AI with Python – 快速指南
AI with Python – Primer Concept
自从计算机或机器的发明以来,它们执行各种任务的能力经历了指数级增长。 人类已经开发出计算机系统的功能,包括各种工作领域,它们的速度越来越快,并且随着时间的推移缩小了尺寸。
计算机科学的一个分支,名为人工智能,追求创造像人类一样聪明的计算机或机器。
人工智能的基本概念(AI)
根据人工智能之父约翰麦卡锡的说法,它是“制造智能机器的科学与工程,特别是智能计算机程序”。
人工智能是一种使计算机,计算机控制的机器人或软件智能地思考的方式,其方式与智能人类的思维方式类似。 人工智能是通过研究人类大脑如何思考以及人类在尝试解决问题时如何学习,决定和工作,然后将本研究的结果用作开发智能软件和系统的基础来实现的。
在充分利用计算机系统的力量的同时,人类的好奇心使他怀疑,“机器能像人类一样思考和行为吗?”
因此,人工智能的发展始于在我们发现并在人类中高度重视的机器中创造类似的智能。
学习人工智能的必要性
我们知道AI追求创造像人类一样聪明的机器。 我们研究AI的原因有很多。 原因如下 -
AI可以通过数据学习
在我们的日常生活中,我们处理的是大量的数据,人类的大脑无法跟踪这么多的数据。 这就是我们需要自动化的原因。 为了实现自动化,我们需要研究AI,因为它可以从数据中学习,并且可以准确无误地完成重复性任务。
AI可以自学
系统应该自学,因为数据本身不断变化,并且必须不断更新从这些数据中获得的知识。 我们可以使用AI来实现这一目的,因为启用AI的系统可以自学。
AI可以实时响应
借助神经网络的人工智能可以更深入地分析数据。 由于这种能力,AI可以根据实时情况思考和响应情况。
AI实现准确性
在深度神经网络的帮助下,AI可以实现极高的准确性。 AI帮助医学领域从患者的MRI中诊断癌症等疾病。
AI可以组织数据以最大限度地利用它
数据是使用自学习算法的系统的知识产权。 我们需要AI以一种始终提供最佳结果的方式索引和组织数据。
了解情报
使用AI,可以构建智能系统。 我们需要了解智力的概念,以便我们的大脑可以构建像自己这样的另一个智能系统。
什么是情报?
系统计算,推理,感知关系和类比的能力,从经验中学习,存储和检索记忆中的信息,解决问题,理解复杂的想法,流利地使用自然语言,分类,概括和适应新情况。
智力类型
正如美国发展心理学家霍华德加德纳所描述的那样,情报来自多方面 -
| Sr.No | 情报与描述 | 例 |
|---|---|---|
| 1 | Linguistic intelligence 能够说,识别和使用音韵(语音),语法(语法)和语义(意义)的机制。 | Narrators, Orators |
| 2 | Musical intelligence 能够创造,交流和理解声音,对音高,节奏的理解。 | Musicians, Singers, Composers |
| 3 | Logical-mathematical intelligence 在没有动作或对象的情况下使用和理解关系的能力。 它也是理解复杂和抽象概念的能力。 | Mathematicians, Scientists |
| 4 | Spatial intelligence 能够感知视觉或空间信息,改变它,并在不参考物体的情况下重新创建视觉图像,构建3D图像,以及移动和旋转它们。 | Map readers, Astronauts, Physicists |
| 5 | Bodily-Kinesthetic intelligence 能够使用完整或部分身体来解决问题或时尚产品,控制精细和粗糙的运动技能,以及操纵物体。 | Players, Dancers |
| 6 | Intra-personal intelligence 能够区分自己的感受,意图和动机。 | Gautam Buddhha |
| 7 | Interpersonal intelligence 能够识别和区分其他人的感受,信念和意图。 | Mass Communicators, Interviewers |
您可以说机器或系统在其中至少配备了一个或所有智能时是人工智能的。
什么是智力组成?
情报是无形的。 它由 - 组成 -
- Reasoning
- Learning
- 解决问题
- Perception
- 语言智能

让我们简要介绍一下所有组件 -
推理(Reasoning)
正是这一系列过程使我们能够为判断,决策和预测提供依据。 大致有两种类型 -
| 归纳推理 | 演绎推理 |
|---|---|
| 它进行具体的观察,以作出广泛的一般性陈述。 | 它首先是一般性陈述,并探讨了达成具体逻辑结论的可能性。 |
| 即使所有前提在陈述中都是正确的,归纳推理也允许结论是错误的。 | 如果某类事物的某些事情是正确的,那么该类的所有成员也是如此。 |
| Example - “妮塔是老师。尼塔很好学。因此,所有老师都很好学。” | Example - “60岁以上的所有女性都是祖母.Shalini是65岁。因此,Shalini是一位祖母。” |
学习 - 升
人类,特定动物物种和启用AI的系统具有学习能力。 学习分类如下 -
听觉学习
它通过听和听来学习。 例如,学生听录音带讲座。
情节学习
通过记住一个人目睹或经历过的事件序列来学习。 这是线性和有序的。
运动学习
它通过精确的肌肉运动来学习。 例如,挑选对象,书写等
观察学习
通过观察和模仿他人来学习。 例如,孩子试图通过模仿她的父母来学习。
感性学习
它正在学习识别以前见过的刺激。 例如,识别和分类对象和情境。
关系学习
它涉及学习基于关系属性而不是绝对属性来区分各种刺激。 例如,在烹饪土豆时添加“少一点”的盐,上次加入咸味时,加入一汤匙盐煮熟。
Spatial Learning - 通过视觉刺激学习,例如图像,颜色,地图等。例如,一个人可以在实际跟随道路之前记住路线图。
Stimulus-Response Learning - 学习在存在某种刺激时执行特定行为。 例如,一只狗在听到门铃时抬起耳朵。
解决问题
这是一个过程,在这个过程中,人们通过采取一些被已知或未知障碍阻挡的路径来感知并试图从当前情况得出所需的解决方案。
解决问题还包括decision making ,这是从多种替代方案中选择最合适的替代方案以达到预期目标的过程。
感知(Perception)
它是获取,解释,选择和组织感官信息的过程。
感知假设sensing 。 在人类中,感知由感觉器官辅助。 在AI领域,感知机制以有意义的方式将传感器获取的数据放在一起。
语言智能
这是一个人使用,理解,说话和写作口头和书面语言的能力。 这在人际交往中很重要。
人工智能有什么参与
人工智能是一个广泛的研究领域。 该研究领域有助于找到解决现实世界问题的方法。
现在让我们看看AI中不同的研究领域 -
机器学习
它是人工智能最受欢迎的领域之一。 该领域的基本概念是使机器从数据中学习,因为人类可以从他/她的经验中学习。 它包含学习模型,在此基础上可以对未知数据进行预测。
Logic
这是另一个重要的研究领域,其中使用数学逻辑来执行计算机程序。 它包含执行模式匹配,语义分析等的规则和事实。
搜索(Searching)
这个研究领域主要用于象棋,井字游戏等游戏。 搜索算法在搜索整个搜索空间后提供最佳解决方案。
人工神经网络
这是一个高效计算系统网络,其核心主题是从生物神经网络的类比中借鉴而来。 ANN可用于机器人,语音识别,语音处理等。
遗传算法
遗传算法有助于在多个程序的帮助下解决问题。 结果将基于选择最适合的。
知识表示
这是一个研究领域,借助它我们可以用一台机器可以理解的机器来表示事实。 表示知识的效率更高; 更多的系统将是智能的。
人工智能的应用
在本节中,我们将看到AI支持的不同字段 -
Gaming
AI在诸如国际象棋,扑克,井字游戏等战略游戏中起着至关重要的作用,其中机器可以基于启发式知识来思考大量可能的位置。
自然语言处理
可以与理解人类所说的自然语言的计算机进行交互。
专家系统
有些应用程序集成了机器,软件和特殊信息,以传授推理和建议。 它们为用户提供解释和建议。
视觉系统
这些系统理解,解释和理解计算机上的视觉输入。 例如,
间谍飞机拍摄照片,用于计算空间信息或区域地图。
医生使用临床专家系统来诊断患者。
警方使用的计算机软件可以识别法庭艺术家所存储的肖像,从而识别犯罪者的脸部。
语音识别
一些智能系统能够在人类与之对话的同时,通过句子及其含义来听取和理解语言。 它可以处理不同的重音,俚语,背景噪音,寒冷引起的人体噪音变化等。
手写识别
手写识别软件通过笔或笔在屏幕上读取写在纸上的文本。 它可以识别字母的形状并将其转换为可编辑的文本。
智能机器人
机器人能够执行人类给出的任务。 它们具有传感器,用于检测来自现实世界的物理数据,例如光,热,温度,运动,声音,碰撞和压力。 他们拥有高效的处理器,多个传感器和巨大的内存,以展示智能。 此外,他们能够从错误中吸取教训,并能适应新的环境。
认知建模:模拟人类思维过程
认知建模基本上是计算机科学中的研究领域,涉及研究和模拟人类的思维过程。 人工智能的主要任务是让机器像人一样思考。 人类思维过程最重要的特征是解决问题。 这就是为什么或多或少的认知建模试图理解人类如何解决问题的原因。 之后,该模型可用于各种AI应用,如机器学习,机器人,自然语言处理等。以下是人类大脑不同思维水平的图表 -

代理与环境
在本节中,我们将重点关注代理和环境以及这些对人工智能的帮助。
Agent
代理商是指通过传感器感知其环境并通过效应器对该环境起作用的任何事物。
human agent具有与传感器平行的感觉器官,例如眼睛,耳朵,鼻子,舌头和皮肤,以及用于效应器的其他器官,例如手,腿,嘴。
robotic agent取代传感器的摄像机和红外测距仪,以及用于效应器的各种电机和执行器。
software agent将位串编码为其程序和动作。
Environment
某些程序在完全artificial environment运行,仅限于键盘输入,数据库,计算机文件系统和屏幕上的字符输出。
相比之下,一些软件代理(软件机器人或软机器人)存在于丰富的无限软机器人域中。 模拟器具有very detailed, complex environment 。 软件代理需要实时从一系列动作中进行选择。 软件机器人旨在扫描客户的在线偏好,并向real和artificial环境中的客户展示有趣的项目。
AI with Python – Getting Started
在本章中,我们将学习如何开始使用Python。 我们还将了解Python如何帮助人工智能。
为什么Python用于AI
人工智能被认为是未来的趋势技术。 已经有很多应用程序在上面制作。 因此,许多公司和研究人员对此感兴趣。 但是,这里出现的主要问题是,在哪种编程语言中可以开发这些AI应用程序? 有各种编程语言,如Lisp,Prolog,C ++,Java和Python,可用于开发AI的应用程序。 其中,Python编程语言获得了巨大的普及,原因如下 -
语法简单,编码少
Python涉及非常少的编码和简单的语法,其他编程语言可用于开发AI应用程序。 由于此功能,测试可以更容易,我们可以更专注于编程。
用于AI项目的内置库
使用Python进行AI的一个主要优点是它内置了库。 Python拥有几乎所有类型的AI项目的库。 例如, NumPy, SciPy, matplotlib, nltk, SimpleAI是一些重要的内置Python库。
Open source - Python是一种开源编程语言。 这使它在社区中广泛流行。
Can be used for broad range of programming - Python可用于广泛的编程任务,如小型shell脚本到企业Web应用程序。 这是Python适用于AI项目的另一个原因。
Python的特点
Python是一种高级,解释,交互式和面向对象的脚本语言。 Python的设计具有高可读性。 它经常使用英语关键词,而其他语言使用标点符号,并且它的语法结构比其他语言少。 Python的功能包括以下内容 -
Easy-to-learn - Python几乎没有关键字,结构简单,语法清晰。 这允许学生快速学习语言。
Easy-to-read - Python代码更清晰,更明显。
Easy-to-maintain - Python的源代码非常易于维护。
A broad standard library - Python的大部分库在UNIX,Windows和Macintosh上非常便携且跨平台兼容。
Interactive Mode - Python支持交互模式,允许交互式测试和调试代码片段。
Portable - Python可以在各种硬件平台上运行,并且在所有平台上都具有相同的界面。
Extendable - 我们可以向Python解释器添加低级模块。 这些模块使程序员能够更高效地添加或定制他们的工具。
Databases - Python为所有主要商业数据库提供接口。
GUI Programming - Python支持GUI应用程序,可以创建和移植到许多系统调用,库和Windows系统,如Windows MFC,Macintosh和Unix的X Window系统。
Scalable - 与shell脚本相比,Python为大型程序提供了更好的结构和支持。
Python的重要功能
现在让我们考虑Python的以下重要功能 -
它支持功能和结构化编程方法以及OOP。
它可以用作脚本语言,也可以编译为字节码来构建大型应用程序。
它提供非常高级的动态数据类型,并支持动态类型检查。
它支持自动垃圾收集。
它可以很容易地与C,C ++,COM,ActiveX,CORBA和Java集成。
安装Python (Installing Python)
Python发行版可用于大量平台。 您只需下载适用于您的平台的二进制代码并安装Python。
如果您的平台的二进制代码不可用,则需要C编译器手动编译源代码。 编译源代码在选择安装所需的功能方面提供了更大的灵活性。
以下是在各种平台上安装Python的快速概述 -
Unix和Linux安装
按照以下步骤在Unix/Linux机器上安装Python。
打开Web浏览器并转到https://www.python.org/downloads
点击链接下载适用于Unix/Linux的压缩源代码。
下载并解压缩文件。
如果要自定义某些选项,请编辑Modules/Setup文件。
运行./configure脚本
make
make install
这将在标准位置/ usr/local/bin及其库中安装Python,位于/usr/local/lib/pythonXX ,其中XX是Python的版本。
Windows安装 (Windows Installation)
请按照以下步骤在Windows计算机上安装Python。
打开Web浏览器并转到https://www.python.org/downloads
按照Windows安装程序python-XYZ .msi文件的链接进行操作,其中XYZ是您需要安装的版本。
要使用此安装程序python-XYZ .msi,Windows系统必须支持Microsoft Installer 2.0。 将安装程序文件保存到本地计算机,然后运行它以查明您的计算机是否支持MSI。
运行下载的文件。 这将打开Python安装向导,它非常易于使用。 只需接受默认设置,然后等待安装完成。
Macintosh安装
如果您使用的是Mac OS X,建议您使用Homebrew来安装Python 3.它是Mac OS X的一个很棒的软件包安装程序,它非常易于使用。 如果您没有Homebrew,可以使用以下命令安装它 -
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"
我们可以使用以下命令更新包管理器 -
$ brew update
现在运行以下命令在您的系统上安装Python3 -
$ brew install python3
设置PATH (Setting up PATH)
程序和其他可执行文件可以位于许多目录中,因此操作系统提供了一个搜索路径,列出了OS搜索可执行文件的目录。
该路径存储在环境变量中,该变量是由操作系统维护的命名字符串。 此变量包含命令shell和其他程序可用的信息。
路径变量在Unix中命名为PATH,在Windows中命名为Path(Unix区分大小写; Windows不是)。
在Mac OS中,安装程序会处理路径详细信息。 要从任何特定目录调用Python解释器,必须将Python目录添加到路径中。
在Unix/Linux上设置路径
要将Python目录添加到Unix中特定会话的路径 -
在csh shell中
键入setenv PATH "$PATH:/usr/local/bin/python"并按Enter 。
在bash shell(Linux)中
键入export ATH = "$PATH:/usr/local/bin/python"并按Enter 。
在sh或ksh shell中
键入PATH = "$PATH:/usr/local/bin/python"并按Enter 。
Note - /usr/local/bin/python是Python目录的路径。
在Windows上设置路径
要将Python目录添加到Windows中特定会话的路径中 -
At the command prompt - 键入path %path%;C:\Python并按Enter 。
Note - C:\Python是Python目录的路径。
运行Python (Running Python)
现在让我们看看运行Python的不同方法。 方法如下所述 -
交互式解释器 (Interactive Interpreter)
我们可以从Unix,DOS或任何其他为您提供命令行解释器或shell窗口的系统启动Python。
在命令行输入python 。
立即在交互式解释器中开始编码。
$python # Unix/Linux
OR
python% # Unix/Linux
OR
C:> python # Windows/DOS
以下是所有可用命令行选项的列表 -
| S.No. | 选项和说明 |
|---|---|
| 1 | -d 它提供调试输出。 |
| 2 | -o 它生成优化的字节码(产生.pyo文件)。 |
| 3 | -S 不要运行导入站点以在启动时查找Python路径。 |
| 4 | -v 详细输出(导入语句的详细跟踪)。 |
| 5 | -x 禁用基于类的内置异常(只使用字符串); 从版本1.6开始过时。 |
| 6 | -c cmd 运行作为cmd字符串发送的Python脚本。 |
| 7 | File 从给定文件运行Python脚本。 |
Script from the Command-line
可以通过在应用程序上调用解释器在命令行执行Python脚本,如下所示 -
$python script.py # Unix/Linux
要么,
python% script.py # Unix/Linux
要么,
C:> python script.py # Windows/DOS
Note - 确保文件权限模式允许执行。
综合发展环境
如果您的系统上有支持Python的GUI应用程序,您也可以从图形用户界面(GUI)环境运行Python。
Unix - IDLE是第一个用于Python的Unix IDE。
Windows - PythonWin是第一个用于Python的Windows界面,是一个带有GUI的IDE。
Macintosh - 可以从主网站获得Macintosh版本的Python以及IDLE IDE,可以下载为MacBinary或BinHex'd文件。
如果您无法正确设置环境,则可以从系统管理员处获取帮助。 确保Python环境设置正确并且工作正常。
我们还可以使用另一个名为Anaconda的Python平台。 它包括数百种流行的数据科学软件包以及适用于Windows,Linux和MacOS的conda软件包和虚拟环境管理器。 您可以通过操作系统从https://www.anaconda.com/download/链接下载它。
在本教程中,我们在MS Windows上使用Python 3.6.3版本。
AI with Python – Machine Learning
学习意味着通过学习或经验获得知识或技能。 基于此,我们可以定义机器学习(ML)如下 -
它可以被定义为计算机科学领域,更具体地说是人工智能的应用,其为计算机系统提供了学习数据和从经验改进而无需明确编程的能力。
基本上,机器学习的主要焦点是允许计算机自动学习而无需人为干预。 现在问题是如何开始和完成这种学习? 它可以从数据的观察开始。 数据可以是一些示例,指令或一些直接经验。 然后在此输入的基础上,通过查找数据中的某些模式,机器可以做出更好的决策。
机器学习类型(ML)
机器学习算法帮助计算机系统学习而无需明确编程。 这些算法分为监督或无监督。 现在让我们看一些算法 -
监督机器学习算法
这是最常用的机器学习算法。 它被称为监督,因为从训练数据集学习算法的过程可以被认为是监督学习过程的教师。 在这种ML算法中,可能的结果是已知的,训练数据也标有正确的答案。 可以理解如下 -
假设我们有输入变量x和输出变量y ,我们应用算法来学习从输入到输出的映射函数,例如 -
Y = f(x)
现在,主要目标是近似映射函数,以便当我们有新的输入数据(x)时,我们可以预测该数据的输出变量(Y)。
主要监督学习倾向问题可分为以下两类问题 -
Classification - 当我们有“黑色”,“教学”,“非教学”等分类输出时,一个问题被称为分类问题。
Regression - 当我们有“距离”,“千克”等实际值输出时,问题称为回归问题。
决策树,随机森林,knn,逻辑回归是监督机器学习算法的例子。
无监督机器学习算法
顾名思义,这些机器学习算法没有任何主管提供任何形式的指导。 这就是为什么无监督的机器学习算法与一些人称之为真正的人工智能的方法紧密结合的原因 可以理解如下 -
假设我们输入变量x,那么在监督学习算法中就没有相应的输出变量。
简单来说,我们可以说在无监督学习中,没有正确的答案,也没有教师可以提供指导。 算法有助于发现数据中有趣的模式。
无监督学习问题可分为以下两种问题 -
Clustering - 在聚类问题中,我们需要发现数据中的固有分组。 例如,按客户的购买行为对客户进行分组。
Association - 一个问题被称为关联问题,因为这类问题需要发现描述大部分数据的规则。 例如,找到同时购买x和y的客户。
用于聚类的K均值,用于关联的Apriori算法是无监督机器学习算法的示例。
加固机器学习算法
这些机器学习算法的使用非常少。 这些算法训练系统做出具体决策。 基本上,机器暴露在一个环境中,在那里它使用试错法连续训练自己。 这些算法从过去的经验中学习,并尝试捕获最佳可能的知识,以做出准确的决策。 马尔可夫决策过程是增强机器学习算法的一个例子。
最常见的机器学习算法
在本节中,我们将了解最常见的机器学习算法。 算法如下所述 -
线性回归
它是统计学和机器学习中最着名的算法之一。
基本概念 - 主要是线性回归是一种线性模型,它假设输入变量x和单个输出变量y之间的线性关系。 换句话说,我们可以说y可以从输入变量x的线性组合计算。 变量之间的关系可以通过拟合最佳线来建立。
线性回归的类型
线性回归有以下两种类型 -
Simple linear regression - 线性回归算法如果只有一个自变量,则称为简单线性回归。
Multiple linear regression - 线性回归算法如果具有多个自变量,则称为多元线性回归。
线性回归主要用于基于连续变量估计实际值。 例如,可以通过线性回归来估计基于实际值的一天中商店的总销售额。
Logistic回归
它是一种分类算法,也称为logit回归。
主要逻辑回归是一种分类算法,用于根据给定的一组自变量估计离散值,如0或1,真或假,是或否。 基本上,它预测概率,因此其输出介于0和1之间。
决策树
决策树是一种监督学习算法,主要用于分类问题。
基本上它是一个分类器,表示为基于自变量的递归分区。 决策树具有形成有根树的节点。 生根树是一个带有名为“root”的节点的有向树。 Root没有任何传入边缘,所有其他节点都有一个传入边缘。 这些节点称为叶子或决策节点。 例如,考虑以下决策树以查看某人是否合适。

Support Vector Machine (SVM)
它用于分类和回归问题。 但主要是用于分类问题。 SVM的主要概念是将每个数据项绘制为n维空间中的点,每个特征的值是特定坐标的值。 这里将是我们将拥有的功能。 以下是一个简单的图形表示来理解SVM的概念 -
