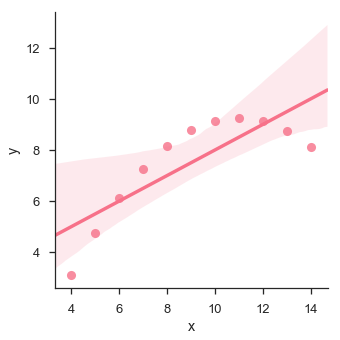
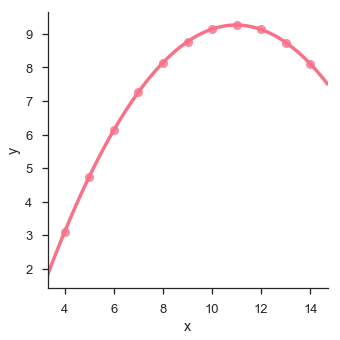
该图显示了数据点与回归线的高偏差。 这种非线性,更高阶可以使用lmplot()和regplot() 。这些可以拟合多项式回归模型来探索数据集中的简单种类的非线性趋势 -
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()
输出 (Output)
Seaborn - Facet Grid
探索中等维数据的有用方法是在数据集的不同子集上绘制同一图的多个实例。
这种技术通常被称为“格子”或“格子”绘图,它与“小倍数”的概念有关。
要使用这些功能,您的数据必须位于Pandas DataFrame中。
绘制小数倍的数据子集
在上一章中,我们已经看到了FacetGrid示例,其中FacetGrid类有助于使用多个面板在数据集的子集中分别显示一个变量的分布以及多个变量之间的关系。
FacetGrid最多可以绘制三维 - 行,列和色调。 前两个与得到的轴阵列有明显的对应关系; 将色调变量视为沿深度轴的第三个维度,其中不同的级别用不同的颜色绘制。
FacetGrid对象将数据FacetGrid作为输入,以及将形成网格的行,列或色调维度的变量的名称。
变量应该是分类的,并且变量的每个级别的数据将用于沿该轴的小平面。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
plt.show()
输出 (Output)
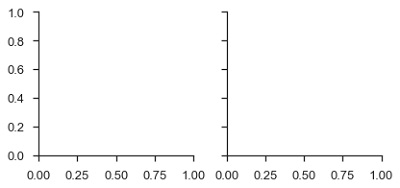
在上面的例子中,我们刚刚初始化了facetgrid对象,它不会在它们上面绘制任何东西。
在此网格上可视化数据的主要方法是使用FacetGrid.map()方法。 让我们使用直方图来查看每个子集中的提示分布。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
g.map(plt.hist, "tip")
plt.show()
输出 (Output)
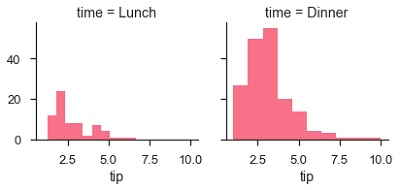
由于参数col,绘图的数量不止一个。 我们在前面的章节中讨论了col参数。
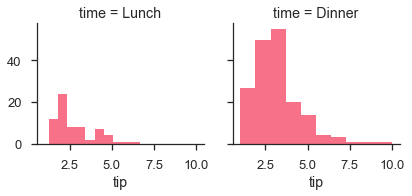
要创建关系图,请传递多个变量名称。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "sex", hue = "smoker")
g.map(plt.scatter, "total_bill", "tip")
plt.show()
输出 (Output)
Seaborn - Pair Grid
PairGrid允许我们使用相同的绘图类型绘制子图的网格以可视化数据。
与FacetGrid不同,它为每个子图使用不同的变量对。 它形成了子图的矩阵。 它有时也被称为“散点图矩阵”。
pairgrid的用法类似于facetgrid。 首先初始化网格,然后通过绘图功能。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map(plt.scatter);
plt.show()
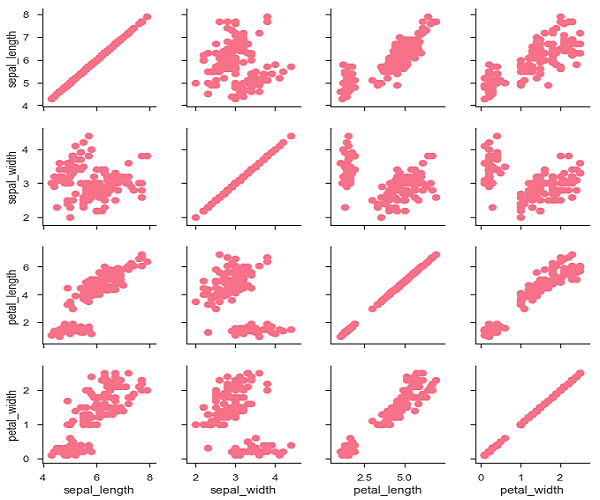
也可以在对角线上绘制不同的函数,以显示每列中变量的单变量分布。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()
输出 (Output)
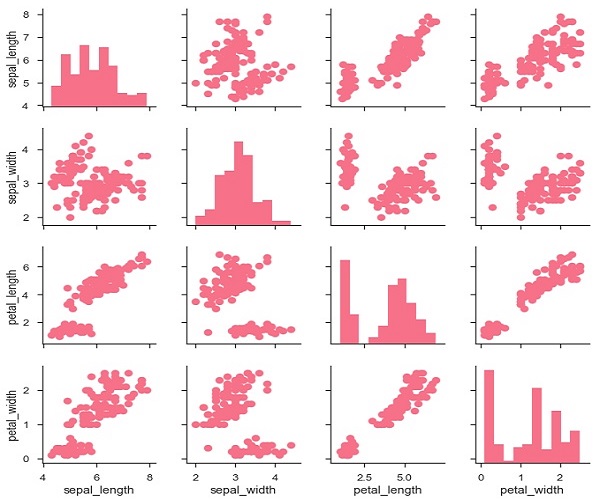
我们可以使用另一个分类变量自定义这些图的颜色。 例如,虹膜数据集对三种不同种类的鸢尾花中的每一种都有四种测量值,因此您可以看到它们之间的差异。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()
输出 (Output)
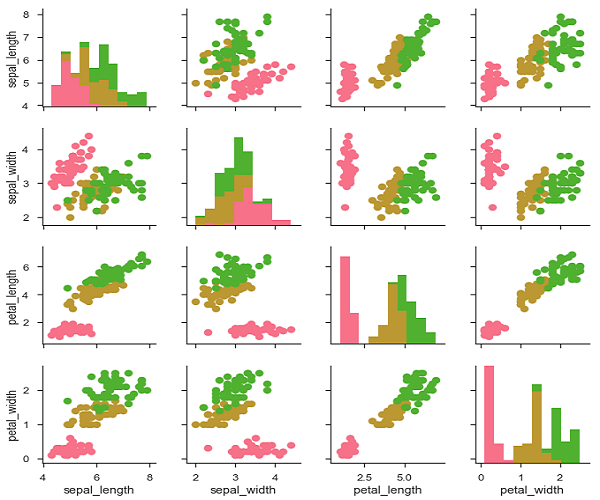
我们可以在上三角和下三角中使用不同的函数来查看关系的不同方面。
例子 (Example)
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()
输出 (Output)