Python - 快速指南
Python Overview
Python是一种高级,解释,交互式和面向对象的脚本语言。 Python的设计具有高可读性。 它经常使用英语关键词,而其他语言使用标点符号,并且它的语法结构比其他语言少。
Python is Interpreted - Python在运行时由解释器处理。 在执行程序之前,您无需编译程序。 这类似于PERL和PHP。
Python is Interactive - 您实际上可以坐在Python提示符下并直接与解释器交互来编写程序。
Python is Object-Oriented - Python支持面向对象的样式或编程技术,它将代码封装在对象中。
Python is a Beginner's Language - Python是初学者级程序员的优秀语言,支持从简单的文本处理到WWW浏览器到游戏的各种应用程序的开发。
Python的历史
Python由Guido van Rossum在八十年代末和九十年代初在荷兰国家数学和计算机科学研究所开发。
Python源自许多其他语言,包括ABC,Modula-3,C,C ++,Algol-68,SmallTalk和Unix shell以及其他脚本语言。
Python受版权保护。 与Perl一样,Python源代码现在可以在GNU通用公共许可证(GPL)下使用。
Python现在由该研究所的核心开发团队维护,尽管Guido van Rossum在指导其进展方面仍然发挥着至关重要的作用。
Python Features
Python的功能包括 -
Easy-to-learn - Python几乎没有关键字,结构简单,语法清晰。 这允许学生快速学习语言。
Easy-to-read - Python代码更清晰,更明显。
Easy-to-maintain - Python的源代码非常易于维护。
A broad standard library - Python的大部分库在UNIX,Windows和Macintosh上非常便携且跨平台兼容。
Interactive Mode - Python支持交互模式,允许交互式测试和调试代码片段。
Portable - Python可以在各种硬件平台上运行,并且在所有平台上都具有相同的界面。
Extendable - 您可以向Python解释器添加低级模块。 这些模块使程序员能够更高效地添加或定制他们的工具。
Databases - Python为所有主要商业数据库提供接口。
GUI Programming - Python支持GUI应用程序,可以创建和移植到许多系统调用,库和Windows系统,如Windows MFC,Macintosh和Unix的X Window系统。
Scalable - 与shell脚本相比,Python为大型程序提供了更好的结构和支持。
除了上述功能外,Python还有很多优秀的功能,下面列出的很少 -
它支持功能和结构化编程方法以及OOP。
它可以用作脚本语言,也可以编译为字节码来构建大型应用程序。
它提供非常高级的动态数据类型,并支持动态类型检查。
它支持自动垃圾收集。
它可以很容易地与C,C ++,COM,ActiveX,CORBA和Java集成。
Python - Environment Setup
Python可用于各种平台,包括Linux和Mac OS X.让我们了解如何设置Python环境。
本地环境设置 (Local Environment Setup)
打开终端窗口并键入“python”以查明它是否已安装以及安装了哪个版本。
- Unix(Solaris,Linux,FreeBSD,AIX,HP/UX,SunOS,IRIX等)
- Win 9x/NT/2000
- Macintosh (Intel, PPC, 68K)
- OS/2
- DOS(多个版本)
- PalmOS
- Nokia mobile phones
- Windows CE
- Acorn/RISC OS
- BeOS
- Amiga
- VMS/OpenVMS
- QNX
- VxWorks
- Psion
- Python也已移植到Java和.NET虚拟机
获取Python
最新和最新的源代码,二进制文件,文档,新闻等,可在Python官方网站https://www.python.org/
您可以从https://www.python.org/doc/下载Python文档。 该文档以HTML,PDF和PostScript格式提供。
安装Python (Installing Python)
Python发行版适用于各种平台。 您只需下载适用于您的平台的二进制代码并安装Python。
如果您的平台的二进制代码不可用,则需要C编译器手动编译源代码。 编译源代码在选择安装所需的功能方面提供了更大的灵活性。