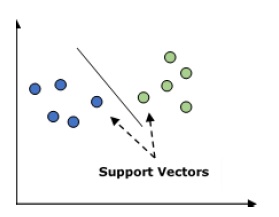
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,其中每个点有两个坐标,称为支持向量。 该行将数据拆分为两个不同的分类组。 这一行是分类器。
朴素贝叶斯
它也是一种分类技术。 这种分类技术背后的逻辑是使用贝叶斯定理来构建分类器。 假设预测变量是独立的。 简单来说,它假定类中特定特征的存在与任何其他特征的存在无关。 下面是贝叶斯定理的等式 -
$$P\left ( \frac{A}{B} \right ) = \frac{P\left ( \frac{B}{A} \right )P\left ( A \right )}{P\left ( B \right )}$$
NaïveBayes模型易于构建,特别适用于大型数据集。
K-Nearest Neighbors (KNN)
它用于问题的分类和回归。 它被广泛用于解决分类问题。 该算法的主要概念是它用于存储所有可用的案例,并通过其k个邻居的多数票来对新案例进行分类。 然后将该情况分配给在其K-最近邻居中最常见的类,通过距离函数测量。 距离函数可以是欧几里德,闵可夫斯基和汉明距离。 考虑以下使用KNN -
计算KNN比用于分类问题的其他算法昂贵。
变量的标准化需要更高范围的变量,否则可能会对其产生偏差。
在KNN中,我们需要处理像噪声消除这样的预处理阶段。
K-Means Clustering
顾名思义,它用于解决聚类问题。 它基本上是一种无监督学习。 K-Means聚类算法的主要逻辑是通过许多聚类对数据集进行分类。 按照以下步骤通过K-means形成集群 -
K-means为称为质心的每个簇选择k个点。
现在每个数据点形成具有最接近的质心的簇,即k个簇。
现在,它将根据现有的集群成员找到每个集群的质心。
我们需要重复这些步骤,直到收敛发生。
随机森林
它是一种监督分类算法。 随机森林算法的优点是它可以用于分类和回归类问题。 基本上它是决策树(即森林)的集合,或者你可以说决策树的集合。 随机森林的基本概念是每棵树都给出一个分类,森林从中选择最佳分类。 以下是随机森林算法的优点 -
随机森林分类器可用于分类和回归任务。
他们可以处理缺失的值。
即使我们在森林中有更多的树木,它也不会过度适应模型。
AI with Python – Data Preparation
我们已经研究了有监督的以及无监督的机器学习算法。 这些算法需要格式化数据才能启动训练过程。 我们必须以某种方式准备或格式化数据,以便它可以作为ML算法的输入提供。
本章重点介绍机器学习算法的数据准备。
预处理数据
在我们的日常生活中,我们处理大量数据,但这些数据是原始形式。 为了提供数据作为机器学习算法的输入,我们需要将其转换为有意义的数据。 这就是数据预处理进入画面的地方。 换句话说,我们可以说在将数据提供给机器学习算法之前,我们需要对数据进行预处理。
数据预处理步骤
按照以下步骤在Python中预处理数据 -
Step 1 − Importing the useful packages - 如果我们使用Python,那么这将是将数据转换为特定格式的第一步,即预处理。 它可以按如下方式完成 -
import numpy as np
import sklearn.preprocessing
这里我们使用了以下两个包 -
NumPy - 基本上NumPy是一个通用的阵列处理软件包,旨在有效地操作任意记录的大型多维数组,而不会为小型多维数组牺牲太多的速度。
Sklearn.preprocessing - 该软件包提供了许多常用的实用程序函数和转换器类,可将原始特征向量更改为更适合机器学习算法的表示形式。
Step 2 − Defining sample data - 导入包后,我们需要定义一些样本数据,以便我们可以对该数据应用预处理技术。 我们现在将定义以下示例数据 -
Input_data = np.array([2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]])
Step3 − Applying preprocessing technique - 在此步骤中,我们需要应用任何预处理技术。
以下部分描述了数据预处理技术。
数据预处理技术
数据预处理技术如下所述 -
二值化(Binarization)
这是我们需要将数值转换为布尔值时使用的预处理技术。 我们可以使用内置方法对输入数据进行二值化,例如以下列方式使用0.5作为阈值 -
data_binarized = preprocessing.Binarizer(threshold = 0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)
现在,在运行上面的代码之后,我们将获得以下输出,所有高于0.5的值(阈值)将被转换为1,并且低于0.5的所有值将被转换为0。
Binarized data
[[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]]
平均删除
这是另一种非常常见的预处理技术,用于机器学习。 基本上它用于消除特征向量的均值,使每个特征都以零为中心。 我们还可以从特征向量中的要素中消除偏差。 为了在样本数据上应用均值删除预处理技术,我们可以编写如下所示的Python代码。 代码将显示输入数据的均值和标准差 -
print("Mean = ", input_data.mean(axis = 0))
print("Std deviation = ", input_data.std(axis = 0))
运行上面的代码行后,我们将获得以下输出 -
Mean = [ 1.75 -1.275 2.2]
Std deviation = [ 2.71431391 4.20022321 4.69414529]
现在,下面的代码将删除输入数据的均值和标准差 -
data_scaled = preprocessing.scale(input_data)
print("Mean =", data_scaled.mean(axis=0))
print("Std deviation =", data_scaled.std(axis = 0))
运行上面的代码行后,我们将获得以下输出 -
Mean = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Std deviation = [ 1. 1. 1.]
Scaling
它是另一种用于缩放特征向量的数据预处理技术。 需要缩放特征向量,因为每个特征的值可以在许多随机值之间变化。 换句话说,我们可以说缩放很重要,因为我们不希望任何特征在合成上变大或变小。 借助以下Python代码,我们可以对输入数据进行缩放,即特征向量 -
# Min max scaling
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)
运行上面的代码行后,我们将获得以下输出 -
Min max scaled data
[ [ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0. 99029126 0. ]]
规范化(Normalization)
它是另一种用于修改特征向量的数据预处理技术。 这种修改对于在共同尺度上测量特征向量是必要的。 以下是两种可用于机器学习的规范化 -
L1 Normalization
它也被称为Least Absolute Deviations 。 这种归一化修改了值,使得每行中绝对值的总和最多为1。 它可以借助以下Python代码在输入数据上实现 -
# Normalize data
data_normalized_l1 = preprocessing.normalize(input_data, norm = 'l1')
print("\nL1 normalized data:\n", data_normalized_l1)
上面的代码行生成以下输出和miuns;
L1 normalized data:
[[ 0.22105263 -0.2 0.57894737]
[ -0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]]
L2 Normalization
它也被称为least squares 。 这种归一化修改了值,使得每行的平方和总是最多为1。 它可以借助以下Python代码在输入数据上实现 -
# Normalize data
data_normalized_l2 = preprocessing.normalize(input_data, norm = 'l2')
print("\nL2 normalized data:\n", data_normalized_l2)
上面的代码行将生成以下输出 -
L2 normalized data:
[[ 0.33946114 -0.30713151 0.88906489]
[ -0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]]
标记数据
我们已经知道,某种格式的数据对于机器学习算法是必要的。 另一个重要的要求是在将数据作为机器学习算法的输入发送之前必须正确标记数据。 例如,如果我们谈论分类,那么数据上就有很多标签。 这些标签采用单词,数字等形式。与sklearn机器学习相关的功能期望数据必须具有数字标签。 因此,如果数据是其他形式,则必须将其转换为数字。 将单词标签转换为数字形式的过程称为标签编码。
标签编码步骤
按照以下步骤在Python中编码数据标签 -
Step1 − Importing the useful packages
如果我们使用Python,那么这将是将数据转换为特定格式(即预处理)的第一步。 它可以按如下方式完成 -
import numpy as np
from sklearn import preprocessing
Step 2 − Defining sample labels
导入包后,我们需要定义一些样本标签,以便我们可以创建和训练标签编码器。 我们现在将定义以下样本标签 -
# Sample input labels
input_labels = ['red','black','red','green','black','yellow','white']
Step 3 − Creating & training of label encoder object
在这一步中,我们需要创建标签编码器并对其进行训练。 以下Python代码将有助于这样做 -
# Creating the label encoder
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)
以下是运行上述Python代码后的输出 -
LabelEncoder()
Step4 − Checking the performance by encoding random ordered list
此步骤可用于通过编码随机有序列表来检查性能。 以下Python代码可以写成相同的 -
# encoding a set of labels
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
标签将打印如下 -
Labels = ['green', 'red', 'black']
现在,我们可以获得编码值列表,即字符标签转换为数字,如下所示 -
print("Encoded values =", list(encoded_values))
编码值将打印如下 -
Encoded values = [1, 2, 0]
Step 5 − Checking the performance by decoding a random set of numbers −
此步骤可用于通过解码随机数字集来检查性能。 以下Python代码可以写成相同的 -
# decoding a set of values
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)
现在,编码值将打印如下 -
Encoded values = [3, 0, 4, 1]
print("\nDecoded labels =", list(decoded_list))
现在,解码后的值将打印如下 -
Decoded labels = ['white', 'black', 'yellow', 'green']
标记的v/s未标记数据
未标记的数据主要包括可以从世界上轻松获得的自然或人造物体的样本。 它们包括音频,视频,照片,新闻文章等。
另一方面,标记数据采用一组未标记的数据,并使用一些有意义的标记或标签或类来增加每个未标记数据。 例如,如果我们有照片,则可以根据照片的内容放置标签,即,它是男孩或女孩或动物的照片或其他任何东西。 标记数据需要人类的专业知识或对给定的未标记数据的判断。
在许多场景中,未标记的数据非常丰富且容易获得,但标记的数据通常需要人/专家进行注释。 半监督学习尝试将标记和未标记数据组合以构建更好的模型。
AI与Python - 监督学习:分类
在本章中,我们将重点关注实施有监督的学习 - 分类。
分类技术或模型试图从观察值中得出一些结论。 在分类问题中,我们有分类输出,如“黑色”或“白色”或“教学”和“非教学”。 在构建分类模型时,我们需要具有包含数据点和相应标签的训练数据集。 例如,如果我们想检查图像是否是汽车。 为了检查这一点,我们将构建一个训练数据集,其中包含与“car”和“no car”相关的两个类。 然后我们需要使用训练样本训练模型。 分类模型主要用于人脸识别,垃圾邮件识别等。
在Python中构建分类器的步骤
为了在Python中构建分类器,我们将使用Python 3和Scikit-learn这是一种机器学习工具。 按照以下步骤在Python中构建分类器 -
第1步 - 导入Scikit-learn
这将是在Python中构建分类器的第一步。 在这一步中,我们将安装一个名为Scikit-learn的Python包,它是Python中最好的机器学习模块之一。 以下命令将帮助我们导入包 -
Import Sklearn
第2步 - 导入Scikit-learn的数据集
在这一步中,我们可以开始使用我们的机器学习模型的数据集。 在这里,我们将使用乳腺癌威斯康星诊断数据库。 该数据集包括关于乳腺癌肿瘤的各种信息,以及malignant或benign分类标签。 该数据集在569个肿瘤上具有569个实例或数据,并且包括关于30个属性或特征的信息,例如肿瘤的半径,纹理,平滑度和面积。 借助以下命令,我们可以导入Scikit-learn的乳腺癌数据集 -
from sklearn.datasets import load_breast_cancer
现在,以下命令将加载数据集。
data = load_breast_cancer()
以下是重要字典键列表 -
- 分类标签名称(target_names)
- The actual labels(target)
- 属性/功能名称(feature_names)
- 属性(数据)
现在,借助以下命令,我们可以为每个重要信息集创建新变量并分配数据。 换句话说,我们可以使用以下命令组织数据 -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
现在,为了更清楚,我们可以借助以下命令打印类标签,第一个数据实例的标签,我们的功能名称和功能的值 -
print(label_names)
上面的命令将分别打印恶意和良性的类名。 它显示为下面的输出 -
['malignant' 'benign']
现在,下面的命令将显示它们被映射到二进制值0和1.这里0代表恶性癌症,1代表良性癌症。 您将收到以下输出 -
print(labels[0])
0
下面给出的两个命令将生成功能名称和功能值。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
从上面的输出中,我们可以看到第一个数据实例是一个半径为1.7990000e + 01的恶性肿瘤。
第3步 - 将数据组织成集
在这一步中,我们将数据分为两部分,即训练集和测试集。 将数据拆分成这些集非常重要,因为我们必须在看不见的数据上测试我们的模型。 要将数据拆分成集合,sklearn有一个名为train_test_split()函数的函数。 借助以下命令,我们可以拆分这些集合中的数据 -
from sklearn.model_selection import train_test_split
上面的命令将从train_test_split导入train_test_split函数,下面的命令会将数据拆分为训练和测试数据。 在下面给出的示例中,我们使用40%的数据进行测试,剩余的数据将用于训练模型。
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
第4步 - 构建模型
在这一步中,我们将构建我们的模型。 我们将使用NaïveBayes算法来构建模型。 以下命令可用于构建模型 -
from sklearn.naive_bayes import GaussianNB
以上命令将导入GaussianNB模块。 现在,以下命令将帮助您初始化模型。
gnb = GaussianNB()
我们将通过使用gnb.fit()将模型拟合到数据来训练模型。
model = gnb.fit(train, train_labels)
第5步 - 评估模型及其准确性
在此步骤中,我们将通过对测试数据进行预测来评估模型。 然后我们也会发现它的准确性。 为了进行预测,我们将使用predict()函数。 以下命令将帮助您执行此操作 -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述系列0和1是肿瘤类别的预测值 - 恶性和良性。
现在,通过比较两个数组,即test_labels和preds ,我们可以找出模型的准确性。 我们将使用accuracy_score()函数来确定准确性。 考虑以下命令 -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
结果表明,NaïveBayes分类器的准确率为95.17%。
通过这种方式,在上述步骤的帮助下,我们可以在Python中构建分类器。
在Python中构建分类器
在本节中,我们将学习如何在Python中构建分类器。
朴素贝叶斯分类器
NaïveBayes是一种分类技术,用于使用贝叶斯定理构建分类器。 假设预测变量是独立的。 简单来说,它假定类中特定特征的存在与任何其他特征的存在无关。 为了构建NaïveBayes分类器,我们需要使用名为scikit learn的python库。 在scikit学习包中有三种类型的NaïveBayes模型,名为Gaussian, Multinomial and Bernoulli 。
要构建NaïveBayes机器学习分类器模型,我们需要以下和减去
Dataset
我们将使用名为Breast Cancer Wisconsin Diagnostic Database的数据集。 该数据集包括关于乳腺癌肿瘤的各种信息,以及malignant或benign分类标签。 该数据集在569个肿瘤上具有569个实例或数据,并且包括关于30个属性或特征的信息,例如肿瘤的半径,纹理,平滑度和面积。 我们可以从sklearn包导入这个数据集。
朴素贝叶斯模型
为了构建NaïveBayes分类器,我们需要一个NaïveBayes模型。 如前所述,在scikit学习包中有三种类型的NaïveBayes模型,分别是Gaussian, Multinomial和Bernoulli 。 在这里,在下面的例子中,我们将使用GaussianNaïveBayes模型。
通过使用上述内容,我们将构建一个NaïveBayes机器学习模型,以使用肿瘤信息来预测肿瘤是恶性还是良性。
首先,我们需要安装sklearn模块。 它可以在以下命令的帮助下完成 -
Import Sklearn
现在,我们需要导入名为Breast Cancer Wisconsin Diagnostic Database的数据集。
from sklearn.datasets import load_breast_cancer
现在,以下命令将加载数据集。
data = load_breast_cancer()
数据可以按如下方式组织 -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
现在,为了更清楚,我们可以借助以下命令打印类标签,第一个数据实例的标签,我们的功能名称和功能的值 -
print(label_names)
上面的命令将分别打印恶意和良性的类名。 它显示为下面的输出 -
['malignant' 'benign']
现在,下面给出的命令将显示它们被映射到二进制值0和1.这里0代表恶性癌症,1代表良性癌症。 它显示为下面的输出 -
print(labels[0])
0
以下两个命令将生成功能名称和功能值。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
从上面的输出中,我们可以看到第一个数据实例是恶性肿瘤,其主要半径是1.7990000e + 01。
为了在看不见的数据上测试我们的模型,我们需要将数据分成训练和测试数据。 它可以在以下代码的帮助下完成 -
from sklearn.model_selection import train_test_split
上面的命令将从train_test_split导入train_test_split函数,下面的命令会将数据拆分为训练和测试数据。 在下面的示例中,我们使用40%的数据进行测试,并且提醒数据将用于训练模型。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)
现在,我们使用以下命令构建模型 -
from sklearn.naive_bayes import GaussianNB
以上命令将导入GaussianNB模块。 现在,使用下面给出的命令,我们需要初始化模型。
gnb = GaussianNB()
我们将通过使用gnb.fit()将模型拟合到数据来训练模型。
model = gnb.fit(train, train_labels)
现在,通过对测试数据进行预测来评估模型,并且可以按如下方式进行 -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述系列0和1是肿瘤类别的预测值,即恶性和良性。
现在,通过比较两个数组,即test_labels和preds ,我们可以找出模型的准确性。 我们将使用accuracy_score()函数来确定准确性。 考虑以下命令 -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
结果表明,NaïveBayes分类器的准确率为95.17%。
那是基于NaïveBayseGaussian模型的机器学习分类器。
Support Vector Machines (SVM)
基本上,支持向量机(SVM)是一种监督机器学习算法,可用于回归和分类。 SVM的主要概念是将每个数据项绘制为n维空间中的点,每个特征的值是特定坐标的值。 这里将是我们将拥有的功能。 以下是一个简单的图形表示来理解SVM的概念 -
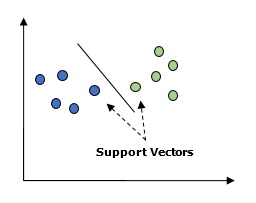
在上图中,我们有两个功能。 因此,我们首先需要在二维空间中绘制这两个变量,其中每个点有两个坐标,称为支持向量。 该行将数据拆分为两个不同的分类组。 这一行是分类器。
在这里,我们将使用scikit-learn和iris数据集构建SVM分类器。 Scikitlearn库具有sklearn.svm模块,并提供sklearn.svm.svc用于分类。 基于4个特征预测虹膜植物类别的SVM分类器如下所示。
Dataset
我们将使用虹膜数据集,其中包含3个类别,每个类别包含50个实例,其中每个类别指的是一种虹膜植物。 每个实例都有四个特征,即萼片长度,萼片宽度,花瓣长度和花瓣宽度。 基于4个特征预测虹膜植物种类的SVM分类器如下所示。
Kernel
这是SVM使用的技术。 基本上这些是采用低维输入空间并将其转换为更高维空间的函数。 它将不可分离的问题转换为可分离的问题。 内核函数可以是线性,多项式,rbf和sigmoid中的任何一个。 在这个例子中,我们将使用线性内核。
