JPA - ORM组件( ORM Components)
大多数现代应用程序使用关系数据库来存储数据。 最近,许多供应商转而使用对象数据库来减轻数据维护的负担。 这意味着对象数据库或对象关系技术正在处理存储,检索,更新和维护。 此对象关系技术的核心部分是映射orm.xml文件。 由于xml不需要编译,因此我们可以轻松地对管理多个数据源进行更改。
对象关系映射
对象关系映射(ORM)简要介绍了什么是ORM以及它是如何工作的。 ORM是一种编程功能,可以将数据从对象类型转换为关系类型,反之亦然。
ORM的主要功能是将对象映射或绑定到数据库中的数据。 在映射时,我们必须考虑数据,数据类型及其与任何其他表中的自身实体或实体的关系。
高级功能
Idiomatic persistence :它使您能够使用面向对象的类编写持久性类。
High Performance :它有许多提取技术和有希望的锁定技术。
Reliable :高度稳定,卓越。 被许多工业程序员使用。
ORM架构
遵循ORM架构。
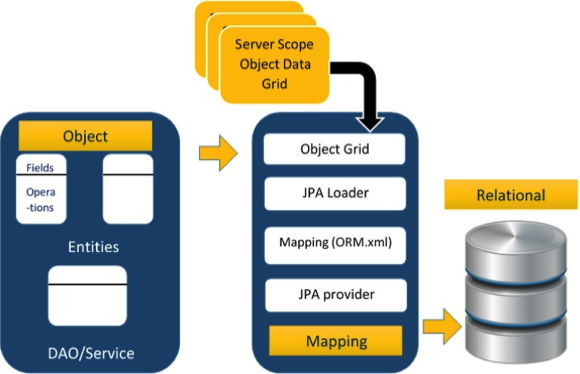
上述架构解释了如何将对象数据分三个阶段存储到关系数据库中。
Phase1
第一个阶段,称为Object data阶段,包含POJO类,服务接口和类。 它是主要的业务组件层,具有业务逻辑操作和属性。
例如,让我们将员工数据库作为模式 -
Employee POJO类包含ID,名称,工资和指定等属性。 以及这些属性的setter和getter方法等方法。
员工DAO /服务类包含服务方法,例如创建员工,查找员工和删除员工。
阶段2
第二阶段称为mapping或persistence阶段,包含JPA提供程序,映射文件(ORM.xml),JPA Loader和Object Grid。
JPA Provider :包含JPA flavor(javax.persistence)的供应商产品。 例如Eclipselink,Toplink,Hibernate等。
Mapping file :映射文件(ORM.xml)包含POJO类中的数据与关系数据库中的数据之间的映射配置。
JPA Loader :JPA加载器的工作方式类似于缓存内存,它可以加载关系网格数据。 它的工作方式类似于数据库的副本,以便与POJO数据的服务类进行交互(POJO类的属性)。
Object Grid :对象网格是一个临时位置,可以存储关系数据的副本,即缓存内存。 对数据库的所有查询首先对对象网格中的数据进行。 只有在提交后,它才会影响主数据库。
第3阶段
第三阶段是关系数据阶段。 它包含逻辑上连接到业务组件的关系数据。 如上所述,仅当业务组件提交数据时,它才被物理地存储到数据库中。 在此之前,修改后的数据作为网格格式存储在高速缓冲存储器中。 获取数据的过程也是如此。
上述三个阶段的程序化交互机制称为对象关系映射。
Mapping.xml
mapping.xml文件用于指示JPA供应商将Entity类与数据库表进行映射。
让我们举一个包含四个属性的Employee实体的例子。 名为Employee.java的Employee实体的POJO类如下:
public class Employee {
private int eid;
private String ename;
private double salary;
private String deg;
public Employee(int eid, String ename, double salary, String deg) {
super( );
this.eid = eid;
this.ename = ename;
this.salary = salary;
this.deg = deg;
}
public Employee( ) {
super();
}
public int getEid( ) {
return eid;
}
public void setEid(int eid) {
this.eid = eid;
}
public String getEname( ) {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public double getSalary( ) {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public String getDeg( ) {
return deg;
}
public void setDeg(String deg) {
this.deg = deg;
}
}
上面的代码是Employee实体POJO类。 它包含四个属性eid,ename,salary和deg。 请考虑这些属性是数据库中的表字段,eid是此表的主键。 现在我们必须为它设计hibernate映射文件。 名为mapping.xml的映射文件如下:
<? xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_1_0.xsd"
version="1.0">
<description> XML Mapping file</description>
<entity class="Employee">
<table name="EMPLOYEETABLE"/>