以下是在各种平台上安装Python的快速概述 -
Unix和Linux安装
以下是在Unix/Linux机器上安装Python的简单步骤。
打开Web浏览器并转到https://www.python.org/downloads/ 。
点击链接下载适用于Unix/Linux的压缩源代码。
下载并解压缩文件。
如果要自定义某些选项,请编辑Modules/Setup文件。
运行./configure脚本
make
make install
这将在标准位置/usr/local/bin及其库中安装Python,位于/usr/local/lib/pythonXX ,其中XX是Python的版本。
Windows安装 (Windows Installation)
以下是在Windows机器上安装Python的步骤。
打开Web浏览器并转到https://www.python.org/downloads/ 。
按照Windows安装程序python-XYZ.msi文件的链接进行操作,其中XYZ是您需要安装的版本。
要使用此安装程序python-XYZ.msi ,Windows系统必须支持Microsoft Installer 2.0。 将安装程序文件保存到本地计算机,然后运行它以查明您的计算机是否支持MSI。
运行下载的文件。 这将打开Python安装向导,它非常易于使用。 只需接受默认设置,等到安装完成,然后就完成了。
Macintosh安装
最近的Mac安装了Python,但它可能已经过时了几年。 有关获取当前版本以及支持Mac上开发的其他工具的说明,请http://www.python.org/download/mac/ 。 对于Mac OS X 10.3(2003年发布)之前的旧Mac OS,可以使用MacPython。
Jack Jansen维护它,您可以在他的网站http://www.cwi.nl/~jack/macpython.html完全访问整个文档。 您可以找到Mac OS安装的完整安装详细信息。
设置PATH (Setting up PATH)
程序和其他可执行文件可以位于许多目录中,因此操作系统提供了一个搜索路径,列出了OS搜索可执行文件的目录。
该路径存储在环境变量中,该变量是由操作系统维护的命名字符串。 此变量包含命令shell和其他程序可用的信息。
path变量在Unix中命名为PATH,在Windows中命名为Path(Unix区分大小写; Windows不是)。
在Mac OS中,安装程序会处理路径详细信息。 要从任何特定目录调用Python解释器,必须将Python目录添加到路径中。
在Unix/Linux上设置路径
要将Python目录添加到Unix中特定会话的路径 -
In the csh shell - 键入setenv PATH“$ PATH:/ usr/local/bin/python”并按Enter键。
In the bash shell (Linux) - 键入export ATH =“$ PATH:/ usr/local/bin/python”并按Enter键。
In the sh or ksh shell - 键入PATH =“$ PATH:/ usr/local/bin/python”并按Enter键。
Note - /usr/local/bin/python是Python目录的路径
在Windows上设置路径
要将Python目录添加到Windows中特定会话的路径中 -
At the command prompt - 键入path%path%; C:\Python并按Enter键。
Note - C:\Python是Python目录的路径
Python Environment Variables
以下是重要的环境变量,可以被Python识别 -
| Sr.No. | 变量和描述 |
|---|---|
| 1 | PYTHONPATH 它的作用类似于PATH。 此变量告诉Python解释器在何处找到导入程序的模块文件。 它应该包括Python源库目录和包含Python源代码的目录。 PYTHONPATH有时由Python安装程序预设。 |
| 2 | PYTHONSTARTUP 它包含包含Python源代码的初始化文件的路径。 每次启动解释器时都会执行它。 它在Unix中命名为.pythonrc.py,它包含加载实用程序或修改PYTHONPATH的命令。 |
| 3 | PYTHONCASEOK 它在Windows中用于指示Python在import语句中找到第一个不区分大小写的匹配项。 将此变量设置为任何值以激活它。 |