现在让我们导入以下包 -
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt
现在,加载输入数据 -
iris = datasets.load_iris()
我们正在采取前两个功能 -
X = iris.data[:, :2]
y = iris.target
我们将用原始数据绘制支持向量机边界。 我们正在创建一个网格来绘制。
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max/x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
我们需要给出正则化参数的值。
C = 1.0
我们需要创建SVM分类器对象。
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
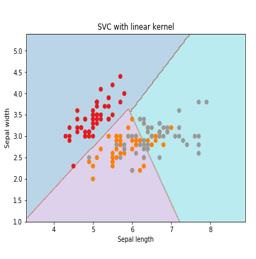
plt.title('SVC with linear kernel')
Logistic回归
基本上,逻辑回归模型是监督分类算法族的成员之一。 Logistic回归通过使用逻辑函数估计概率来测量因变量和自变量之间的关系。
在这里,如果我们讨论依赖变量和自变量,那么因变量是我们要预测的目标类变量,另一方面,自变量是我们将用于预测目标类的特征。
在逻辑回归中,估计概率意味着预测事件的可能发生。 例如,店主想要预测进入商店的顾客将购买游戏站(例如)。 将存在许多客户特征 - 性别,年龄等,商店管理员将观察到这些特征以预测可能性发生,即是否购买游戏站。 逻辑函数是sigmoid曲线,用于构建具有各种参数的函数。
先决条件 (Prerequisites)
在使用逻辑回归构建分类器之前,我们需要在我们的系统上安装Tkinter包。 它可以从https://docs.python.org/2/library/tkinter.html安装。
现在,借助下面给出的代码,我们可以使用逻辑回归创建一个分类器 -
首先,我们将导入一些包 -
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
现在,我们需要定义样本数据,可以按如下方式完成 -
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
接下来,我们需要创建逻辑回归分类器,可以按如下方式完成 -
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)
最后但并非最不重要,我们需要训练这个分类器 -
Classifier_LR.fit(X, y)
现在,我们如何可视化输出? 可以通过创建名为Logistic_visualize()的函数来完成 -
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0
在上面的行中,我们定义了在网格中使用的最小和最大值X和Y. 此外,我们将定义用于绘制网格网格的步长。
mesh_step_size = 0.02
让我们定义X和Y值的网格,如下所示 -
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))
借助以下代码,我们可以在网格上运行分类器 -
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)
以下代码行将指定绘图的边界
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()
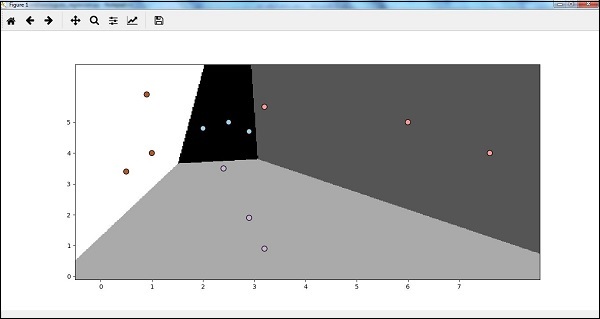
现在,在运行代码后,我们将获得以下输出,逻辑回归分类器 -
决策树分类器
决策树基本上是二叉树流程图,其中每个节点根据一些特征变量分割一组观察。
在这里,我们正在构建一个决策树分类器,用于预测男性或女性。 我们将采用一个包含19个样本的非常小的数据集。 这些样本将包括两个特征 - “高度”和“头发长度”。
先决条件(Prerequisite)
要构建以下分类器,我们需要安装pydotplus和graphviz 。 基本上,graphviz是使用点文件绘制图形的工具,而pydotplus是Graphviz的Dot语言的模块。 它可以与包管理器或pip一起安装。
现在,我们可以借助以下Python代码构建决策树分类器 -
首先,让我们导入一些重要的库,如下所示 -
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collections
现在,我们需要提供如下数据集 -
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)
在提供数据集之后,我们需要拟合可以如下完成的模型 -
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)
可以借助以下Python代码进行预测 -
prediction = clf.predict([[133,37]])
print(prediction)
我们可以借助以下Python代码可视化决策树 -
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')
它将上述代码的预测作为['Woman']并创建以下决策树 -

我们可以更改预测中的要素值来测试它。
随机森林分类器
我们知道集合方法是将机器学习模型组合成更强大的机器学习模型的方法。 随机森林是决策树的集合,是其中之一。 它优于单一决策树,因为在保留预测能力的同时,它可以通过平均结果来减少过度拟合。 在这里,我们将在scikit学习癌症数据集上实施随机森林模型。
导入必要的包裹 -
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as np
现在,我们需要提供可以按以下方式完成的数据集
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)
在提供数据集之后,我们需要拟合可以如下完成的模型 -
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)
现在,获得训练和测试子集的准确性:如果我们将增加估计量的数量,那么测试子集的准确性也将增加。
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))
输出 (Output)
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965
现在,与决策树一样,随机森林具有feature_importance模块,该模块将提供比决策树更好的特征权重视图。 它可以是情节和可视化如下 -
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
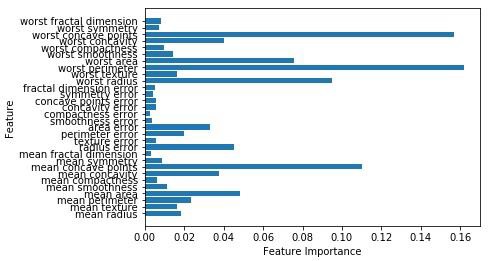
分类器的性能
在实现机器学习算法之后,我们需要找出模型的有效性。 衡量有效性的标准可以基于数据集和度量。 为了评估不同的机器学习算法,我们可以使用不同的性能指标。 例如,假设如果使用分类器来区分不同对象的图像,我们可以使用分类性能度量,例如平均准确度,AUC等。在一种或另一种意义上,我们选择评估机器学习模型的度量是非常重要,因为度量的选择会影响如何测量和比较机器学习算法的性能。 以下是一些指标 -
混乱矩阵
基本上它用于分类问题,其中输出可以是两种或更多种类。 这是衡量分类器性能的最简单方法。 混淆矩阵基本上是具有两个维度的表,即“实际”和“预测”。 这两个维度都具有“真阳性(TP)”,“真阴性(TN)”,“假阳性(FP)”,“假阴性(FN)”。
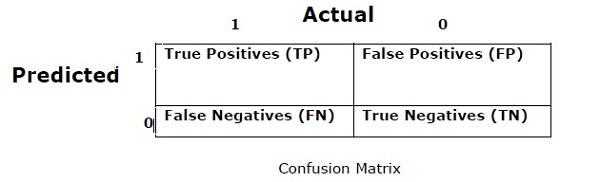
在上面的混淆矩阵中,1表示正类,0表示负类。
以下是与混淆矩阵相关的术语 -
True Positives − TP是实际的数据点类为1且预测值也为1的情况。
True Negatives − TN是数据点的实际类为0且预测值也为0的情况。
False Positives − FP是实际的数据点类为0且预测值也为1的情况。
False Negatives − FN是数据点的实际类为1且预测值也为0的情况。
Accuracy
混淆矩阵本身不是这样的性能度量,但几乎所有的性能矩阵都基于混淆矩阵。 其中之一就是准确性。 在分类问题中,它可以定义为模型对所做的各种预测所做的正确预测的数量。 计算准确度的公式如下 -
$$Accuracy = \frac{TP+TN}{TP+FP+FN+TN}$$
精度(Precision)
它主要用于文档检索。 它可以定义为返回的文档中有多少是正确的。 以下是计算精度的公式 -
$$Precision = \frac{TP}{TP+FP}$$
召回或敏感
它可以定义为模型返回多少个正数。 以下是计算模型召回/灵敏度的公式 -
$$Recall = \frac{TP}{TP+FN}$$
特异性(Specificity)
它可以定义为模型返回的负数有多少。 这与召回完全相反。 以下是计算模型特异性的公式 -
$$Specificity = \frac{TN}{TN+FP}$$
阶级失衡问题
类不平衡是属于一个类的观察数量明显低于属于其他类的观察数量的情况。 例如,在我们需要识别罕见疾病,银行欺诈交易等情况下,这个问题非常突出。
不平衡类的示例
让我们考虑欺诈检测数据集的一个例子来理解不平衡类的概念 -
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
解决方案 (Solution)
Balancing the classes'作用是解决不平衡的类。 平衡阶级的主要目的是增加少数群体的频率或减少多数群体的频率。 以下是解决不平衡类问题的方法 -
Re-Sampling
重新采样是一系列用于重建样本数据集的方法 - 训练集和测试集。 重新采样以提高模型的准确性。 以下是一些重新采样技术 -
Random Under-Sampling欠Random Under-Sampling - 该技术旨在通过随机删除多数类示例来平衡类分布。 这样做是在大多数和少数类实例平衡之前完成的。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
在这种情况下,我们在没有替换非欺诈实例的情况下获取10%的样本,然后将它们与欺诈实例相结合 -
随机抽样后的非欺诈性观察= 4950的10%= 495
将它们与欺诈性观察结合后的总观察值= 50 + 495 = 545
因此,现在,采样后新数据集的事件率= 9%
该技术的主要优点是它可以减少运行时间并改善存储。 但另一方面,它可以丢弃有用的信息,同时减少训练数据样本的数量。
Random Over-Sampling - 该技术旨在通过复制少数类中的实例数来平衡类分布。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
如果我们复制50次欺诈性观察30次,那么在复制少数类观测后的欺诈性观测将是1500次。然后在过采样后新数据中的总观测值将是4950 + 1500 = 6450.因此新数据集的事件率将是1500/6450 = 23%。
这种方法的主要优点是不会丢失有用的信息。 但另一方面,它过度拟合的可能性增加,因为它复制了少数民族阶级的事件。
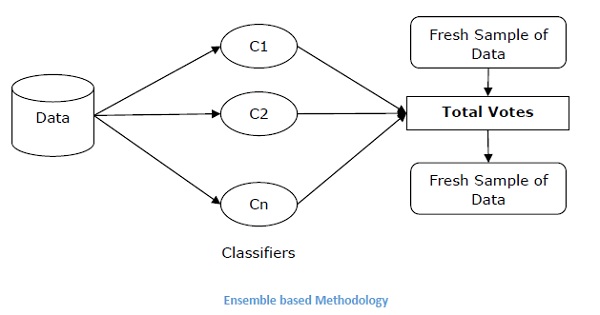
合奏技巧
该方法基本上用于修改现有的分类算法,使其适用于不平衡的数据集。 在这种方法中,我们从原始数据构造几个两阶段分类器,然后汇总它们的预测。 随机森林分类器是基于集合的分类器的示例。
AI与Python - 监督学习:回归
回归是最重要的统计和机器学习工具之一。 我们说机器学习之旅从回归开始就没有错。 它可以被定义为允许我们基于数据做出决策的参数技术,或者换句话说,允许我们通过学习输入和输出变量之间的关系来基于数据进行预测。 这里,依赖于输入变量的输出变量是连续值实数。 在回归中,输入和输出变量之间的关系很重要,它有助于我们理解输出变量的值如何随输入变量的变化而变化。 回归经常用于预测价格,经济,变化等。
用Python构建回归量
在本节中,我们将学习如何构建单变量和多变量回归量。
线性回归器/单变量回归器
让我们重要一些必要的包 -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
现在,我们需要提供输入数据,并将数据保存在名为linear.txt的文件中。
input = 'D:/ProgramData/linear.txt'
我们需要使用np.loadtxt函数加载这些数据。
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]
下一步是训练模型。 让我们提供培训和测试样品。
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]
现在,我们需要创建一个线性回归量对象。
reg_linear = linear_model.LinearRegression()
使用训练样本训练对象。
reg_linear.fit(X_train, y_train)
我们需要用测试数据进行预测。
y_test_pred = reg_linear.predict(X_test)
现在绘制并可视化数据。
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_test, y_test_pred, color = 'black', linewidth = 2)
plt.xticks(())
plt.yticks(())
plt.show()
输出 (Output)
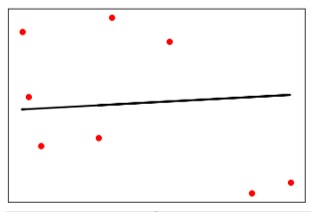
现在,我们可以计算线性回归的性能如下 -
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred),
2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
输出 (Output)
线性回归器的性能 -
Mean absolute error = 1.78
Mean squared error = 3.89
Median absolute error = 2.01
Explain variance score = -0.09
R2 score = -0.09
在上面的代码中,我们使用了这个小数据。 如果您想要一些大数据集,那么您可以使用sklearn.dataset导入更大的数据集。
2,4.82.9,4.72.5,53.2,5.56,57.6,43.2,0.92.9,1.92.4,
3.50.5,3.41,40.9,5.91.2,2.583.2,5.65.1,1.54.5,
1.22.3,6.32.1,2.8
多变量回归量
首先,让我们导入一些必需的包 -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
现在,我们需要提供输入数据,并将数据保存在名为linear.txt的文件中。
input = 'D:/ProgramData/Mul_linear.txt'
我们将使用np.loadtxt函数加载此数据。
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]
下一步是培训模型; 我们将提供培训和测试样品。
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]
现在,我们需要创建一个线性回归量对象。
reg_linear_mul = linear_model.LinearRegression()
使用训练样本训练对象。
reg_linear_mul.fit(X_train, y_train)
现在,最后我们需要用测试数据进行预测。
y_test_pred = reg_linear_mul.predict(X_test)
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
输出 (Output)
线性回归器的性能 -
Mean absolute error = 0.6
Mean squared error = 0.65
Median absolute error = 0.41
Explain variance score = 0.34
R2 score = 0.33
现在,我们将创建一个10度的多项式并训练回归量。 我们将提供示例数据点。
polynomial = PolynomialFeatures(degree = 10)
X_train_transformed = polynomial.fit_transform(X_train)
datapoint = [[2.23, 1.35, 1.12]]
poly_datapoint = polynomial.fit_transform(datapoint)
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(X_train_transformed, y_train)
print("\nLinear regression:\n", reg_linear_mul.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))
输出 (Output)
线性回归 -
[2.40170462]
多项式回归 -
[1.8697225]
在上面的代码中,我们使用了这个小数据。 如果您想要大数据集,则可以使用sklearn.dataset导入更大的数据集。
2,4.8,1.2,3.22.9,4.7,1.5,3.62.5,5,2.8,23.2,5.5,3.5,2.16,5,
2,3.27.6,4,1.2,3.23.2,0.9,2.3,1.42.9,1.9,2.3,1.22.4,3.5,
2.8,3.60.5,3.4,1.8,2.91,4,3,2.50.9,5.9,5.6,0.81.2,2.58,
3.45,1.233.2,5.6,2,3.25.1,1.5,1.2,1.34.5,1.2,4.1,2.32.3,
6.3,2.5,3.22.1,2.8,1.2,3.6
AI with Python – Logic Programming
在本章中,我们将重点介绍逻辑编程及其在人工智能中的作用。
我们已经知道逻辑是对正确推理原则的研究,或者用简单的话来说就是对什么之后的研究。 例如,如果两个语句都为真,那么我们可以从中推断出任何第三个语句。
概念 (Concept)
逻辑编程是两个词,逻辑和编程的组合。 逻辑编程是一种编程范式,其中问题通过程序语句表达为事实和规则,但在形式逻辑系统中。 就像面向对象,功能,声明和程序等其他编程范例一样,它也是一种处理编程的特殊方法。
如何解决逻辑程序设计问题
逻辑编程使用事实和规则来解决问题。 这就是为什么它们被称为逻辑编程的构建模块。 需要为逻辑编程中的每个程序指定一个目标。 要理解如何在逻辑编程中解决问题,我们需要了解构建块 - 事实和规则 -
Facts
实际上,每个逻辑程序都需要使用事实才能实现给定的目标。 事实基本上是关于程序和数据的真实陈述。 例如,德里是印度的首都。
规则 (Rules)
实际上,规则是允许我们对问题域做出结论的约束。 规则基本上写成逻辑条款来表达各种事实。 例如,如果我们正在构建任何游戏,那么必须定义所有规则。
规则对于解决逻辑编程中的任何问题非常重要。 规则基本上是逻辑结论,可以表达事实。 以下是规则的语法 -
A: - B1,B2,...,B n 。
这里,A是头部,B1,B2,...... Bn是身体。
例如 - 祖先(X,Y): - 父亲(X,Y)。
祖先(X,Z): - 父亲(X,Y),祖先(Y,Z)。
这可以理解为,对于每个X和Y,如果X是Y的父亲而Y是Z的祖先,则X是Z的祖先。对于每个X和Y,X是Z的祖先,如果X是Y和Y的父亲是Z的祖先。
安装有用的包
要在Python中启动逻辑编程,我们需要安装以下两个包 -
Kanren
它为我们提供了一种简化业务逻辑代码编写方式的方法。 它让我们用规则和事实来表达逻辑。 以下命令将帮助您安装kanren -
pip install kanren
SymPy
SymPy是一个用于符号数学的Python库。 它旨在成为一个功能齐全的计算机代数系统(CAS),同时保持代码尽可能简单,以便易于理解和易于扩展。 以下命令将帮助您安装SymPy -
pip install sympy
逻辑编程的例子
以下是一些可以通过逻辑编程解决的例子 -
匹配数学表达式
实际上,我们可以通过非常有效的方式使用逻辑编程来找到未知值。 以下Python代码将帮助您匹配数学表达式 -
考虑首先导入以下包 -
from kanren import run, var, fact
from kanren.assoccomm import eq_assoccomm as eq
from kanren.assoccomm import commutative, associative
我们需要定义我们将要使用的数学运算 -
add = 'add'
mul = 'mul'
加法和乘法都是交际过程。 因此,我们需要指定它,这可以按如下方式完成 -
fact(commutative, mul)
fact(commutative, add)
fact(associative, mul)
fact(associative, add)
定义变量是强制性的; 这可以按如下方式完成 -
a, b = var('a'), var('b')
我们需要将表达式与原始模式匹配。 我们有以下原始模式,基本上是(5 + a)* b -
Original_pattern = (mul, (add, 5, a), b)
我们有以下两个表达式与原始模式匹配 -
exp1 = (mul, 2, (add, 3, 1))
exp2 = (add,5,(mul,8,1))
可以使用以下命令打印输出 -
print(run(0, (a,b), eq(original_pattern, exp1)))
print(run(0, (a,b), eq(original_pattern, exp2)))
运行此代码后,我们将获得以下输出 -
((3,2))
()
第一个输出表示a和b的值。 第一个表达式与原始模式匹配并返回a和b的值,但第二个表达式与原始模式不匹配,因此没有返回任何内容。
检查素数
在逻辑编程的帮助下,我们可以从数字列表中找到素数,也可以生成素数。 下面给出的Python代码将从数字列表中找到素数,并且还将生成前10个素数。
我们首先考虑导入以下包 -
from kanren import isvar, run, membero
from kanren.core import success, fail, goaleval, condeseq, eq, var
from sympy.ntheory.generate import prime, isprime
import itertools as it
现在,我们将定义一个名为prime_check的函数,该函数将根据给定的数字检查素数作为数据。
def prime_check(x):
if isvar(x):
return condeseq([(eq,x,p)] for p in map(prime, it.count(1)))
else:
return success if isprime(x) else fail
现在,我们需要声明一个将要使用的变量 -
x = var()
print((set(run(0,x,(membero,x,(12,14,15,19,20,21,22,23,29,30,41,44,52,62,65,85)),
(prime_check,x)))))
print((run(10,x,prime_check(x))))
以上代码的输出如下 -
{19, 23, 29, 41}
(2, 3, 5, 7, 11, 13, 17, 19, 23, 29)
解决难题
逻辑编程可用于解决许多问题,如8-puzzles,Zebra puzzle,Sudoku,N-queen等。这里我们举一个Zebra拼图变体的例子如下 -
There are five houses.
