强化学习(Reinforcement Learning)
在本章中,您将详细了解使用Python在AI中强化学习的概念。
强化学习的基础知识
这种类型的学习用于基于评论者信息来加强或加强网络。 也就是说,在强化学习下训练的网络从环境中接收一些反馈。 然而,反馈是有评价性的,而不是像监督学习那样具有指导性。 基于该反馈,网络执行权重的调整以在将来获得更好的批评信息。
这种学习过程类似于监督学习,但我们的信息可能非常少。 下图给出了强化学习的方框图 -
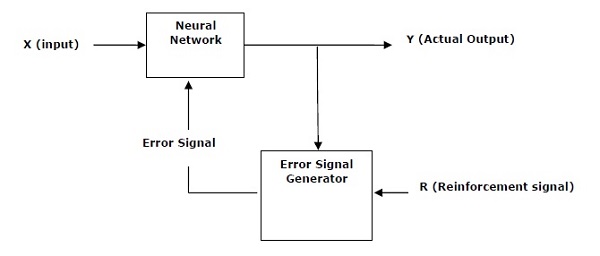
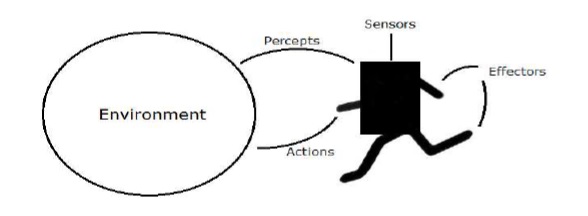
构建块:环境和代理
环境与代理是人工智能强化学习的主要组成部分。 本节将详细讨论它们 -
Agent
代理商是指通过传感器感知其环境并通过效应器对该环境起作用的任何事物。
human agent具有与传感器平行的感觉器官,例如眼睛,耳朵,鼻子,舌头和皮肤,以及用于效应器的其他器官,例如手,腿,嘴。
robotic agent取代传感器的摄像机和红外测距仪,以及用于效应器的各种电机和执行器。
software agent将位串编码为其程序和动作。
代理术语
人工智能中强化学习中使用以下术语 -
Performance Measure of Agent - 这是Performance Measure of Agent成功程度的标准。
Behavior of Agent - 代理在任何给定的感知序列之后执行的操作。
感知 - 它是代理在给定实例中的感知输入。
感知Percept Sequence - 它是代理人迄今为止所感知的所有历史。
Agent Function - 它是从规则序列到动作的映射。
Environment
某些程序在完全artificial environment运行,仅限于键盘输入,数据库,计算机文件系统和屏幕上的字符输出。
相比之下,一些软件代理,如软件机器人或软机器人,存在于丰富且无限的软机器人域中。 模拟器具有very detailed和complex environment 。 软件代理需要实时从一系列动作中进行选择。
例如,设计用于扫描客户的在线偏好并向客户显示有趣项目的软机器人在real artificial environment和artificial environment 。
环境属性
环境具有多重属性,如下所述 -
Discrete/Continuous - 如果环境中有明显不同的,明确定义的状态,则环境是离散的,否则它是连续的。 例如,国际象棋是一个离散的环境,而驾驶是一个连续的环境。
Observable/Partially Observable - 如果可以从感知中确定每个时间点的完整环境状态,则可以观察到; 否则只能部分观察到。
Static/Dynamic - 如果代理正在运行时环境没有改变,那么它是静态的; 否则它是动态的。
Single agent/Multiple agents - 环境可能包含其他代理,这些代理可能与代理的代理相同或不同。
Accessible/Inaccessible - 如果代理的传感设备可以访问完整的环境状态,则该代理可以访问该环境; 否则它是无法访问的。
Deterministic/Non-deterministic - 如果环境的下一个状态完全由当前状态和代理的动作决定,那么环境是确定性的; 否则它是不确定的。
Episodic/Non-episodic - 在情节环境中,每一集都由代理人感知并随后行动起来。 其行动的质量仅取决于剧集本身。 后续剧集不依赖于前一集中的动作。 情境环境要简单得多,因为代理人不需要提前思考。
用Python构建环境
为了构建强化学习代理,我们将使用OpenAI Gym软件包,可以在以下命令的帮助下安装 -
pip install gym
OpenAI健身房有各种环境,可用于各种用途。 其中很少是Cartpole-v0, Hopper-v1和MsPacman-v0 。 他们需要不同的引擎。 有关OpenAI Gym的详细文档,请OpenAI Gym https://gym.openai.com/docs/#environments 。
以下代码显示了cartpole-v0环境的Python代码示例 -
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())

您可以以类似的方式构建其他环境。
用Python构建学习代理
对于构建强化学习代理,我们将使用如图所示的OpenAI Gym包 -
import gym
env = gym.make('CartPole-v0')
for _ in range(20):
observation = env.reset()
for i in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(i+1))
break
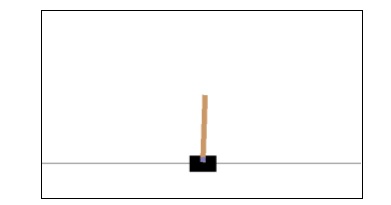
观察到cartpole可以平衡自己。