| 4 | PYTHONHOME 它是另一种模块搜索路径。 它通常嵌入在PYTHONSTARTUP或PYTHONPATH目录中,以便于切换模块库。 |
运行Python (Running Python)
启动Python有三种不同的方法 -
交互式解释器 (Interactive Interpreter)
您可以从Unix,DOS或任何其他为您提供命令行解释器或shell窗口的系统启动Python。
输入python命令行。
立即在交互式解释器中开始编码。
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOS
以下是所有可用命令行选项的列表 -
| Sr.No. | 选项和说明 |
|---|---|
| 1 | -d 它提供调试输出。 |
| 2 | -O 它生成优化的字节码(产生.pyo文件)。 |
| 3 | -S 不要运行导入站点以在启动时查找Python路径。 |
| 4 | -v 详细输出(导入语句的详细跟踪)。 |
| 5 | -X 禁用基于类的内置异常(只使用字符串); 从版本1.6开始过时。 |
| 6 | -c cmd 运行以cmd字符串形式发送的Python脚本 |
| 7 | file 从给定文件运行Python脚本 |
命令行脚本 (Script from the Command-line)
可以通过在应用程序上调用解释器在命令行执行Python脚本,如下所示 -
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOS
Note - 确保文件权限模式允许执行。
集成开发环境 (Integrated Development Environment)
如果您的系统上有支持Python的GUI应用程序,您也可以从图形用户界面(GUI)环境运行Python。
Unix - IDLE是第一个用于Python的Unix IDE。
Windows - PythonWin是第一个用于Python的Windows界面,是一个带有GUI的IDE。
Macintosh - 可以从主网站获得Macintosh版本的Python以及IDLE IDE,可以下载为MacBinary或BinHex'd文件。
如果您无法正确设置环境,则可以从系统管理员处获取帮助。 确保Python环境设置正确并且工作正常。
Note - 后续章节中给出的所有示例都是使用CentOS版Linux上的Python 2.4.3版本执行的。
我们已经在线设置了Python编程环境,因此您可以在学习理论的同时在线执行所有可用的示例。 随意修改任何示例并在线执行。
Python - Basic Syntax
Python语言与Perl,C和Java有许多相似之处。 但是,语言之间存在一些明显的差异。
第一个Python程序
让我们以不同的编程模式执行程序。
交互模式编程 (Interactive Mode Programming)
在不将脚本文件作为参数传递的情况下调用解释器会显示以下提示 -
$ python
Python 2.4.3 (#1, Nov 11 2010, 13:34:43)
[GCC 4.1.2 20080704 (Red Hat 4.1.2-48)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
在Python提示符下键入以下文本,然后按Enter键 -
>>> print "Hello, Python!"
如果你正在运行新版本的Python,那么你需要在print中使用带括号的print语句print ("Hello, Python!"); 。 但是在Python 2.4.3版本中,这会产生以下结果 -
Hello, Python!
脚本模式编程
使用脚本参数调用解释器开始执行脚本并继续直到脚本完成。 脚本完成后,解释器不再处于活动状态。
让我们在脚本中编写一个简单的Python程序。 Python文件扩展名为.py 。 在test.py文件中键入以下源代码 -
print "Hello, Python!"
我们假设您在PATH变量中设置了Python解释器。 现在,尝试运行此程序如下 -
$ python test.py
这会产生以下结果 -
Hello, Python!
让我们尝试另一种方法来执行Python脚本。 这是修改后的test.py文件 -
#!/usr/bin/python
print "Hello, Python!"
我们假设您在/ usr/bin目录中提供了Python解释器。 现在,尝试运行此程序如下 -
$ chmod +x test.py # This is to make file executable
$./test.py
这会产生以下结果 -
Hello, Python!