The English man lives in the red house.
The Swede has a dog.
The Dane drinks tea.
The green house is immediately to the left of the white house.
They drink coffee in the green house.
The man who smokes Pall Mall has birds.
In the yellow house they smoke Dunhill.
In the middle house they drink milk.
The Norwegian lives in the first house.
The man who smokes Blend lives in the house next to the house with cats.
In a house next to the house where they have a horse, they smoke Dunhill.
The man who smokes Blue Master drinks beer.
The German smokes Prince.
The Norwegian lives next to the blue house.
They drink water in a house next to the house where they smoke Blend.
我们正在解决它在Python的帮助下who owns zebra的问题。
让我们导入必要的包 -
from kanren import *
from kanren.core import lall
import time
现在,我们需要定义两个函数 - left()和next()来检查谁的房子左边或旁边的房子 -
def left(q, p, list):
return membero((q,p), zip(list, list[1:]))
def next(q, p, list):
return conde([left(q, p, list)], [left(p, q, list)])
现在,我们将如下声明一个可变房屋 -
houses = var()
我们需要在lall包的帮助下定义规则,如下所示。
有5个房子 -
rules_zebraproblem = lall(
(eq, (var(), var(), var(), var(), var()), houses),
(membero,('Englishman', var(), var(), var(), 'red'), houses),
(membero,('Swede', var(), var(), 'dog', var()), houses),
(membero,('Dane', var(), 'tea', var(), var()), houses),
(left,(var(), var(), var(), var(), 'green'),
(var(), var(), var(), var(), 'white'), houses),
(membero,(var(), var(), 'coffee', var(), 'green'), houses),
(membero,(var(), 'Pall Mall', var(), 'birds', var()), houses),
(membero,(var(), 'Dunhill', var(), var(), 'yellow'), houses),
(eq,(var(), var(), (var(), var(), 'milk', var(), var()), var(), var()), houses),
(eq,(('Norwegian', var(), var(), var(), var()), var(), var(), var(), var()), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), var(), 'cats', var()), houses),
(next,(var(), 'Dunhill', var(), var(), var()),
(var(), var(), var(), 'horse', var()), houses),
(membero,(var(), 'Blue Master', 'beer', var(), var()), houses),
(membero,('German', 'Prince', var(), var(), var()), houses),
(next,('Norwegian', var(), var(), var(), var()),
(var(), var(), var(), var(), 'blue'), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), 'water', var(), var()), houses),
(membero,(var(), var(), var(), 'zebra', var()), houses)
)
现在,使用前面的约束运行求解器 -
solutions = run(0, houses, rules_zebraproblem)
借助以下代码,我们可以从求解器中提取输出 -
output_zebra = [house for house in solutions[0] if 'zebra' in house][0][0]
以下代码将有助于打印解决方案 -
print ('\n'+ output_zebra + 'owns zebra.')
上述代码的输出如下 -
German owns zebra.
AI与Python - 无监督学习:聚类
无监督机器学习算法没有任何主管提供任何形式的指导。 这就是为什么它们与某些人称之为真正的人工智能紧密结合的原因。
在无人监督的学习中,没有正确的答案,也没有教师的指导。 算法需要在数据中发现有趣的模式以供学习。
什么是聚类?
基本上,它是一种无监督学习方法和用于许多领域的统计数据分析的常用技术。 聚类主要是将观察集划分为子集(称为聚类)的任务,使得同一聚类中的观察在一种意义上是相似的,并且它们与其他聚类中的观察不同。 简单来说,我们可以说聚类的主要目标是在相似性和相异性的基础上对数据进行分组。
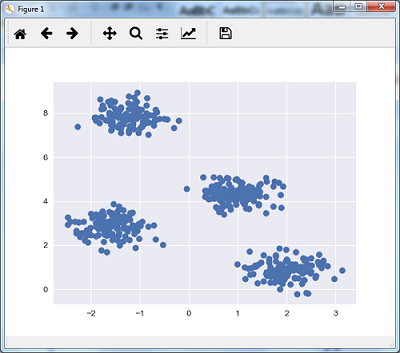
例如,下图显示了不同集群中的类似数据 -
聚类数据的算法
以下是一些用于聚类数据的常用算法 -
K-Means algorithm
K均值聚类算法是用于聚类数据的众所周知的算法之一。 我们需要假设群集的数量已经知道。 这也称为平面聚类。 它是一种迭代聚类算法。 此算法需要遵循以下步骤 -
Step 1 - 我们需要指定所需的K个子组数。
Step 2 - 修复群集数量并将每个数据点随机分配给群集。 或者换句话说,我们需要根据集群的数量对数据进行分类。
在此步骤中,应计算聚类质心。
由于这是一个迭代算法,我们需要在每次迭代时更新K质心的位置,直到我们找到全局最优或换句话说质心到达其最佳位置。
以下代码将有助于在Python中实现K-means聚类算法。 我们将使用Scikit-learn模块。
让我们导入必要的包 -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
以下代码行将通过使用sklearn.dataset包中的make_blob来帮助生成包含四个blob的二维数据集。
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)
我们可以使用以下代码可视化数据集 -
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
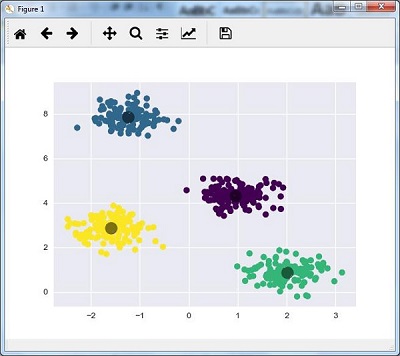
在这里,我们将kmeans初始化为KMeans算法,其中包含多少个簇(n_clusters)的必需参数。
kmeans = KMeans(n_clusters = 4)
我们需要用输入数据训练K-means模型。
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_
下面给出的代码将帮助我们根据我们的数据绘制和可视化机器的发现,并根据要找到的簇的数量来拟合。
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
均值漂移算法
它是无监督学习中使用的另一种流行且强大的聚类算法。 它没有做出任何假设,因此它是一个非参数算法。 它也称为层次聚类或均值移位聚类分析。 以下是此算法的基本步骤 -
首先,我们需要从分配给自己的集群的数据点开始。
现在,它计算质心并更新新质心的位置。
通过重复这个过程,我们移近群集的峰值,即朝向更高密度的区域。
该算法在质心不再移动的阶段停止。
在下面的代码的帮助下,我们在Python中实现了Mean Shift聚类算法。 我们将使用Scikit-learn模块。
让我们导入必要的包 -
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
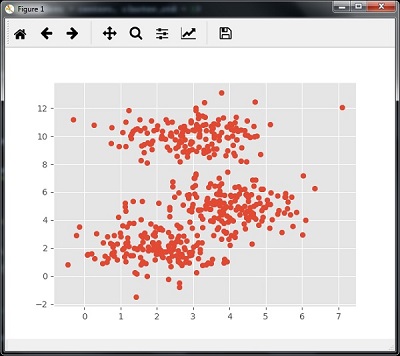
以下代码将通过使用sklearn.dataset包中的make_blob来帮助生成包含四个blob的二维数据集。
from sklearn.datasets.samples_generator import make_blobs
我们可以使用以下代码可视化数据集
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
现在,我们需要使用输入数据训练Mean Shift群集模型。
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
以下代码将根据输入数据打印集群中心和预期的集群数 -
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2
下面给出的代码将帮助根据我们的数据绘制和可视化机器的发现,并根据要找到的聚类数量来拟合。
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
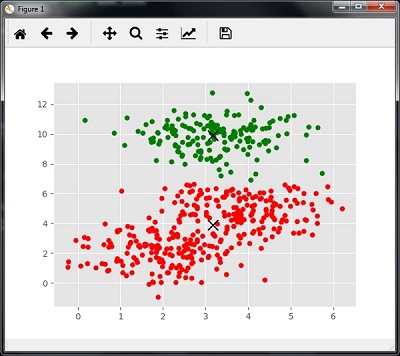
测量聚类性能
现实世界的数据并不是自然地组织成许多独特的集群。 由于这个原因,想象和绘制推论并不容易。 这就是我们需要测量聚类性能及其质量的原因。 它可以在轮廓分析的帮助下完成。
剪影分析
该方法可用于通过测量簇之间的距离来检查聚类的质量。 基本上,它提供了一种通过给出轮廓分数来评估诸如聚类数量之类的参数的方法。 该分数是衡量一个群集中每个点与相邻群集中的点的接近程度的度量。
剪影分数分析
得分的范围为[-1,1]。 以下是对这个分数的分析 -
Score of +1 - 分数接近+1表示样本远离相邻群集。
Score of 0 - 得分0表示样本处于或非常接近两个相邻聚类之间的决策边界。
Score of -1 - 负分数表示样本已分配到错误的群集。
计算剪影分数
在本节中,我们将学习如何计算轮廓分数。
剪影分数可以使用以下公式计算 -
$$silhouette score = \frac{\left ( p-q \right )}{max\left ( p,q \right )}$$
这里,ð'是到数据点不属于的最近集群中的点的平均距离。 并且,ð''是到其自己的集群中所有点的平均集群内距离。
为了找到最佳簇数,我们需要通过从sklearn包导入metrics模块再次运行聚类算法。 在下面的示例中,我们将运行K-means聚类算法以查找最佳聚类数 -
如图所示导入必要的包 -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
在以下代码的帮助下,我们将使用sklearn.dataset包中的sklearn.dataset生成包含四个blob的二维数据集。
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)
初始化变量如图所示 -
scores = []
values = np.arange(2, 10)
我们需要通过所有值迭代K-means模型,并且还需要使用输入数据对其进行训练。
for num_clusters in values:
kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10)
kmeans.fit(X)
现在,使用欧几里德距离度量估计当前聚类模型的轮廓得分 -
score = metrics.silhouette_score(X, kmeans.labels_,
metric = 'euclidean', sample_size = len(X))
以下代码行将有助于显示群集数量和Silhouette分数。
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)
您将收到以下输出 -
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)
现在,最佳簇数的输出如下 -
Optimal number of clusters = 2
找到最近的邻居
如果我们想要建立诸如电影推荐系统之类的推荐系统,那么我们需要理解寻找最近邻居的概念。 这是因为推荐系统利用了最近邻居的概念。
concept of finding nearest neighbors的concept of finding nearest neighbors可以被定义为从给定数据集中找到与输入点的最近点的过程。 该KNN)K-最近邻居算法的主要用途是构建分类系统,该分类系统将输入数据点附近的数据点分类为各种类。
下面给出的Python代码有助于找到给定数据集的K最近邻居 -
导入必要的包,如下所示。 在这里,我们使用sklearn包中的NearestNeighbors模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighbors
现在让我们定义输入数据 -
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])
现在,我们需要定义最近的邻居 -
k = 3
我们还需要提供测试数据,从中找到最近的邻居 -
test_data = [3.3, 2.9]
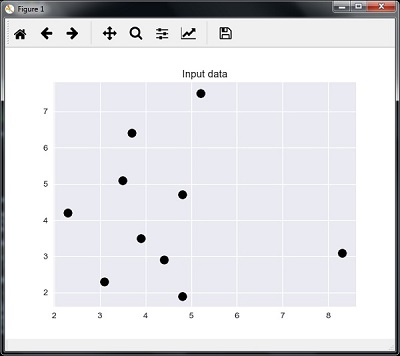
以下代码可以显示和绘制我们定义的输入数据 -
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
现在,我们需要构建K最近邻。 该对象也需要训练
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X)
distances, indices = knn_model.kneighbors([test_data])
现在,我们可以按如下方式打印K个最近邻居
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])
我们可以将最近的邻居与测试数据点一起可视化
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
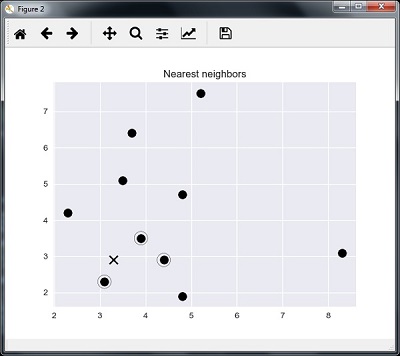
输出 (Output)
K Nearest Neighbors
1 is [ 3.1 2.3]
2 is [ 3.9 3.5]
3 is [ 4.4 2.9]
K-Nearest Neighbors Classifier
K-Nearest Neighbors(KNN)分类器是一种分类模型,它使用最近邻算法对给定数据点进行分类。 我们在上一节中已经实现了KNN算法,现在我们将使用该算法构建KNN分类器。
KNN分类器的概念
K-最近邻分类的基本概念是找到与新样本距离最近的训练样本的预定义数,即“k”,其必须被分类。 新样本将从邻居本身获得他们的标签。 KNN分类器具有固定的用户定义的常数,用于必须确定的邻居的数量。 对于距离,标准欧几里德距离是最常见的选择。 KNN分类器直接在学习的样本上工作,而不是创建学习规则。 KNN算法是所有机器学习算法中最简单的算法之一。 它在大量分类和回归问题中非常成功,例如字符识别或图像分析。
Example
我们正在构建一个KNN分类器来识别数字。 为此,我们将使用MNIST数据集。 我们将在Jupyter Notebook中编写此代码。
导入必要的包,如下所示。
这里我们使用sklearn.neighbors包中的KNeighborsClassifier模块 -
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np
以下代码将显示数字图像以验证我们要测试的图像 -
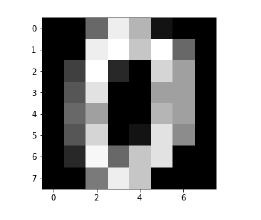
def Image_display(i):
plt.imshow(digit['images'][i],cmap = 'Greys_r')
plt.show()
现在,我们需要加载MNIST数据集。 实际上总共有1797个图像,但我们使用前1600个图像作为训练样本,剩下的197个图像将用于测试目的。
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])
现在,在显示图像时,我们可以看到输出如下 -
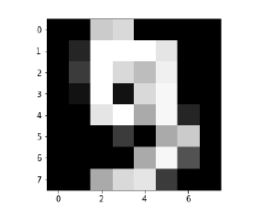
Image_display(0)
Image_display(0)
0的图像显示如下 -
Image_display(9)
9的图像显示如下 -
digit.keys()
现在,我们需要创建训练和测试数据集,并为KNN分类器提供测试数据集。
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x,train_y)
以下输出将创建K最近邻分类器构造函数 -
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')
我们需要通过提供大于1600的任意数字来创建测试样本,这是训练样本。
test = np.array(digit['data'][1725])
test1 = test.reshape(1,-1)
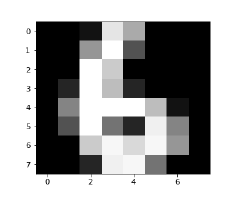
Image_display(1725)
Image_display(6)
6的图像显示如下 -
现在我们将预测测试数据如下 -
KNN.predict(test1)
上面的代码将生成以下输出 -
array([6])
现在,考虑以下 -
digit['target_names']
上面的代码将生成以下输出 -
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
AI与Python - 自然语言处理
自然语言处理(NLP)是指使用诸如英语之类的自然语言与智能系统通信的AI方法。
当您希望像机器人这样的智能系统按照您的指示执行,当您想要听取基于对话的临床专家系统的决定等时,需要处理自然语言。
NLP领域涉及使计算机使用人类使用的自然语言来完成有用的任务。 NLP系统的输入和输出可以是 -
- Speech
- 书面文字
NLP的组成部分
在本节中,我们将了解NLP的不同组件。 NLP有两个组成部分。 组件如下所述 -
Natural Language Understanding (NLU)
它涉及以下任务 -
将自然语言中的给定输入映射到有用的表示中。
分析语言的不同方面。
Natural Language Generation (NLG)
它是从一些内部表征中以自然语言的形式产生有意义的短语和句子的过程。 它涉及 -
Text planning - 这包括从知识库中检索相关内容。
Sentence planning - 这包括选择所需的单词,形成有意义的短语,设置句子的语气。
Text Realization - 这是将句子计划映射到句子结构。
NLU的困难
NLU的形式和结构非常丰富; 然而,这是模棱两可的。 可能存在不同程度的歧义 -
词汇含糊不清
它处于非常原始的层面,例如词级。 例如,将单词“board”视为名词还是动词?
语法级别歧义
句子可以用不同的方式解析。 例如,“他用红帽盖住了甲虫。” - 他是否用帽子抬起甲虫,或者他举起了一顶戴红帽的甲虫?
参考模糊
用代词指代某事。 例如,Rima去了Gauri。 她说,“我累了。” - 究竟谁累了?