<attributes>
<id name="eid">
<generated-value strategy="TABLE"/>
</id>
<basic name="ename">
<column name="EMP_NAME" length="100"/>
</basic>
<basic name="salary">
</basic>
<basic name="deg">
</basic>
</attributes>
</entity>
</entity-mappings>
上面的脚本用于将实体类映射到数据库表。 在这个文件中
《entity-mappings》 :tag定义模式定义以允许实体标签进入xml文件。
《description》 :标签定义关于应用程序的描述。
《entity》 :tag定义要在数据库中转换为表的实体类。 Attribute类定义POJO实体类名。
《table》 :标签定义表名。 如果要将类名保存为表名,则不需要此标记。
《attributes》 :标签定义属性(表中的字段)。
《id》 :tag定义表的主键。 《generated-value》标签定义了如何分配主键值,例如Automatic,Manual或从Sequence中获取。
《basic》 :标记用于定义表的剩余属性。
《column-name》 :标记用于定义用户定义的表字段名称。
注解 Annotations
通常,Xml文件用于配置特定组件,或映射两种不同规格的组件。 在我们的例子中,我们必须在框架中单独维护xml。 这意味着在编写映射xml文件时,我们需要将POJO类属性与mapping.xml文件中的实体标记进行比较。
这是解决方案:在类定义中,我们可以使用注释编写配置部分。 注释用于类,属性和方法。 注释以“@”符号开头。 在声明类,属性或方法之前声明注释。 JPA的所有注释都在javax.persistence包中定义。
以下是我们的示例中使用的注释列表
| 注解 | 描述 |
|---|---|
| @Entity | 此批注指定将类声明为实体或表。 |
| @Table | 此批注指定声明表名。 |
| @Basic | 此批注明确指定非约束字段。 |
| @Embedded | 此批注指定类或实体的属性,该实体的可嵌入类的值实例。 |
| @Id | 此批注指定属性,用于类的标识(表的主键)。 |
| @GeneratedValue | 此批注指定了如何初始化标识属性,例如自动,手动或从序列表中获取的值。 |
| @Transient | 此批注指定了不持久的属性,即该值永远不会存储到数据库中。 |
| @Column | 此批注用于指定持久性属性的列或属性。 |
| @SequenceGenerator | 此批注用于定义@GeneratedValue批注中指定的属性的值。 它创建了一个序列。 |
| @TableGenerator | 此批注用于指定@GeneratedValue批注中指定的属性的值生成器。 它创建了一个价值生成表。 |
| @AccessType | 此类注释用于设置访问类型。 如果设置@AccessType(FIELD),则会发生字段访问。 如果设置@AccessType(PROPERTY),则将进行Property wise评估。 |
| @JoinColumn | 此批注用于指定实体关联或实体集合。 这用于多对一和一对多关联。 |
| @UniqueConstraint | 此批注用于指定主要或辅助表的字段,唯一约束。 |
| @ColumnResult | 此批注使用select子句引用SQL查询中的列的名称。 |
| @ManyToMany | 此批注用于定义连接表之间的多对多关系。 |
| @ManyToOne | 此批注用于定义连接表之间的多对一关系。 |
| @OneToMany | 此批注用于定义连接表之间的一对多关系。 |
| @OneToOne | 此批注用于定义连接表之间的一对一关系。 |
| @NamedQueries | 此批注用于指定命名查询的列表。 |
| @NamedQuery | 此批注用于使用静态名称指定查询。 |
Java Bean标准
Java类将实例值和行为封装到单个单元调用对象中。 Java Bean是临时存储和可重用组件或对象。 它是一个可序列化的类,它具有默认的构造函数和getter&setter方法,可以单独初始化实例属性。
Bean约定
Bean包含默认构造函数或包含序列化实例的文件。 因此,bean可以实例化bean。
bean的属性可以分为布尔属性和非布尔属性。
非布尔属性包含getter和setter方法。
布尔属性包含setter并且is方法。
任何属性的Getter方法都应该以小字母'get'(java方法约定)开头,并继续使用以大写字母开头的字段名称。 例如,字段名称是'salary',因此该字段的getter方法是'getSalary()'。
任何属性的Setter方法都应该以小字母'set'(java方法约定)开头,继续使用以大写字母开头的字段名称和设置为field的参数值。 例如,字段名称是'salary',因此该字段的setter方法是'setSalary(double sal)'。
对于Boolean属性,是检查它是true还是false的方法。 例如,布尔属性'empty',此字段的is方法是'isEmpty()'。