Python Identifiers
Python标识符是用于标识变量,函数,类,模块或其他对象的名称。 标识符以字母A到Z或a到z或下划线(_)开头,后跟零个或多个字母,下划线和数字(0到9)。
Python不允许在标识符中使用标点符号,如@,$和%。 Python是一种区分大小写的编程语言。 因此, Manpower和manpower是Python中的两个不同的标识符。
以下是Python标识符的命名约定 -
类名以大写字母开头。 所有其他标识符以小写字母开头。
使用单个前导下划线启动标识符表示标识符是私有的。
启动带有两个前导下划线的标识符表示强私有标识符。
如果标识符也以两个尾部下划线结尾,则标识符是语言定义的特殊名称。
保留字 (Reserved Words)
以下列表显示了Python关键字。 这些是保留字,您不能将它们用作常量或变量或任何其他标识符名称。 所有Python关键字仅包含小写字母。
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
线条和缩进
Python没有提供大括号来指示类和函数定义或流控制的代码块。 代码块由行缩进表示,这是严格执行的。
缩进中的空格数是可变的,但块内的所有语句必须缩进相同的数量。 例如 -
if True:
print "True"
else:
print "False"
但是,以下块生成错误 -
if True:
print "Answer"
print "True"
else:
print "Answer"
print "False"
因此,在Python中,所有用相同数量的空格缩进的连续线将形成一个块。 以下示例具有各种语句块 -
Note - 此时不要试图理解逻辑。 只要确保你理解各种块,即使它们没有支撑也是如此。
#!/usr/bin/python
import sys
try:
# open file stream
file = open(file_name, "w")
except IOError:
print "There was an error writing to", file_name
sys.exit()
print "Enter '", file_finish,
print "' When finished"
while file_text != file_finish:
file_text = raw_input("Enter text: ")
if file_text == file_finish:
# close the file
file.close
break
file.write(file_text)
file.write("\n")
file.close()
file_name = raw_input("Enter filename: ")
if len(file_name) == 0:
print "Next time please enter something"
sys.exit()
try:
file = open(file_name, "r")
except IOError:
print "There was an error reading file"
sys.exit()
file_text = file.read()
file.close()
print file_text
Multi-Line Statements
Python中的语句通常以新行结束。 但是,Python确实允许使用行继续符(\)来表示该行应该继续。 例如 -
total = item_one + \
item_two + \
item_three
[],{}或()括号中包含的语句不需要使用行继续符。 例如 -
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
Python中的报价
Python接受单引号('),双引号(“)和三引号('''或”“”)来表示字符串文字,只要相同类型的引号开始和结束字符串即可。
三引号用于跨越多行跨越字符串。 例如,以下所有内容都是合法的 -
word = 'word'
sentence = "This is a sentence."
paragraph = """This is a paragraph. It is
made up of multiple lines and sentences."""
Python中的评论
不在字符串文字内的井号(#)开始注释。 #之后的所有字符和直到物理行的末尾都是注释的一部分,Python解释器忽略它们。
#!/usr/bin/python
# First comment
print "Hello, Python!" # second comment
这会产生以下结果 -
Hello, Python!
您可以在语句或表达式后的同一行上键入注释 -
name = "Madisetti" # This is again comment
您可以按如下方式评论多行 -
# This is a comment.
# This is a comment, too.
# This is a comment, too.
# I said that already.
使用空行
只包含空格(可能带有注释)的行称为空行,Python完全忽略它。
在交互式解释器会话中,必须输入空物理行以终止多行语句。
等待用户
程序的以下行显示提示,声明“按回车键退出”,并等待用户采取行动 -
#!/usr/bin/python
raw_input("\n\nPress the enter key to exit.")