NLP术语
现在让我们看一下NLP术语中的一些重要术语。
Phonology - 系统地组织声音的研究。
Morphology - 它是从原始有意义的单位构建单词的研究。
Morpheme - 它是语言中意义的原始单位。
Syntax - 它指的是排列单词来创建一个句子。 它还涉及确定句子和短语中单词的结构作用。
Semantics - 它关注单词的含义以及如何将单词组合成有意义的短语和句子。
Pragmatics - 它涉及在不同情境下使用和理解句子以及如何对句子的解释产生影响。
Discourse - 它处理紧接在前的句子如何影响下一句的解释。
World Knowledge - 它包括有关世界的一般知识。
NLP中的步骤
本节介绍NLP中的不同步骤。
词汇分析
它涉及识别和分析单词的结构。 语言的词典意味着语言中的单词和短语的集合。 词法分析将整个txt块分为段落,句子和单词。
Syntactic Analysis (Parsing)
它包括对句子中的单词进行语法分析,并以一种显示单词之间关系的方式排列单词。 “学校去男孩”这样的句子被英语句法分析器拒绝。
语义分析
它从文本中得出确切的含义或字典含义。 检查文本是否有意义。 它通过映射任务域中的语法结构和对象来完成。 语义分析器忽视诸如“热冰淇淋”之类的句子。
话语整合
任何句子的含义取决于它之前的句子的含义。 此外,它还带来了紧接着的句子的含义。
语用分析
在此期间,所说的内容被重新解释为它的实际含义。 它涉及推导需要现实世界知识的语言方面。
AI with Python – NLTK Package
在本章中,我们将学习如何开始使用Natural Language Toolkit Package。
先决条件(Prerequisite)
如果我们想用自然语言处理来构建应用程序,那么上下文的变化会使其变得非常困难。 上下文因素影响机器如何理解特定句子。 因此,我们需要使用机器学习方法开发自然语言应用程序,以便机器也能理解人类理解上下文的方式。
要构建这样的应用程序,我们将使用名为NLTK(Natural Language Toolkit Package)的Python包。
导入NLTK
我们需要在使用之前安装NLTK。 它可以在以下命令的帮助下安装 -
pip install nltk
要为NLTK构建conda包,请使用以下命令 -
conda install -c anaconda nltk
现在安装NLTK包后,我们需要通过python命令提示符导入它。 我们可以通过在Python命令提示符下编写以下命令来导入它 -
>>> import nltk
下载NLTK的数据
现在导入NLTK后,我们需要下载所需的数据。 它可以在Python命令提示符下使用以下命令完成 -
>>> nltk.download()
安装其他必要的软件包
要使用NLTK构建自然语言处理应用程序,我们需要安装必要的软件包。 包裹如下 -
gensim
它是一个强大的语义建模库,可用于许多应用程序。 我们可以通过执行以下命令来安装它 -
pip install gensim
pattern
它用于使gensim包正常工作。 我们可以通过执行以下命令来安装它
pip install pattern
标记化,词干化和词形还原的概念
在本节中,我们将了解什么是标记化,词干化和词形还原。
标记化(Tokenization)
它可以被定义为将给定文本(即字符序列)分解为称为标记的较小单元的过程。 标记可以是单词,数字或标点符号。 它也被称为分词。 以下是标记化的简单示例 -
Input - 芒果,香蕉,菠萝和苹果都是水果。
Output - 
打破给定文本的过程可以在定位单词边界的帮助下完成。 单词的结尾和新单词的开头称为单词边界。 书写系统和单词的印刷结构影响边界。
在Python NLTK模块中,我们有与标记化相关的不同包,我们可以根据我们的要求将文本划分为标记。 部分套餐如下 -
sent_tokenize包
顾名思义,这个包将输入文本分成句子。 我们可以借助以下Python代码导入此包 -
from nltk.tokenize import sent_tokenize
word_tokenize包
此包将输入文本分为单词。 我们可以借助以下Python代码导入此包 -
from nltk.tokenize import word_tokenize
WordPunctTokenizer包
此包将输入文本分为单词和标点符号。 我们可以借助以下Python代码导入此包 -
from nltk.tokenize import WordPuncttokenizer
Stemming
在处理单词时,由于语法原因,我们遇到了很多变化。 这里的变异概念意味着我们必须处理不同形式的相同词语,如democracy, democratic,和democratization 。 机器非常有必要理解这些不同的单词具有相同的基本形式。 通过这种方式,在分析文本时提取单词的基本形式会很有用。
我们可以通过阻止实现这一目标。 通过这种方式,我们可以说词干是通过切断单词的末尾来提取单词的基本形式的启发式过程。
在Python NLTK模块中,我们有与stemming相关的不同包。 这些包可用于获取单词的基本形式。 这些包使用算法。 部分套餐如下 -
PorterStemmer包
这个Python包使用Porter的算法来提取基本形式。 我们可以借助以下Python代码导入此包 -
from nltk.stem.porter import PorterStemmer
例如,如果我们将'writing'这个词作为这个词干的输入,我们将在词干后得到'write'这个词。
LancasterStemmer包
这个Python包将使用Lancaster的算法来提取基本形式。 我们可以借助以下Python代码导入此包 -
from nltk.stem.lancaster import LancasterStemmer
例如,如果我们将'writing'这个词作为这个词干的输入,我们将在词干后得到'write'这个词。
SnowballStemmer包
这个Python包将使用snowball的算法来提取基本表单。 我们可以借助以下Python代码导入此包 -
from nltk.stem.snowball import SnowballStemmer
例如,如果我们将'writing'这个词作为这个词干的输入,我们将在词干后得到'write'这个词。
所有这些算法都有不同的严格程度。 如果我们比较这三个词干分析器,那么Porter词干分析器是最不严格的,Lancaster是最严格的。 Snowball stemmer在速度和严格性方面都很好用。
词形还原(Lemmatization)
我们还可以通过词形还原来提取单词的基本形式。 它基本上通过词汇和词汇的形态分析来完成这项任务,通常只是为了消除屈折结局。 任何单词的这种基本形式称为引理。
词干和词形还原的主要区别在于词汇的使用和词汇的形态分析。 另一个不同之处在于,词典最常折叠衍生相关词,而词形词化通常只会折叠词形的不同折叠形式。 例如,如果我们提供单词saw作为输入单词,那么词干可能会返回单词's',但是词形还原会尝试返回单词see或saw,具体取决于令牌的使用是动词还是名词。
在Python NLTK模块中,我们有以下与词形还原过程相关的包,我们可以使用它来获得单词的基本形式 -
WordNetLemmatizer包
这个Python包将根据它是用作名词还是用作动词来提取单词的基本形式。 我们可以借助以下Python代码导入此包 -
from nltk.stem import WordNetLemmatizer
分块:将数据分成块
它是自然语言处理的重要过程之一。 分块的主要工作是识别词性和短语,如名词短语。 我们已经研究了令牌化的过程,即令牌的创建。 分块基本上是那些代币的标签。 换句话说,分块将向我们展示句子的结构。
在下一节中,我们将了解不同类型的Chunking。
分块的类型
有两种类型的分块。 类型如下 -
分手
在这个分块过程中,对象,事物等变得更加通用,语言变得更加抽象。 达成协议的可能性更大。 在这个过程中,我们缩小。 例如,如果我们将问题“为什么汽车是什么”? 我们可能得到“运输”的答案。
分手
在这个分块的过程中,对象,事物等变得更具体,语言变得更加渗透。 更深层次的结构将在分块中进行检查。 在这个过程中,我们放大。例如,如果我们把问题“特意讲述一辆汽车”? 我们将获得有关汽车的较小信息。
Example
在这个例子中,我们将使用Python中的NLTK模块进行Noun-Phrase分块,这是一种分块,它将在句子中找到名词短语块 -
Follow these steps in python for implementing noun phrase chunking −
Step 1 - 在此步骤中,我们需要定义分块的语法。 它将包括我们需要遵循的规则。
Step 2 - 在这一步中,我们需要创建一个块解析器。 它会解析语法并给出输出。
Step 3 - 在最后一步中,输出以树格式生成。
让我们按如下方式导入必要的NLTK包 -
import nltk
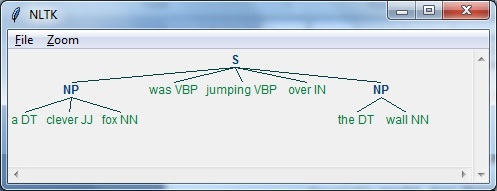
现在,我们需要定义句子。 这里,DT表示行列式,VBP表示动词,JJ表示形容词,IN表示介词,NN表示名词。
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
现在,我们需要给出语法。 在这里,我们将以正则表达式的形式给出语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
我们需要定义一个解析语法的解析器。
parser_chunking = nltk.RegexpParser(grammar)
解析器解析句子如下 -
parser_chunking.parse(sentence)
接下来,我们需要获得输出。 输出在名为output_chunk的简单变量中生成。
Output_chunk = parser_chunking.parse(sentence)
执行以下代码后,我们可以以树的形式绘制输出。
output.draw()
袋子词(BoW)模型
Bag of Word(BoW),一种自然语言处理模型,主要用于从文本中提取特征,以便文本可用于建模,以便在机器学习算法中使用。
现在问题出现了为什么我们需要从文本中提取特征。 这是因为机器学习算法不能用于原始数据,它们需要数字数据,以便它们可以从中提取有意义的信息。 将文本数据转换为数字数据称为特征提取或特征编码。
这个怎么运作
这是从文本中提取特征的非常简单的方法。 假设我们有一个文本文档,我们想将其转换为数字数据,或者想要从中提取特征,那么首先这个模型从文档中的所有单词中提取词汇表。 然后通过使用文档术语矩阵,它将构建一个模型。 通过这种方式,BoW仅将文档表示为一个单词包。 关于文档中单词的顺序或结构的任何信息都将被丢弃。
文件术语矩阵的概念
BoW算法通过使用文档术语矩阵来构建模型。 顾名思义,文档术语矩阵是文档中出现的各种字数的矩阵。 在该矩阵的帮助下,文本文档可以表示为各种单词的加权组合。 通过设置阈值并选择更有意义的单词,我们可以构建文档中可用作特征向量的所有单词的直方图。 以下是理解文档术语矩阵概念的示例 -
Example
假设我们有以下两句话 -
Sentence 1 - 我们正在使用Bag of Words模型。
Sentence 2 - Bag of Words模型用于提取特征。
现在,通过考虑这两个句子,我们有以下13个不同的词 -
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
现在,我们需要通过在每个句子中使用单词count来为每个句子构建直方图 -
Sentence 1 - [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1]
通过这种方式,我们得到了已经提取的特征向量。 每个特征向量都是13维的,因为我们有13个不同的单词。
统计的概念
统计的概念称为TermFrequency-Inverse Document Frequency(tf-idf)。 每个单词在文档中都很重要。 统计数据有助于我们理解每个单词的重要性。
Term Frequency(tf)
它衡量每个单词出现在文档中的频率。 它可以通过将每个单词的计数除以给定文档中的单词总数来获得。
Inverse Document Frequency(idf)
它衡量一个单词在给定文档集中对该文档的唯一性。 为了计算idf并制定一个与众不同的特征向量,我们需要减少常见单词的权重,并对稀有单词进行权衡。
在NLTK中建立一个单词模型
在本节中,我们将使用CountVectorizer从这些句子创建向量来定义字符串集合。
让我们导入必要的包裹 -
from sklearn.feature_extraction.text import CountVectorizer
现在定义一组句子。
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
<b class="notranslate">print(vectorizer.vocabulary_)</b>
上述程序生成输出,如下所示。 它表明我们在上述两个句子中有13个不同的词 -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}
这些是可用于机器学习的特征向量(文本到数字形式)。
解决问题
在本节中,我们将解决一些相关问题。
类别预测
在一组文件中,不仅单词而且单词的类别也很重要; 特定单词属于哪种类型的文本。 例如,我们想要预测给定句子是否属于电子邮件,新闻,体育,计算机等类别。在下面的示例中,我们将使用tf-idf来制定特征向量以查找文档类别。 我们将使用来自sklearn的20个新闻组数据集的数据。
我们需要导入必要的包 -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
定义类别映射。 我们使用五个不同的类别,分别是宗教,汽车,体育,电子和太空。
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}
创建训练集 -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)
构建计数向量化器并提取术语计数 -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)
tf-idf变换器创建如下 -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)
现在,定义测试数据 -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]
以上数据将帮助我们训练多项式朴素贝叶斯分类器 -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)
使用计数矢量化器转换输入数据 -
input_tc = vectorizer_count.transform(input_data)
现在,我们将使用tfidf变换器转换矢量化数据 -
input_tfidf = tfidf.transform(input_tc)
我们将预测输出类别 -
predictions = classifier.predict(input_tfidf)
输出生成如下 -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])
类别预测器生成以下输出 -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: Electronics
性别发现者
在这个问题陈述中,将通过提供名称来训练分类器以找到性别(男性或女性)。 我们需要使用启发式来构造特征向量并训练分类器。 我们将使用scikit-learn包中的标记数据。 以下是构建性别查找器的Python代码 -
让我们导入必要的包 -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import names
现在我们需要从输入词中提取最后N个字母。 这些信件将作为功能 -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':
使用NLTK中提供的带标签名称(男性和女性)创建训练数据 -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)
现在,测试数据将创建如下 -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']
使用以下代码定义用于训练和测试的样本数
train_sample = int(0.8 * len(data))
现在,我们需要迭代不同的长度,以便比较准确性 -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)
分类器的准确度可以如下计算 -
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')
现在,我们可以预测输出 -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))
以上程序将生成以下输出 -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
在上面的输出中,我们可以看到最大结束字母数的准确度是2,并且随着结束字母数的增加而减少。
主题建模:识别文本数据中的模式
我们知道通常将文档分组到主题中。 有时我们需要识别与特定主题相对应的文本中的模式。 这样做的技术称为主题建模。 换句话说,我们可以说主题建模是一种在给定文档集中发现抽象主题或隐藏结构的技术。
我们可以在以下场景中使用主题建模技术 -
文本分类
在主题建模的帮助下,可以改进分类,因为它将相似的单词组合在一起,而不是将每个单词分别用作特征。
推荐系统
在主题建模的帮助下,我们可以使用相似性度量来构建推荐系统。
主题建模的算法
可以使用算法来实现主题建模。 算法如下 -
Latent Dirichlet Allocation(LDA)
该算法是主题建模最常用的算法。 它使用概率图形模型来实现主题建模。 我们需要在Python中导入gensim包以使用LDA算法。
潜在语义分析(LDA)或潜在语义索引(LSI)
该算法基于线性代数。 基本上它在文档术语矩阵上使用SVD(奇异值分解)的概念。
Non-Negative Matrix Factorization (NMF)
它也基于线性代数。
用于主题建模的所有上述算法将具有作为参数number of topics的number of topics作为输入的Document-Word Matrix和作为输出的WTM (Word Topic Matrix)和TDM (Topic Document Matrix) 。
AI with Python – Analyzing Time Series Data
预测给定输入序列中的下一个是机器学习中的另一个重要概念。 本章为您提供有关分析时间序列数据的详细说明。
介绍 (Introduction)
时间序列数据表示一系列特定时间间隔内的数据。 如果我们想在机器学习中构建序列预测,那么我们必须处理顺序数据和时间。 系列数据是顺序数据的摘要。 数据排序是顺序数据的重要特征。
序列分析或时间序列分析的基本概念
序列分析或时间序列分析是基于先前观察到的预测给定输入序列中的下一个。 预测可以是接下来可能出现的任何事情:符号,数字,次日天气,下一个语音等。序列分析在诸如股票市场分析,天气预报和产品推荐等应用中非常方便。
Example
请考虑以下示例以了解序列预测。 这里A,B,C,D是给定值,您必须使用序列预测模型预测值E

安装有用的包
对于使用Python的时间序列数据分析,我们需要安装以下包 -
Pandas
Pandas是一个开源的BSD许可库,为Python提供高性能,易于使用的数据结构和数据分析工具。 您可以借助以下命令安装Pandas -
pip install pandas
如果您正在使用Anaconda并希望使用conda软件包管理器进行安装,那么您可以使用以下命令 -
conda install -c anaconda pandas
hmmlearn
它是一个开源的BSD许可库,由简单的算法和模型组成,用于学习Python中的隐马尔可夫模型(HMM)。 您可以借助以下命令安装它 -
pip install hmmlearn
如果您正在使用Anaconda并希望使用conda软件包管理器进行安装,那么您可以使用以下命令 -
conda install -c omnia hmmlearn
PyStruct
它是一个结构化的学习和预测库。 在PyStruct中实现的学习算法具有诸如条件随机场(CRF),最大边缘马尔可夫随机网络(M3N)或结构支持向量机之类的名称。 您可以借助以下命令安装它 -
pip install pystruct
CVXOPT
它用于基于Python编程语言的凸优化。 它也是一个免费的软件包。 您可以在以下命令的帮助下安装它 -
pip install cvxopt
如果您正在使用Anaconda并希望使用conda软件包管理器进行安装,那么您可以使用以下命令 -
conda install -c anaconda cvdoxt
熊猫:从时间序列数据处理,切片和提取统计数据
如果您必须处理时间序列数据,Pandas是一个非常有用的工具。 在Pandas的帮助下,您可以执行以下操作 -
使用pd.date_range包创建一系列日期
使用pd.Series包索引带有日期的pd.Series
使用ts.resample包执行重新采样
改变频率
例子 (Example)
以下示例显示使用Pandas处理和切片时间序列数据。 请注意,这里我们使用的是每月北极涛动数据,可以从monthly.ao.index.b50.current.ascii下载,并可以转换为文本格式供我们使用。
处理时间序列数据
要处理时间序列数据,您必须执行以下步骤 -
第一步涉及导入以下包 -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
接下来,定义一个函数,它将从输入文件中读取数据,如下面给出的代码所示 -
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)
现在,将此数据转换为时间序列。 为此,请创建时间序列的日期范围。 在这个例子中,我们保留一个月的数据频率。 我们的文件的数据从1950年1月开始。
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')
在此步骤中,我们在Pandas系列的帮助下创建时间序列数据,如下所示 -
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':
输入输入文件的路径,如下所示 -
input_file = "/Users/admin/AO.txt"
现在,将列转换为timeseries格式,如下所示 -
timeseries = read_data(input_file)
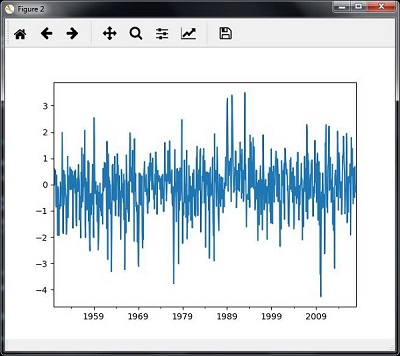
最后,使用显示的命令绘制并可视化数据 -
plt.figure()
timeseries.plot()
plt.show()
您将观察到如下图所示的图 -

切片时间序列数据
切片涉及仅检索时间序列数据的某些部分。 作为示例的一部分,我们仅从1980年到1990年对数据进行切片。观察以下执行此任务的代码 -
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()
当您运行用于切片时间序列数据的代码时,您可以观察到如下图所示 - 如下图所示 -
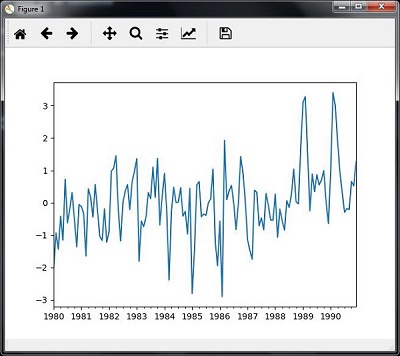
从时间序列数据中提取统计量
在需要得出一些重要结论的情况下,您必须从给定数据中提取一些统计数据。 平均值,方差,相关性,最大值和最小值是一些此类统计数据。 如果要从给定的时间序列数据中提取此类统计信息,可以使用以下代码 -
Mean
您可以使用mean()函数来查找均值,如下所示 -
timeseries.mean()
然后,您将针对所讨论的示例观察到的输出是 -
-0.11143128165238671
Maximum
您可以使用max()函数来查找最大值,如下所示 -
timeseries.max()
然后,您将针对所讨论的示例观察到的输出是 -
3.4952999999999999
Minimum
您可以使用min()函数来查找最小值,如下所示 -
timeseries.min()
然后,您将针对所讨论的示例观察到的输出是 -
-4.2656999999999998
一劳永逸
如果要一次计算所有统计信息,可以使用describe()函数,如下所示 -
timeseries.describe()
然后,您将针对所讨论的示例观察到的输出是 -
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64
重新取样
您可以将数据重新采样到不同的时间频率。 进行重新采样的两个参数是 -
- Time period
- Method
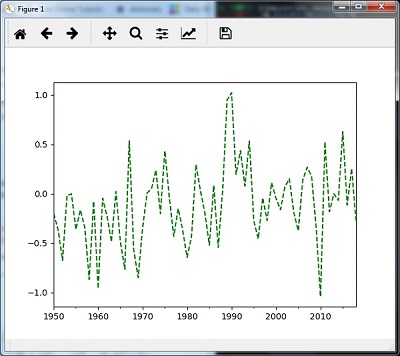
Re-sampling with mean()
您可以使用以下代码使用mean()方法重新采样数据,这是默认方法 -
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()
然后,您可以使用mean()观察以下图表作为重采样的输出 -
Re-sampling with median()
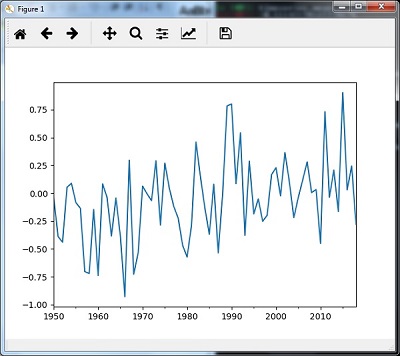
您可以使用以下代码使用median()方法重新采样数据 -
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()
然后,您可以观察下图作为中位数()重新采样的输出 -
滚动平均值
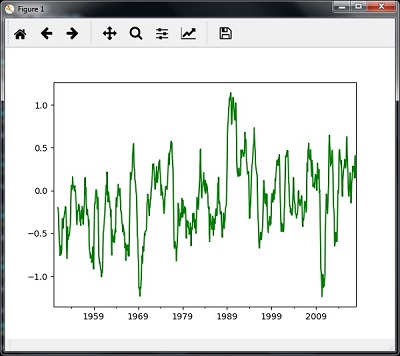
您可以使用以下代码计算滚动(移动)平均值 -
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()
然后,您可以观察下图作为滚动(移动)平均值的输出 -
用隐马尔可夫模型(HMM)分析序列数据
HMM是一种统计模型,广泛用于具有延续性和可扩展性的数据,如时间序列股票市场分析,健康检查和语音识别。 本节详细介绍了使用隐马尔可夫模型(HMM)分析顺序数据。
Hidden Markov Model (HMM)
HMM是一个随机模型,它基于马尔可夫链的概念,基于以下假设:未来统计数据的概率仅取决于当前的过程状态而不是之前的任何状态。 例如,当投掷硬币时,我们不能说第五次投掷的结果将是一个头。 这是因为硬币没有任何记忆,下一个结果不依赖于之前的结果。
在数学上,HMM由以下变量组成 -
States (S)
它是HMM中存在的一组隐藏或潜在状态。 它由S.表示
Output symbols (O)
它是HMM中存在的一组可能的输出符号。 它用O表示。
状态转移概率矩阵(A)
它是从一个状态转换到每个其他状态的概率。 它用A表示。
观测发射概率矩阵(B)
它是在特定状态下发射/观察符号的概率。 它由B表示。
Prior Probability Matrix (Π)
它是从系统的各种状态开始于特定状态的概率。 它用Π表示。
因此,HMM可以定义为???? = (S,O,A,B,????) ???? = (S,O,A,B,????) ,
Where,
- S = {s 1 ,s 2 ,…,s N }是N个可能状态的集合,
- O = {o 1 ,o 2 ,…,o M }是一组M个可能的观察符号,
- A是N????N状态转移概率矩阵(TPM),
- B是N????M观测或发射概率矩阵(EPM),
- π是N维初始状态概率分布矢量。
示例:股市数据分析
在这个例子中,我们将逐步分析股票市场的数据,以了解HMM如何与顺序或时间序列数据一起工作。 请注意,我们正在Python中实现此示例。
导入必要的包,如下所示 -
import datetime
import warnings
现在,使用matpotlib.finance包中的股票市场数据,如下所示 -
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMM
从开始日期和结束日期加载数据,即在此处显示的两个特定日期之间加载数据 -
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)
在此步骤中,我们将每天提取结束引号。 为此,请使用以下命令 -
closing_quotes = np.array([quote[2] for quote in quotes])
现在,我们将提取每天交易的股票数量。 为此,请使用以下命令 -
volumes = np.array([quote[5] for quote in quotes])[1:]
在这里,使用下面显示的代码获取收盘价格的百分比差异 -
diff_percentages = 100.0 * np.diff(closing_quotes)/closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])
在此步骤中,创建并训练高斯HMM。 为此,请使用以下代码 -
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)
现在,使用HMM模型生成数据,使用显示的命令 -
num_samples = 300
samples, _ = hmm.sample(num_samples)
最后,在此步骤中,我们绘制并可视化以图表形式作为输出交易的股票的差异百分比和数量。
使用以下代码绘制和可视化差异百分比 -
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')
使用以下代码绘制和可视化交易的股票数量 -
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()
AI with Python – Speech Recognition
在本章中,我们将学习使用Python和Python进行语音识别。
言语是成人人际交往的最基本手段。 语音处理的基本目标是提供人与机器之间的交互。
语音处理系统主要有三个任务 -
First ,语音识别允许机器捕捉我们说的单词,短语和句子
Second ,自然语言处理,让机器了解我们所说的话,和
Third ,语音合成让机器说话。
本章重点介绍speech recognition ,即理解人类所说话语的过程。 请记住,语音信号是在麦克风的帮助下捕获的,然后必须由系统理解。
构建语音识别器
语音识别或自动语音识别(ASR)是机器人等AI项目的关注焦点。 没有ASR,就无法想象认知机器人与人交互。 但是,构建语音识别器并不容易。
开发语音识别系统的困难
开发高质量的语音识别系统确实是一个难题。 语音识别技术的难度可以沿着如下所述的多个维度进行广泛表征 -
Size of the vocabulary大小 - Size of the vocabulary大小会影响ASR的开发。 考虑以下大小的词汇表以便更好地理解。
例如,在语音菜单系统中,小型词汇表由2-100个单词组成
例如,在数据库检索任务中,中等大小的词汇表由几个100到1,000个单词组成
大型词汇表由几万个单词组成,如一般的听写任务。
Channel characteristics - 渠道质量也是一个重要方面。 例如,人类语音包含具有全频率范围的高带宽,而电话语音包括具有有限频率范围的低带宽。 请注意,后者更难。
Speaking mode - 易于开发ASR还取决于说话模式,即语音是处于隔离字模式,还是连接字模式,还是处于连续语音模式。 请注意,连续语音难以识别。
Speaking style - 朗读演讲可以采用正式风格,也可以是随意风格的自发和对话。 后者更难以识别。
Speaker dependency - 语音可以是说话者相关的,说话者自适应的或说话者独立的 独立的扬声器是最难建立的。
Type of noise - 噪声是开发ASR时需要考虑的另一个因素。 信噪比可能在不同的范围内,具体取决于观察较少的声学环境与更多的背景噪声 -
如果信噪比大于30dB,则认为是高范围
如果信噪比介于30dB到10db之间,则认为是中等SNR
如果信噪比小于10dB,则认为是低范围
Microphone characteristics - Microphone characteristics的质量可能很好,平均或低于平均水平。 此外,嘴和微型电话之间的距离可能会有所不同。 识别系统也应考虑这些因素。
请注意,词汇量越大,执行识别就越困难。
例如,诸如静止,非人类噪声,背景语音和其他扬声器的串扰之类的背景噪声也会导致问题的困难。
尽管存在这些困难,研究人员仍然在语音的各个方面进行了大量工作,例如理解语音信号,说话者和识别口音。
您必须按照下面给出的步骤构建语音识别器 -
可视化音频信号 - 从文件读取并处理它
这是构建语音识别系统的第一步,因为它可以理解音频信号的结构。 使用音频信号可以遵循的一些常见步骤如下 -
录制(Recording)
当您必须从文件中读取音频信号时,首先使用麦克风录制它。
Sampling
使用麦克风录制时,信号以数字化形式存储。 但是要对它进行处理,机器需要它们以离散的数字形式。 因此,我们应该以特定频率进行采样并将信号转换为离散数字形式。 选择高频采样意味着当人们听到信号时,他们会将其视为连续的音频信号。
例子 (Example)
以下示例显示了使用Python分析音频信号的逐步方法,该方法存储在文件中。 该音频信号的频率为44,100HZ。
导入必要的包,如下所示 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
现在,读取存储的音频文件。 它将返回两个值:采样频率和音频信号。 提供存储它的音频文件的路径,如下所示 -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
使用显示的命令显示音频信号的采样频率,信号的数据类型及其持续时间等参数 -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0]/
float(frequency_sampling), 2), 'seconds')
此步骤涉及对信号进行标准化,如下所示 -
audio_signal = audio_signal/np.power(2, 15)
在此步骤中,我们从此信号中提取前100个值以进行可视化。 为此目的使用以下命令 -
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1)/float(frequency_sampling)
现在,使用下面给出的命令可视化信号 -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()
您将能够看到输出图形和为上述音频信号提取的数据,如此处的图像所示
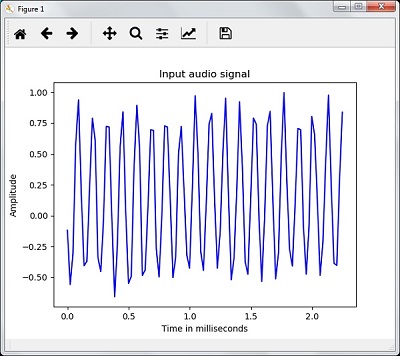
Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 seconds
表征音频信号:转换为频域
表征音频信号涉及将时域信号转换为频域,并通过以下方式理解其频率分量。 这是一个重要的步骤,因为它提供了有关信号的大量信息。 您可以使用傅里叶变换等数学工具来执行此转换。
例子 (Example)
以下示例逐步显示如何使用存储在文件中的Python来表征信号。 请注意,这里我们使用傅里叶变换数学工具将其转换为频域。
导入必要的包,如下所示 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
现在,读取存储的音频文件。 它将返回两个值:采样频率和音频信号。 提供存储它的音频文件的路径,如此处的命令所示 -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")
在此步骤中,我们将使用下面给出的命令显示音频信号的采样频率,信号的数据类型及其持续时间等参数 -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0]/
float(frequency_sampling), 2), 'seconds')
在此步骤中,我们需要对信号进行标准化,如以下命令所示 -
audio_signal = audio_signal/np.power(2, 15)
该步骤涉及提取信号的长度和长度。 为此目的使用以下命令 -
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1)/2.0).astype(np.int)
现在,我们需要应用数学工具来转换为频域。 这里我们使用傅立叶变换。
signal_frequency = np.fft.fft(audio_signal)
现在,做频域信号的归一化并将其平方 -
signal_frequency = abs(signal_frequency[0:half_length])/length_signal
signal_frequency **= 2
接下来,提取频率变换信号的长度和长度 -
len_fts = len(signal_frequency)
注意,必须调整傅里叶变换信号以及奇数情况。
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2
现在,以分贝(dB)提取功率 -
signal_power = 10 * np.log10(signal_frequency)
为X轴调整以kHz为单位的频率 -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling/length_signal)/1000.0
现在,可视化信号的特征描述如下 -
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()
您可以观察上面代码的输出图,如下图所示 -
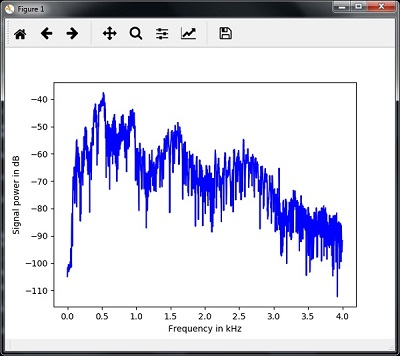
生成单调音频信号
到目前为止,您已经看到的两个步骤对于了解信号非常重要。 现在,如果要生成带有一些预定义参数的音频信号,此步骤将非常有用。 请注意,此步骤会将音频信号保存在输出文件中。
例子 (Example)
在下面的示例中,我们将使用Python生成单调信号,该信号将存储在文件中。 为此,您必须采取以下步骤 -
如图所示导入必要的包 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write
提供应保存输出文件的文件
output_file = 'audio_signal_generated.wav'
现在,指定您选择的参数,如图所示 -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.pi
在这一步中,我们可以生成音频信号,如图所示 -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)
现在,将音频文件保存在输出文件中 -
write(output_file, frequency_sampling, signal_scaled)
提取图表的前100个值,如图所示 -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1)/float(sampling_freq)
现在,将生成的音频信号可视化如下 -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()
您可以观察到如下图所示的情节 -
语音特征提取
这是构建语音识别器的最重要步骤,因为在将语音信号转换为频域后,我们必须将其转换为可用的特征向量形式。 为此,我们可以使用不同的特征提取技术,如MFCC,PLP,PLP-RASTA等。
例子 (Example)
在下面的示例中,我们将使用Python,使用MFCC技术逐步从信号中提取信号。
导入必要的包,如下所示 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank
现在,读取存储的音频文件。 它将返回两个值 - 采样频率和音频信号。 提供存储它的音频文件的路径。
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
请注意,我们在这里采用前15000个样本进行分析。
audio_signal = audio_signal[:15000]
使用MFCC技术并执行以下命令以提取MFCC功能 -
features_mfcc = mfcc(audio_signal, frequency_sampling)
现在,打印MFCC参数,如图所示 -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])
现在,使用下面给出的命令绘制和可视化MFCC功能 -
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')
在此步骤中,我们使用如图所示的过滤器库功能 -
提取过滤器库功能 -
filterbank_features = logfbank(audio_signal, frequency_sampling)
现在,打印filterbank参数。
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])
现在,绘制并可视化滤波器组功能。
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
根据上述步骤,您可以观察到以下输出:图1表示MFCC,图2表示滤波器组

对口语的认识
语音识别意味着当人类说话时,机器会理解它。 在这里,我们使用Python中的Google Speech API来实现它。 我们需要为此安装以下软件包 -
Pyaudio - 可以使用pip install Pyaudio命令pip install Pyaudio 。
SpeechRecognition - 可以使用pip install SpeechRecognition.安装此软件包pip install SpeechRecognition.
Google-Speech-API - 可以使用命令pip install google-api-python-client 。
例子 (Example)
请注意以下示例以了解口头语言的识别 -
如图所示导入必要的包 -
import speech_recognition as sr
创建一个对象,如下所示 -
recording = sr.Recognizer()
现在, Microphone()模块将把声音作为输入 -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)
现在,谷歌API将识别语音并提供输出。
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)
你可以看到以下输出 -
Please Say Something:
You said:
例如,如果你说iowiki.com ,那么系统会正确识别它,如下所示 -
iowiki.com
AI with Python – Heuristic Search
启发式搜索在人工智能中起着关键作用。 在本章中,您将详细了解它。
AI中的启发式搜索的概念
启发式是一个经验法则,它引导我们找到可能的解决方案。 人工智能中的大多数问题具有指数性质并且具有许多可能的解决方案。 您不确切知道哪些解决方案是正确的,并且检查所有解决方案将非常昂贵。
因此,启发式的使用缩小了对解决方案的搜索范围,并消除了错误的选项。 使用启发式引导搜索空间中的搜索的方法称为启发式搜索。 启发式技术非常有用,因为在使用它们时可以提高搜索速度。
不知情和知情搜索之间的区别
有两种类型的控制策略或搜索技术:不知情和知情。 这里给出了详细解释 -
不知情的搜索
它也被称为盲目搜索或盲目控制策略。 之所以这样命名是因为只有关于问题定义的信息,并且没有关于状态的其他额外信息。 这种搜索技术将搜索整个状态空间以获得解决方案。 广度优先搜索(BFS)和深度优先搜索(DFS)是不知情搜索的示例。
知情搜索
它也被称为启发式搜索或启发式控制策略。 之所以这样命名是因为有一些关于状态的额外信息。 此额外信息对于计算要探索和扩展的子节点之间的首选项很有用。 将存在与每个节点相关联的启发式函数。 最佳首次搜索(BFS),A *,平均值和分析是知情搜索的示例。
Constraint Satisfaction Problems (CSPs)
约束意味着限制或限制。 在人工智能中,约束满足问题是在某些约束条件下必须解决的问题。 重点必须是在解决此类问题时不要违反约束。 最后,当我们达到最终解决方案时,CSP必须遵守限制。
约束满足解决现实问题
前面的部分涉及创建约束满足问题。 现在,让我们将其应用于现实世界的问题。 通过约束满足解决的现实世界问题的一些例子如下 -
解决代数关系
在约束满足问题的帮助下,我们可以解决代数关系。 在这个例子中,我们将尝试解决一个简单的代数关系a*2 = b 。 它将在我们定义的范围内返回a和b的值。
完成这个Python程序后,您将能够理解解决约束满足问题的基础知识。
注意,在编写程序之前,我们需要安装名为python-constraint的Python包。 您可以借助以下命令安装它 -
pip install python-constraint
以下步骤显示了使用约束满足来解决代数关系的Python程序 -
使用以下命令导入constraint包 -
from constraint import *
现在,创建一个名为problem()的模块对象,如下所示 -
problem = Problem()
现在,定义变量。 注意,这里我们有两个变量a和b,我们将10定义为它们的范围,这意味着我们在前10个数字中得到了解。
problem.addVariable('a', range(10))
problem.addVariable('b', range(10))
接下来,定义我们要在此问题上应用的特定约束。 注意,我们在这里使用约束a*2 = b 。
problem.addConstraint(lambda a, b: a * 2 == b)
现在,使用以下命令创建getSolution()模块的对象 -
solutions = problem.getSolutions()
最后,使用以下命令打印输出 -
print (solutions)
您可以按如下方式观察上述程序的输出 -
[{'a': 4, 'b': 8}, {'a': 3, 'b': 6}, {'a': 2, 'b': 4}, {'a': 1, 'b': 2}, {'a': 0, 'b': 0}]
魔术广场
幻方是一个方形网格中不同数字(通常是整数)的排列,其中每行和每列中的数字以及对角线中的数字都加起来称为“魔术常数”的相同数字。
以下是用于生成幻方的简单Python代码的逐步执行 -
定义一个名为magic_square的函数,如下所示 -
def magic_square(matrix_ms):
iSize = len(matrix_ms[0])
sum_list = []
以下代码显示了正方形的垂直代码 -
for col in range(iSize):
sum_list.append(sum(row[col] for row in matrix_ms))
以下代码显示了正方形的水平代码 -
sum_list.extend([sum (lines) for lines in matrix_ms])
以下代码显示了正方形水平的代码 -
dlResult = 0
for i in range(0,iSize):
dlResult +=matrix_ms[i][i]
sum_list.append(dlResult)
drResult = 0
for i in range(iSize-1,-1,-1):
drResult +=matrix_ms[i][i]
sum_list.append(drResult)
if len(set(sum_list))>1:
return False
return True
现在,给出矩阵的值并检查输出 -
print(magic_square([[1,2,3], [4,5,6], [7,8,9]]))
您可以观察到输出将为False因为总和不是相同的数字。
print(magic_square([[3,9,2], [3,5,7], [9,1,6]]))
您可以观察到输出将为True因为总和是相同的数字,即此处为15 。
AI with Python – Gaming
游戏采用策略。 每个玩家或团队在开始游戏之前都会制定策略,他们必须根据游戏中的当前情况更改或构建新策略。
搜索算法
您必须使用与上述相同的策略来考虑电脑游戏。 请注意,搜索算法是计算出电脑游戏策略的算法。
这个怎么运作
搜索算法的目标是找到最佳移动集,以便它们可以到达最终目的地并获胜。 这些算法使用每个游戏不同的获胜条件来找到最佳动作。
将计算机游戏可视化为树。 我们知道树有节点。 从根开始,我们可以进入最终的获胜节点,但是有最佳的移动。 这是搜索算法的工作。 此树中的每个节点都代表未来状态。 搜索算法搜索该树以在游戏的每个步骤或节点处做出决定。
组合搜索
使用搜索算法的主要缺点是它们本质上是详尽的,这就是为什么它们探索整个搜索空间以找到导致资源浪费的解决方案的原因。 如果这些算法需要搜索整个搜索空间以找到最终解决方案,那将会更麻烦。
为了消除这种问题,我们可以使用组合搜索,它使用启发式搜索搜索空间并通过消除可能的错误移动来减小其大小。 因此,这种算法可以节省资源。 这里讨论一些使用启发式搜索空间并节省资源的算法 -
Minimax算法
它是组合搜索使用的策略,它使用启发式来加速搜索策略。 Minimax策略的概念可以用两个玩家游戏的例子来理解,其中每个玩家试图预测对手的下一步动作并试图最小化该功能。 此外,为了获胜,玩家总是试图根据当前情况最大化自己的功能。
启发式在像Minimax这样的策略中起着重要作用。 树的每个节点都有一个与之关联的启发式函数。 基于该启发式,它将决定向最有利于他们的节点迈进。
Alpha-Beta Pruning
Minimax算法的一个主要问题是它可以探索不相关的树的那些部分,从而导致资源的浪费。 因此,必须有一个策略来决定树的哪个部分是相关的,哪个部分是无关紧要的,并且将不相关的部分留待探索。 Alpha-Beta修剪就是这样一种策略。
Alpha-Beta修剪算法的主要目标是避免搜索没有任何解决方案的树的那些部分。 Alpha-Beta修剪的主要概念是使用名为Alpha (最大下限)和Beta (最小上限)的两个边界。 这两个参数是限制可能解决方案集的值。 它将当前节点的值与alpha和beta参数的值进行比较,以便它可以移动到具有解决方案的树的一部分并丢弃其余部分。
Negamax算法
该算法与Minimax算法没有什么不同,但它具有更优雅的实现。 使用Minimax算法的主要缺点是我们需要定义两个不同的启发式函数。 这些启发式之间的联系是,对于一个玩家来说,游戏状态越好,对另一个玩家来说就越糟糕。 在Negamax算法中,两个启发式函数的相同工作是在单个启发式函数的帮助下完成的。
建立机器人玩游戏
为了构建机器人在AI中玩两个玩家游戏,我们需要安装easyAI库。 它是一个人工智能框架,提供构建双人游戏的所有功能。 您可以借助以下命令下载它 -
pip install easyAI
最后硬币站立的机器人
在这个游戏中,会有一堆硬币。 每个玩家必须从那堆中取出一些硬币。 游戏的目标是避免将最后一枚硬币放入堆中。 我们将使用继承自easyAI库的TwoPlayersGame类的TwoPlayersGame类。 以下代码显示了此游戏的Python代码 -
如图所示导入所需的包 -
from easyAI import TwoPlayersGame, id_solve, Human_Player, AI_Player
from easyAI.AI import TT
现在,继承TwoPlayerGame类中的类来处理游戏的所有操作 -
class LastCoin_game(TwoPlayersGame):
def __init__(self, players):
现在,定义将要开始游戏的玩家和玩家。
self.players = players
self.nplayer = 1
现在,定义游戏中的硬币数量,这里我们使用15个硬币进行游戏。
self.num_coins = 15
定义玩家在移动中可以获得的最大硬币数。
self.max_coins = 4
现在有一些特定的东西需要定义,如下面的代码所示。 定义可能的动作。
def possible_moves(self):
return [str(a) for a in range(1, self.max_coins + 1)]
定义硬币的移除
def make_move(self, move):
self.num_coins -= int(move)
定义谁拿了最后一枚硬币。
def win_game(self):
return self.num_coins <= 0
定义何时停止游戏,即有人获胜。
def is_over(self):
return self.win()
定义如何计算分数。
def score(self):
return 100 if self.win_game() else 0
定义堆中剩余的硬币数量。
def show(self):
print(self.num_coins, 'coins left in the pile')
if __name__ == "__main__":
tt = TT()
LastCoin_game.ttentry = lambda self: self.num_coins
使用以下代码块解决游戏问题 -
r, d, m = id_solve(LastCoin_game,
range(2, 20), win_score=100, tt=tt)
print(r, d, m)
决定谁将开始游戏
game = LastCoin_game([AI_Player(tt), Human_Player()])
game.play()
你可以找到以下输出和这个游戏的简单游戏 -
d:2, a:0, m:1
d:3, a:0, m:1
d:4, a:0, m:1
d:5, a:0, m:1
d:6, a:100, m:4
1 6 4
15 coins left in the pile
Move #1: player 1 plays 4 :
11 coins left in the pile
Player 2 what do you play ? 2
Move #2: player 2 plays 2 :
9 coins left in the pile
Move #3: player 1 plays 3 :
6 coins left in the pile
Player 2 what do you play ? 1
Move #4: player 2 plays 1 :
5 coins left in the pile
Move #5: player 1 plays 4 :
1 coins left in the pile
Player 2 what do you play ? 1
Move #6: player 2 plays 1 :
0 coins left in the pile
一个玩Tic Tac Toe的机器人
Tic-Tac-Toe是非常熟悉的,也是最受欢迎的游戏之一。 让我们使用Python中的easyAI库来创建这个游戏。 以下代码是此游戏的Python代码 -
如图所示导入包 -
from easyAI import TwoPlayersGame, AI_Player, Negamax
from easyAI.Player import Human_Player
继承TwoPlayerGame类中的类来处理游戏的所有操作 -
class TicTacToe_game(TwoPlayersGame):
def __init__(self, players):
现在,定义将要开始游戏的玩家和玩家 -
self.players = players
self.nplayer = 1
定义板的类型 -
self.board = [0] * 9
现在有一些事情需要定义如下 -
定义可能的动作
def possible_moves(self):
return [x + 1 for x, y in enumerate(self.board) if y == 0]
定义玩家的移动 -
def make_move(self, move):
self.board[int(move) - 1] = self.nplayer
为了提升AI,定义玩家何时移动 -
def umake_move(self, move):
self.board[int(move) - 1] = 0
定义对手在一条线上有三个的失败条件
def condition_for_lose(self):
possible_combinations = [[1,2,3], [4,5,6], [7,8,9],
[1,4,7], [2,5,8], [3,6,9], [1,5,9], [3,5,7]]
return any([all([(self.board[z-1] == self.nopponent)
for z in combination]) for combination in possible_combinations])
定义一个游戏结束的检查
def is_over(self):
return (self.possible_moves() == []) or self.condition_for_lose()
显示游戏中玩家的当前位置
def show(self):
print('\n'+'\n'.join([' '.join([['.', 'O', 'X'][self.board[3*j + i]]
for i in range(3)]) for j in range(3)]))
计算分数。
def scoring(self):
return -100 if self.condition_for_lose() else 0
定义定义算法并开始游戏的主要方法 -
if __name__ == "__main__":
algo = Negamax(7)
TicTacToe_game([Human_Player(), AI_Player(algo)]).play()
你可以看到以下输出和这个游戏的简单游戏 -
. . .
. . .
. . .
Player 1 what do you play ? 1
Move #1: player 1 plays 1 :
O . .
. . .
. . .
Move #2: player 2 plays 5 :
O . .
. X .
121
. . .
Player 1 what do you play ? 3
Move #3: player 1 plays 3 :
O . O
. X .
. . .
Move #4: player 2 plays 2 :
O X O
. X .
. . .
Player 1 what do you play ? 4
Move #5: player 1 plays 4 :
O X O
O X .
. . .
Move #6: player 2 plays 8 :
O X O
O X .
. X .
AI with Python – Neural Networks
神经网络是并行计算设备,其试图建立大脑的计算机模型。 其背后的主要目标是开发一个系统,以比传统系统更快地执行各种计算任务。 这些任务包括模式识别和分类,近似,优化和数据聚类。
什么是人工神经网络(ANN)
人工神经网络(ANN)是一种高效的计算系统,其中心主题借鉴了生物神经网络的类比。 人工神经网络也被称为人工神经系统,并行分布式处理系统和连接系统。 ANN收集了大量的单元,这些单元以某种模式互连,以便在它们之间进行通信。 这些单元,也称为nodes或neurons ,是并行操作的简单处理器。
每个神经元通过connection link与其他神经元connection link 。 每个连接链路与具有关于输入信号的信息的权重相关联。 这是神经元解决特定问题的最有用信息,因为weight通常会激发或抑制正在传递的信号。 每个神经元都具有其内部状态,称为activation signal 。 在组合输入信号和激活规则之后产生的输出信号可以被发送到其他单元。
如果您想详细研究神经网络,那么您可以按照链接 - 人工神经网络 。
安装有用的包
为了在Python中创建神经网络,我们可以使用一个名为NeuroLab神经网络的强大包。 它是一个基本的神经网络算法库,具有灵活的网络配置和Python学习算法。 您可以在命令提示符下使用以下命令安装此软件包 -
pip install NeuroLab
如果您使用的是Anaconda环境,请使用以下命令安装NeuroLab -
conda install -c labfabulous neurolab
构建神经网络
在本节中,让我们使用NeuroLab包在Python中构建一些神经网络。
基于感知器的分类器
感知器是人工神经网络的基石。 如果您想了解更多关于Perceptron的信息,可以点击链接 - artificial_neural_network
以下是逐步执行Python代码,用于构建基于简单神经网络感知器的分类器 -
如图所示导入必要的包 -
import matplotlib.pyplot as plt
import neurolab as nl
输入输入值。 请注意,这是监督学习的一个例子,因此您也必须提供目标值。
input = [[0, 0], [0, 1], [1, 0], [1, 1]]
target = [[0], [0], [0], [1]]
使用2个输入和1个神经元创建网络 -
net = nl.net.newp([[0, 1],[0, 1]], 1)
现在,训练网络。 在这里,我们使用Delta规则进行培训。
error_progress = net.train(input, target, epochs=100, show=10, lr=0.1)
现在,可视化输出并绘制图形 -
plt.figure()
plt.plot(error_progress)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.grid()
plt.show()
您可以使用错误指标查看以下显示培训进度的图表 -
单层神经网络
在这个例子中,我们创建了一个单层神经网络,它由作用于输入数据的独立神经元组成,以产生输出。 请注意,我们使用名为neural_simple.txt的文本文件作为输入。
导入有用的包如图所示 -
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nl
加载数据集如下 -
input_data = np.loadtxt(“/Users/admin/neural_simple.txt')
以下是我们将要使用的数据。 请注意,在此数据中,前两列是要素,后两列是标签。
array([[2. , 4. , 0. , 0. ],
[1.5, 3.9, 0. , 0. ],
[2.2, 4.1, 0. , 0. ],
[1.9, 4.7, 0. , 0. ],
[5.4, 2.2, 0. , 1. ],
[4.3, 7.1, 0. , 1. ],
[5.8, 4.9, 0. , 1. ],
[6.5, 3.2, 0. , 1. ],
[3. , 2. , 1. , 0. ],
[2.5, 0.5, 1. , 0. ],
[3.5, 2.1, 1. , 0. ],
[2.9, 0.3, 1. , 0. ],
[6.5, 8.3, 1. , 1. ],
[3.2, 6.2, 1. , 1. ],
[4.9, 7.8, 1. , 1. ],
[2.1, 4.8, 1. , 1. ]])
现在,将这四列分成2个数据列和2个标签 -
data = input_data[:, 0:2]
labels = input_data[:, 2:]
使用以下命令绘制输入数据 -
plt.figure()
plt.scatter(data[:,0], data[:,1])
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Input data')
现在,定义每个维度的最小值和最大值,如下所示 -
dim1_min, dim1_max = data[:,0].min(), data[:,0].max()
dim2_min, dim2_max = data[:,1].min(), data[:,1].max()
接下来,定义输出层中的神经元数量,如下所示 -
nn_output_layer = labels.shape[1]
现在,定义一个单层神经网络 -
dim1 = [dim1_min, dim1_max]
dim2 = [dim2_min, dim2_max]
neural_net = nl.net.newp([dim1, dim2], nn_output_layer)
如图所示,训练具有历元数和学习率的神经网络 -
error = neural_net.train(data, labels, epochs = 200, show = 20, lr = 0.01)
现在,使用以下命令可视化并绘制训练进度 -
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.title('Training error progress')
plt.grid()
plt.show()
现在,使用上面分类器中的测试数据点 -
print('\nTest Results:')
data_test = [[1.5, 3.2], [3.6, 1.7], [3.6, 5.7],[1.6, 3.9]] for item in data_test:
print(item, '-->', neural_net.sim([item])[0])
您可以在此处找到测试结果 -
[1.5, 3.2] --> [1. 0.]
[3.6, 1.7] --> [1. 0.]
[3.6, 5.7] --> [1. 1.]
[1.6, 3.9] --> [1. 0.]
您可以看到以下图表作为到目前为止讨论的代码的输出 -
多层神经网络
在这个例子中,我们创建了一个多层神经网络,它由多个层组成,以提取训练数据中的底层模式。 这种多层神经网络将像回归器一样工作。 我们将基于以下等式生成一些数据点:y = 2x 2 +8。
如图所示导入必要的包 -
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nl
基于上述等式生成一些数据点 -
min_val = -30
max_val = 30
num_points = 160
x = np.linspace(min_val, max_val, num_points)
y = 2 * np.square(x) + 8
y /= np.linalg.norm(y)
现在,重塑此数据集如下 -
data = x.reshape(num_points, 1)
labels = y.reshape(num_points, 1)
使用以下命令可视化和绘制输入数据集 -
plt.figure()
plt.scatter(data, labels)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Data-points')
现在,构建具有两个隐藏层的神经网络,其中神经元在第一个隐藏层中具有ten神经元,在第二个隐藏层中具有six神经元,在输出层中具有一个神经元。
neural_net = nl.net.newff([[min_val, max_val]], [10, 6, 1])
现在使用渐变训练算法 -
neural_net.trainf = nl.train.train_gd
现在训练网络的目的是学习上面生成的数据 -
error = neural_net.train(data, labels, epochs = 1000, show = 100, goal = 0.01)
现在,在训练数据点上运行神经网络 -
output = neural_net.sim(data)
y_pred = output.reshape(num_points)
现在绘图和可视化任务 -
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Error')
plt.title('Training error progress')
现在我们将绘制实际与预测的输出 -
x_dense = np.linspace(min_val, max_val, num_points * 2)
y_dense_pred = neural_net.sim(x_dense.reshape(x_dense.size,1)).reshape(x_dense.size)
plt.figure()
plt.plot(x_dense, y_dense_pred, '-', x, y, '.', x, y_pred, 'p')
plt.title('Actual vs predicted')
plt.show()
作为上述命令的结果,您可以观察如下所示的图形 -
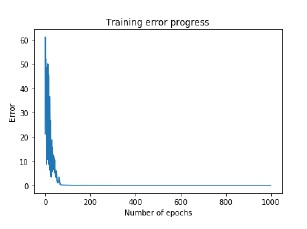
AI with Python – Reinforcement Learning
在本章中,您将详细了解使用Python在AI中强化学习的概念。
强化学习的基础知识
这种类型的学习用于基于评论者信息来加强或加强网络。 也就是说,在强化学习下训练的网络从环境中接收一些反馈。 然而,反馈是有评价性的,而不是像监督学习那样具有指导性。 基于该反馈,网络执行权重的调整以在将来获得更好的批评信息。
这种学习过程类似于监督学习,但我们的信息可能非常少。 下图给出了强化学习的方框图 -
构建块:环境和代理
环境与代理是人工智能强化学习的主要组成部分。 本节将详细讨论它们 -
Agent
代理商是指通过传感器感知其环境并通过效应器对该环境起作用的任何事物。
human agent具有与传感器平行的感觉器官,例如眼睛,耳朵,鼻子,舌头和皮肤,以及用于效应器的其他器官,例如手,腿,嘴。
robotic agent取代传感器的摄像机和红外测距仪,以及用于效应器的各种电机和执行器。
software agent将位串编码为其程序和动作。
代理术语
人工智能中强化学习中使用以下术语 -
Performance Measure of Agent - 这是Performance Measure of Agent成功程度的标准。
Behavior of Agent - 代理在任何给定的感知序列之后执行的操作。
感知 - 它是代理在给定实例中的感知输入。
感知Percept Sequence - 它是代理人迄今为止所感知的所有历史。
Agent Function - 它是从规则序列到动作的映射。
Environment
某些程序在完全artificial environment运行,仅限于键盘输入,数据库,计算机文件系统和屏幕上的字符输出。
相比之下,一些软件代理,如软件机器人或软机器人,存在于丰富且无限的软机器人域中。 模拟器具有very detailed和complex environment 。 软件代理需要实时从一系列动作中进行选择。
例如,设计用于扫描客户的在线偏好并向客户显示有趣项目的软机器人在real artificial environment和artificial environment 。
环境属性
环境具有多重属性,如下所述 -
Discrete/Continuous - 如果环境中有明显不同的,明确定义的状态,则环境是离散的,否则它是连续的。 例如,国际象棋是一个离散的环境,而驾驶是一个连续的环境。
Observable/Partially Observable - 如果可以从感知中确定每个时间点的完整环境状态,则可以观察到; 否则只能部分观察到。
Static/Dynamic - 如果代理正在运行时环境没有改变,那么它是静态的; 否则它是动态的。
Single agent/Multiple agents - 环境可能包含其他代理,这些代理可能与代理的代理相同或不同。
Accessible/Inaccessible - 如果代理的传感设备可以访问完整的环境状态,则该代理可以访问该环境; 否则它是无法访问的。
Deterministic/Non-deterministic - 如果环境的下一个状态完全由当前状态和代理的动作决定,那么环境是确定性的; 否则它是不确定的。
Episodic/Non-episodic - 在情节环境中,每一集都由代理人感知并随后行动起来。 其行动的质量仅取决于剧集本身。 后续剧集不依赖于前一集中的动作。 情境环境要简单得多,因为代理人不需要提前思考。
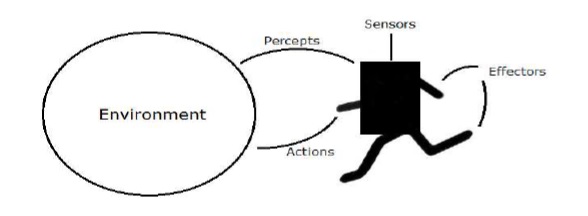
用Python构建环境
为了构建强化学习代理,我们将使用OpenAI Gym软件包,可以在以下命令的帮助下安装 -
pip install gym
OpenAI健身房有各种环境,可用于各种用途。 其中很少是Cartpole-v0, Hopper-v1和MsPacman-v0 。 他们需要不同的引擎。 有关OpenAI Gym的详细文档,请OpenAI Gym https://gym.openai.com/docs/#environments 。
以下代码显示了cartpole-v0环境的Python代码示例 -
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())

您可以以类似的方式构建其他环境。
用Python构建学习代理
对于构建强化学习代理,我们将使用如图所示的OpenAI Gym包 -
import gym
env = gym.make('CartPole-v0')
for _ in range(20):
observation = env.reset()
for i in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(i+1))
break
观察到cartpole可以平衡自己。
AI with Python – Genetic Algorithms
本章详细讨论了人工智能的遗传算法。
什么是遗传算法?
遗传算法(GA)是基于自然选择和遗传概念的基于搜索的算法。 GA是更大的计算分支的子集,称为进化计算。
GA由John Holland及其密歇根大学的学生和同事开发,最着名的是David E. Goldberg。 从那时起,它已经尝试了各种优化问题并取得了很大的成功。
在GA中,我们为给定问题提供了一系列可能的解决方案。 然后这些溶液经历重组和突变(如在天然遗传学中),产生新的儿童,并且该过程重复多代。 为每个个体(或候选解决方案)分配适合度值(基于其目标函数值),并且更健康的个体被赋予更高的交配和屈服个体的机会。 这符合达尔文Survival of the Fittest理论。
因此,它不断evolving更好的个人或解决方案,直到达到停止标准。
遗传算法在本质上是充分随机化的,但它们比随机局部搜索(我们只是尝试随机解决方案,跟踪迄今为止的最佳解决方案)的表现要好得多,因为它们也利用了历史信息。
如何使用GA进行优化问题?
优化是使设计,情况,资源和系统尽可能有效的行动。 以下框图显示了优化过程 -

GA优化过程机制的阶段
以下是用于优化问题的GA机制的一系列步骤。
第1步 - 随机生成初始种群。
第2步 - 选择具有最佳适合度值的初始解决方案。
步骤3 - 使用突变和交叉算子重新组合所选解决方案。
第4步 - 将后代插入人群。
步骤5 - 现在,如果满足停止条件,则返回具有最佳适合度值的解决方案。 否则转到第2步。
安装必要的软件包
为了在Python中使用遗传算法解决问题,我们将使用一个名为DEAP的功能强大的GA包。 它是一个新的进化计算框架库,用于快速原型设计和思想测试。 我们可以在命令提示符下使用以下命令安装此软件包 -
pip install deap
如果您使用的是anaconda环境,那么可以使用以下命令安装deap -
conda install -c conda-forge deap
使用遗传算法实现解决方案
本节介绍使用遗传算法实现解决方案。
生成位模式
以下示例显示如何根据One Max问题生成包含15个的位字符串。
如图所示导入必要的包 -
import random
from deap import base, creator, tools
定义评估功能。 这是创建遗传算法的第一步。
def eval_func(individual):
target_sum = 15
return len(individual) - abs(sum(individual) - target_sum),
现在,使用正确的参数创建工具箱 -
def create_toolbox(num_bits):
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
初始化工具箱
toolbox = base.Toolbox()
toolbox.register("attr_bool", random.randint, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual,
toolbox.attr_bool, num_bits)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
注册评估运算符 -
toolbox.register("evaluate", eval_func)
现在,注册交叉运算符 -
toolbox.register("mate", tools.cxTwoPoint)
注册变异算子 -
toolbox.register("mutate", tools.mutFlipBit, indpb = 0.05)
定义繁殖的运算符 -
toolbox.register("select", tools.selTournament, tournsize = 3)
return toolbox
if __name__ == "__main__":
num_bits = 45
toolbox = create_toolbox(num_bits)
random.seed(7)
population = toolbox.population(n = 500)
probab_crossing, probab_mutating = 0.5, 0.2
num_generations = 10
print('\nEvolution process starts')
评估整个人口 -
fitnesses = list(map(toolbox.evaluate, population))
for ind, fit in zip(population, fitnesses):
ind.fitness.values = fit
print('\nEvaluated', len(population), 'individuals')
创造和迭代几代人 -
for g in range(num_generations):
print("\n- Generation", g)
选择下一代个人 -
offspring = toolbox.select(population, len(population))
现在,克隆选定的个人 -
offspring = list(map(toolbox.clone, offspring))
在后代上应用交叉和变异 -
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < probab_crossing:
toolbox.mate(child1, child2)
删除孩子的健身价值
del child1.fitness.values
del child2.fitness.values
现在,应用变异 -
for mutant in offspring:
if random.random() < probab_mutating:
toolbox.mutate(mutant)
del mutant.fitness.values
评估健康状况无效的个人 -
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
print('Evaluated', len(invalid_ind), 'individuals')
现在,用下一代个人取代人口 -
population[:] = offspring
打印当前世代的统计数据 -
fits = [ind.fitness.values[0] for ind in population]
length = len(population)
mean = sum(fits)/length
sum2 = sum(x*x for x in fits)
std = abs(sum2/length - mean**2)**0.5
print('Min =', min(fits), ', Max =', max(fits))
print('Average =', round(mean, 2), ', Standard deviation =',
round(std, 2))
print("\n- Evolution ends")
打印最终输出 -
best_ind = tools.selBest(population, 1)[0]
print('\nBest individual:\n', best_ind)
print('\nNumber of ones:', sum(best_ind))
Following would be the output:
Evolution process starts
Evaluated 500 individuals
- Generation 0
Evaluated 295 individuals
Min = 32.0 , Max = 45.0
Average = 40.29 , Standard deviation = 2.61
- Generation 1
Evaluated 292 individuals
Min = 34.0 , Max = 45.0
Average = 42.35 , Standard deviation = 1.91
- Generation 2
Evaluated 277 individuals
Min = 37.0 , Max = 45.0
Average = 43.39 , Standard deviation = 1.46
… … … …
- Generation 9
Evaluated 299 individuals
Min = 40.0 , Max = 45.0
Average = 44.12 , Standard deviation = 1.11
- Evolution ends
Best individual:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0,
1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1]
Number of ones: 15
符号回归问题
这是遗传编程中最着名的问题之一。 所有符号回归问题都使用任意数据分布,并尝试使用符号公式拟合最准确的数据。 通常,像RMSE(均方根误差)这样的度量用于衡量个体的适应度。 这是一个经典的回归问题,在这里我们使用等式5x 3 -6x 2 +8x=1 。 我们需要遵循上面示例中的所有步骤,但主要部分是创建原始集,因为它们是个人的构建块,因此评估可以开始。 在这里,我们将使用经典的基元集。
以下Python代码详细解释了这一点 -
import operator
import math
import random
import numpy as np
from deap import algorithms, base, creator, tools, gp
def division_operator(numerator, denominator):
if denominator == 0:
return 1
return numerator/denominator
def eval_func(individual, points):
func = toolbox.compile(expr=individual)
return math.fsum(mse)/len(points),
def create_toolbox():
pset = gp.PrimitiveSet("MAIN", 1)
pset.addPrimitive(operator.add, 2)
pset.addPrimitive(operator.sub, 2)
pset.addPrimitive(operator.mul, 2)
pset.addPrimitive(division_operator, 2)
pset.addPrimitive(operator.neg, 1)
pset.addPrimitive(math.cos, 1)
pset.addPrimitive(math.sin, 1)
pset.addEphemeralConstant("rand101", lambda: random.randint(-1,1))
pset.renameArguments(ARG0 = 'x')
creator.create("FitnessMin", base.Fitness, weights = (-1.0,))
creator.create("Individual",gp.PrimitiveTree,fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=1, max_=2)
toolbox.expr)
toolbox.register("population",tools.initRepeat,list, toolbox.individual)
toolbox.register("compile", gp.compile, pset = pset)
toolbox.register("evaluate", eval_func, points = [x/10. for x in range(-10,10)])
toolbox.register("select", tools.selTournament, tournsize = 3)
toolbox.register("mate", gp.cxOnePoint)
toolbox.register("expr_mut", gp.genFull, min_=0, max_=2)
toolbox.register("mutate", gp.mutUniform, expr = toolbox.expr_mut, pset = pset)
toolbox.decorate("mate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
toolbox.decorate("mutate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
return toolbox
if __name__ == "__main__":
random.seed(7)
toolbox = create_toolbox()
population = toolbox.population(n = 450)
hall_of_fame = tools.HallOfFame(1)
stats_fit = tools.Statistics(lambda x: x.fitness.values)
stats_size = tools.Statistics(len)
mstats = tools.MultiStatistics(fitness=stats_fit, size = stats_size)
mstats.register("avg", np.mean)
mstats.register("std", np.std)
mstats.register("min", np.min)
mstats.register("max", np.max)
probab_crossover = 0.4
probab_mutate = 0.2
number_gen = 10
population, log = algorithms.eaSimple(population, toolbox,
probab_crossover, probab_mutate, number_gen,
stats = mstats, halloffame = hall_of_fame, verbose = True)
请注意,所有基本步骤与生成位模式时使用的相同。 该程序将在10代之后给出输出为min,max,std(标准偏差)。
AI with Python – Computer Vision
计算机视觉涉及使用计算机软件和硬件建模和复制人类视觉。 在本章中,您将详细了解这一点。
计算机视觉
计算机视觉是一门学科,研究如何根据场景中存在的结构的属性,从其2d图像重建,中断和理解3d场景。
计算机视觉层次结构
计算机视觉分为以下三个基本类别 -
Low-level vision - 它包括用于特征提取的过程图像。
Intermediate-level vision - 包括物体识别和3D场景解释
High-level vision - 包括活动,意图和行为等场景的概念性描述。
计算机视觉与图像处理
图像处理研究图像到图像的变换。 图像处理的输入和输出都是图像。
计算机视觉是从图像中构建对物理对象进行明确,有意义的描述。 计算机视觉的输出是对3D场景中的结构的描述或解释。
应用程序 (Applications)
计算机视觉应用于以下领域 -
Robotics
本地化 - 自动确定机器人位置
Navigation
障碍避免
装配(钉孔,焊接,喷漆)
操纵(例如PUMA机器人操纵器)
人机交互(HRI):与人交互和服务的智能机器人
Medicine
分类和检测(例如病变或细胞分类和肿瘤检测)
2D/3D分割
3D人体器官重建(MRI或超声)
视觉引导机器人手术
Security
- 生物识别技术(虹膜,指纹,面部识别)
- 监视 - 检测某些可疑活动或行为
Transportation
- 自动驾驶汽车
- 安全性,例如驾驶员警惕性监控
Industrial Automation Application
- Industrial inspection (defect detection)
- Assembly
- 条形码和包装标签阅读
- 对象排序
- 文件理解(例如OCR)
安装有用的包
对于使用Python的计算机视觉,您可以使用名为OpenCV (开源计算机视觉)的流行库。 它是一个主要针对实时计算机视觉的编程功能库。 它是用C ++编写的,它的主要接口是C ++。 您可以借助以下命令安装此软件包 -
pip install opencv_python-X.X-cp36-cp36m-winX.whl
这里X代表您机器上安装的Python版本以及您拥有的win32或64位。
如果您使用的是anaconda环境,请使用以下命令安装OpenCV -
conda install -c conda-forge opencv
阅读,写作和显示图像
大多数CV应用程序需要将图像作为输入并将图像作为输出生成。 在本节中,您将学习如何借助OpenCV提供的功能读取和写入图像文件。
OpenCV函数用于读取,显示,写入图像文件
OpenCV为此提供以下功能 -
imread() function - 这是读取图像的函数。 OpenCV imread()支持各种图像格式,如PNG,JPEG,JPG,TIFF等。
imshow() function - 这是在窗口中显示图像的功能。 窗口自动适合图像大小。 OpenCV imshow()支持各种图像格式,如PNG,JPEG,JPG,TIFF等。
imwrite() function - 这是写入图像的函数。 OpenCV imwrite()支持各种图像格式,如PNG,JPEG,JPG,TIFF等。
例子 (Example)
此示例显示了用于以一种格式读取图像的Python代码 - 在窗口中显示它并以其他格式写入相同的图像。 考虑以下步骤 -
如图所示导入OpenCV包 -
import cv2
现在,要读取特定图像,请使用imread()函数 -
image = cv2.imread('image_flower.jpg')
要显示图像,请使用imshow()函数。 您可以在其中查看图像的窗口名称为image_flower 。
cv2.imshow('image_flower',image)
cv2.destroyAllwindows()
现在,我们可以使用imwrite()函数将相同的图像写入另一种格式,例如.png -
cv2.imwrite('image_flower.png',image)
输出True表示图像已成功写入.png文件也位于同一文件夹中。
True
注意 - 函数destroyallWindows()只是破坏我们创建的所有窗口。
色彩空间转换
在OpenCV中,图像不是使用传统的RGB颜色存储的,而是以相反的顺序存储,即以BGR顺序存储。 因此,读取图像时的默认颜色代码是BGR。 cvtColor()颜色转换函数用于将图像从一种颜色代码转换为另一种颜色代码。
例子 (Example)
考虑此示例将图像从BGR转换为灰度。
如图所示导入OpenCV包 -
import cv2
现在,要读取特定图像,请使用imread()函数 -
image = cv2.imread('image_flower.jpg')
现在,如果我们使用imshow()函数看到这个图像,那么我们可以看到这个图像在BGR中。
cv2.imshow('BGR_Penguins',image)
现在,使用cvtColor()函数将此图像转换为灰度。
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray_penguins',image)
边缘检测
人们在看到粗略的草图后,可以很容易地识别出许多物体类型和姿势。 这就是边缘在人类生活以及计算机视觉应用中发挥重要作用的原因。 OpenCV提供了非常简单有用的函数Canny()来检测边缘。
例子 (Example)
以下示例显示了边缘的清晰标识。
导入OpenCV包如图所示 -
import cv2
import numpy as np
现在,要读取特定图像,请使用imread()函数。
image = cv2.imread('Penguins.jpg')
现在,使用Canny ()函数检测已读取图像的边缘。
cv2.imwrite(‘edges_Penguins.jpg’,cv2.Canny(image,200,300))
现在,要显示带边的图像,请使用imshow()函数。
cv2.imshow(‘edges’, cv2.imread(‘‘edges_Penguins.jpg’))
这个Python程序将创建一个带边缘检测的名为edges_penguins.jpg的图像。

人脸检测
人脸检测是计算机视觉的迷人应用之一,使其更加真实和未来。 OpenCV具有执行面部检测的内置工具。 我们将使用Haar级联分类器进行人脸检测。
哈尔级联数据
我们需要数据来使用Haar级联分类器。 您可以在我们的OpenCV包中找到这些数据。 安装OpenCv后,您可以看到文件夹名称haarcascades 。 不同的应用程序会有.xml文件。 现在,将它们全部复制以供不同使用,然后粘贴到当前项目下的新文件夹中。
Example
以下是使用Haar Cascade检测Amitabh Bachan面部的Python代码,如下图所示 -

如图所示导入OpenCV包 -
import cv2
import numpy as np
现在,使用HaarCascadeClassifier检测面部 -
face_detection=
cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/
haarcascade_frontalface_default.xml')
现在,要读取特定图像,请使用imread()函数 -
img = cv2.imread('AB.jpg')
现在,将其转换为灰度,因为它会接受灰色图像 -
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
现在,使用face_detection.detectMultiScale ,执行实际的面部检测
faces = face_detection.detectMultiScale(gray, 1.3, 5)
现在,在整个脸部周围画一个矩形 -
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w, y+h),(255,0,0),3)
cv2.imwrite('Face_AB.jpg',img)
这个Python程序将使用面部检测创建一个名为Face_AB.jpg的图像,如图所示

眼睛检测
眼睛检测是计算机视觉的另一个迷人应用,它使其更加真实和未来。 OpenCV有一个内置的工具来执行眼睛检测。 我们将使用Haar cascade分类器进行眼睛检测。
例子 (Example)
以下示例给出了使用Haar Cascade检测Amitabh Bachan面部的Python代码,如下图所示 -

导入OpenCV包如图所示 -
import cv2
import numpy as np
现在,使用HaarCascadeClassifier检测面部 -
eye_cascade = cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/haarcascade_eye.xml')
现在,要读取特定图像,请使用imread()函数
img = cv2.imread('AB_Eye.jpg')
现在,将其转换为灰度,因为它会接受灰色图像 -
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
现在借助eye_cascade.detectMultiScale ,执行实际的人脸检测
eyes = eye_cascade.detectMultiScale(gray, 1.03, 5)
现在,在整个脸部周围画一个矩形 -
for (ex,ey,ew,eh) in eyes:
img = cv2.rectangle(img,(ex,ey),(ex+ew, ey+eh),(0,255,0),2)
cv2.imwrite('Eye_AB.jpg',img)
这个Python程序将创建一个名为Eye_AB.jpg的图像,带有眼睛检测,如图所示 -

AI with Python – Deep Learning
人工神经网络(ANN)是一种高效的计算系统,其中心主题借鉴了生物神经网络的类比。 神经网络是机器学习的一种模型。 在20世纪80年代中期和90年代初期,在神经网络中进行了许多重要的建筑改进。 在本章中,您将了解有关深度学习的更多信息,这是一种人工智能的方法。
深度学习源自十年来爆炸性的计算增长,成为该领域的一个重要竞争者。 因此,深度学习是一种特殊的机器学习,其算法受到人脑结构和功能的启发。
机器学习v/s深度学习
如今,深度学习是最强大的机器学习技术。 它非常强大,因为他们在学习如何解决问题的同时学习了表达问题的最佳方法。 深度学习和机器学习的比较如下 -
数据依赖性
第一个不同点是基于数据规模增加时DL和ML的性能。 当数据量很大时,深度学习算法的表现非常好。
机器依赖
深度学习算法需要高端机器才能完美运行。 另一方面,机器学习算法也可以在低端机器上运行。
特征提取
深度学习算法可以提取高级功能,并尝试从中学习。 另一方面,需要专家识别机器学习提取的大多数特征。
执行时间
执行时间取决于算法中使用的众多参数。 深度学习比机器学习算法具有更多参数。 因此,DL算法的执行时间,特别是训练时间,远远超过ML算法。 但DL算法的测试时间少于ML算法。
解决问题的方法
深度学习解决了端到端的问题,而机器学习使用传统的解决问题的方法,即将其分解为部分。
Convolutional Neural Network (CNN)
卷积神经网络与普通神经网络相同,因为它们也由具有可学习权重和偏差的神经元组成。 普通的神经网络忽略了输入数据的结构,所有数据在送入网络之前都被转换成1-D阵列。 此过程适合常规数据,但是如果数据包含图像,则该过程可能很麻烦。
CNN很容易解决这个问题。 它在处理图像时将图像的2D结构考虑在内,这允许它们提取特定于图像的属性。 这样,CNN的主要目标是从输入层中的原始图像数据转到输出层中的正确类。 普通NN和CNN之间的唯一区别在于输入数据的处理和层的类型。
CNN架构概述
在结构上,普通的神经网络接收输入并通过一系列隐藏层对其进行转换。 在神经元的帮助下,每一层都与另一层相连。 普通神经网络的主要缺点是它们不能很好地扩展到完整图像。
CNN的结构具有以3维度排列的神经元,称为宽度,高度和深度。 当前层中的每个神经元都连接到前一层输出的一小块。 它类似于覆盖????×???? 过滤输入图像。 它使用M过滤器来确保获取所有细节。 这些M滤镜是特征提取器,可以提取边缘,角落等特征。
用于构建CNN的层
以下层用于构建CNN -
Input Layer - 按原样获取原始图像数据。
Convolutional Layer - 该层是CNN的核心构建块,可执行大部分计算。 该层计算神经元与输入中各种补丁之间的卷积。
Rectified Linear Unit Layer - 它将激活功能应用于前一层的输出。 它为网络增加了非线性,因此它可以很好地概括为任何类型的功能。
Pooling Layer - 池化有助于我们在网络中保持重要部分。 池化层在输入的每个深度切片上独立运行,并在空间上调整大小。 它使用MAX功能。
Fully Connected layer/Output layer - 此图层计算最后一层的输出分数。 得到的输出大小为????×????×???? ,其中L是训练数据集类的数量。
安装有用的Python包
你可以使用Keras ,这是一个高级神经网络API,用Python编写,能够运行在TensorFlow,CNTK或Theno之上。 它与Python 2.7-3.6兼容。 您可以从https://keras.io/了解有关它的更多信息。
使用以下命令安装keras -
pip install keras
在conda环境中,您可以使用以下命令 -
conda install –c conda-forge keras
使用ANN构建线性回归量
在本节中,您将学习如何使用人工神经网络构建线性回归量。 您可以使用KerasRegressor来实现此目的。 在这个例子中,我们使用波士顿房价数据集,其中13个数字用于波士顿的房产。 这里显示了相同的Python代码 -
导入所有必需的包,如图所示 -
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
现在,加载保存在本地目录中的数据集。
dataframe = pandas.read_csv("/Usrrs/admin/data.csv", delim_whitespace = True, header = None)
dataset = dataframe.values
现在,将数据分为输入和输出变量,即X和Y -
X = dataset[:,0:13]
Y = dataset[:,13]
由于我们使用基线神经网络,因此定义模型 -
def baseline_model():
现在,按如下方式创建模型 -
model_regressor = Sequential()
model_regressor.add(Dense(13, input_dim = 13, kernel_initializer = 'normal',
activation = 'relu'))
model_regressor.add(Dense(1, kernel_initializer = 'normal'))
接下来,编译模型 -
model_regressor.compile(loss='mean_squared_error', optimizer='adam')
return model_regressor
现在,修复随机种子的重现性如下 -
seed = 7
numpy.random.seed(seed)
用于scikit-learn作为回归估计器的KerasRegressor包装器对象称为KerasRegressor 。 在本节中,我们将使用标准化数据集评估此模型。
estimator = KerasRegressor(build_fn = baseline_model, nb_epoch = 100, batch_size = 5, verbose = 0)
kfold = KFold(n_splits = 10, random_state = seed)
baseline_result = cross_val_score(estimator, X, Y, cv = kfold)
print("Baseline: %.2f (%.2f) MSE" % (Baseline_result.mean(),Baseline_result.std()))
上面显示的代码输出将是模型对看不见的数据问题的性能估计。 它将是均方误差,包括交叉验证评估的所有10倍的平均值和标准差。
图像分类器:深度学习的应用
卷积神经网络(CNN)解决了图像分类问题,即输入图像属于哪个类。 您可以使用Keras深度学习库。 请注意,我们使用以下链接https://www.kaggle.com/c/dogs-vs-cats/data来训练和测试猫狗图像的数据集。
导入重要的keras库和包如图所示 -
以下称为顺序的包将神经网络初始化为顺序网络。
from keras.models import Sequential
以下包称为Conv2D用于执行卷积操作,这是CNN的第一步。
from keras.layers import Conv2D
以下名为MaxPoling2D包用于执行池化操作,这是CNN的第二步。
from keras.layers import MaxPooling2D
以下名为Flatten包是将所有结果2D数组转换为单个长连续线性向量的过程。
from keras.layers import Flatten
以下包称为Dense用于执行神经网络的完整连接,这是CNN的第四步。
from keras.layers import Dense
现在,创建顺序类的对象。
S_classifier = Sequential()
现在,下一步是编码卷积部分。
S_classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
这里relu是整流功能。
现在,CNN的下一步是在卷积部分之后对结果特征映射进行合并操作。
S-classifier.add(MaxPooling2D(pool_size = (2, 2)))
现在,通过使用奉承将所有合并的图像转换为连续的矢量 -
S_classifier.add(Flatten())
接下来,创建一个完全连接的图层。
S_classifier.add(Dense(units = 128, activation = 'relu'))
这里,128是隐藏单元的数量。 通常的做法是将隐藏单位的数量定义为2的幂。
现在,按如下方式初始化输出层 -
S_classifier.add(Dense(units = 1, activation = 'sigmoid'))
现在,编译CNN,我们已经建立 -
S_classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
这里的优化器参数是选择随机梯度下降算法,损耗参数是选择损失函数而度量参数是选择性能指标。
现在,执行图像增强,然后将图像拟合到神经网络 -
train_datagen = ImageDataGenerator(rescale = 1./255,shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
training_set =
train_datagen.flow_from_directory(”/Users/admin/training_set”,target_size =
(64, 64),batch_size = 32,class_mode = 'binary')
test_set =
test_datagen.flow_from_directory('test_set',target_size =
(64, 64),batch_size = 32,class_mode = 'binary')
现在,将数据拟合到我们创建的模型中 -
classifier.fit_generator(training_set,steps_per_epoch = 8000,epochs =
25,validation_data = test_set,validation_steps = 2000)
这里steps_per_epoch具有训练图像的数量。
现在,模型已经过培训,我们可以将其用于预测,如下所示 -
from keras.preprocessing import image
test_image = image.load_img('dataset/single_prediction/cat_or_dog_1.jpg',
target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
if result[0][0] == 1:
prediction = 'dog'
else:
prediction = 'cat'