这里,“\ n\n”用于在显示实际行之前创建两个新行。 一旦用户按下该键,程序就结束。 这是一个很好的技巧,可以在用户完成应用程序之前保持控制台窗口打开。
单行上的多个语句
分号(;)允许单行上的多个语句,因为两个语句都不会启动新的代码块。 这是使用分号的示例片段 -
import sys; x = 'foo'; sys.stdout.write(x + '\n')
多个语句组作为套件
一组单独的语句,它们构成一个代码块,在Python中称为suites 。 复合或复杂语句(例如if,while,def和class)需要标题行和套件。
标题行开始语句(带有关键字)并以冒号(:)结束,后跟一行或多行组成套件。 例如 -
if expression :
suite
elif expression :
suite
else :
suite
Command Line Arguments
可以运行许多程序来为您提供有关如何运行它们的一些基本信息。 Python使您可以使用-h执行此操作
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]
您还可以对脚本进行编程,使其接受各种选项。 命令行参数是一个高级主题,一旦您完成其余的Python概念,应该稍后研究。
Python - Variable Types
变量只是用于存储值的保留内存位置。 这意味着当您创建变量时,您在内存中保留了一些空间。
根据变量的数据类型,解释器分配内存并决定可以存储在保留内存中的内容。 因此,通过为变量分配不同的数据类型,可以在这些变量中存储整数,小数或字符。
将值分配给变量
Python变量不需要显式声明来保留内存空间。 为变量赋值时,声明会自动发生。 等号(=)用于为变量赋值。
=运算符左边的操作数是变量的名称,=运算符右边的操作数是存储在变量中的值。 例如 -
#!/usr/bin/python
counter = 100 # An integer assignment
miles = 1000.0 # A floating point
name = "John" # A string
print counter
print miles
print name
这里,100,1000.0和“John”分别是分配给counter , miles和name变量的值。 这会产生以下结果 -
100
1000.0
John
多次分配
Python允许您同时为多个变量分配单个值。 例如 -
a = b = c = 1
这里,使用值1创建整数对象,并将所有三个变量分配给相同的内存位置。 您还可以将多个对象分配给多个变量。 例如 -
a,b,c = 1,2,"john"
这里,两个值为1和2的整数对象分别分配给变量a和b,一个值为“john”的字符串对象分配给变量c。
标准数据类型
存储在存储器中的数据可以是多种类型。 例如,一个人的年龄被存储为数字值,他或她的地址被存储为字母数字字符。 Python有各种标准数据类型,用于定义它们可能的操作以及每个类型的存储方法。
Python有五种标准数据类型 -
- Numbers
- String
- List
- Tuple
- Dictionary
Python Numbers
数字数据类型存储数值。 为它们分配值时会创建数字对象。 例如 -
var1 = 1
var2 = 10
您还可以使用del语句删除对数字对象的引用。 del语句的语法是 -
del var1[,var2[,var3[....,varN]]]]
您可以使用del语句删除单个对象或多个对象。 例如 -
del var
del var_a, var_b
Python支持四种不同的数字类型 -
- int (signed integers)
- long(长整数,它们也可以用八进制和十六进制表示)
- float(浮点实数值)
- complex (complex numbers)
例子 (Examples)
以下是一些数字示例 -
| INT | 长 | 浮动 | 复杂 |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3+e18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7j |
Python允许你使用带有long的小写l,但是建议你只使用大写的L来避免与数字1混淆.Python使用大写的L显示长整数。
复数由一对有序的实数浮点数组成,用x + yj表示,其中x和y是实数,j是虚数。
Python Strings
Python中的字符串被标识为引号中表示的连续字符集。 Python允许使用单引号或双引号。 可以使用切片运算符([]和[:])获取字符串子集,索引从字符串开头的0开始,并从最后的-1开始。
加号(+)是字符串连接运算符,星号(*)是重复运算符。 例如 -
#!/usr/bin/python
str = 'Hello World!'
print str # Prints complete string
print str[0] # Prints first character of the string
print str[2:5] # Prints characters starting from 3rd to 5th
print str[2:] # Prints string starting from 3rd character
print str * 2 # Prints string two times
print str + "TEST" # Prints concatenated string
这将产生以下结果 -
Hello World!
H
llo
llo World!
Hello World!Hello World!
Hello World!TEST
Python Lists
列表是Python中最通用的复合数据类型。 列表包含以逗号分隔的项目,并用方括号([])括起来。 在某种程度上,列表类似于C中的数组。它们之间的一个区别是属于列表的所有项目可以是不同的数据类型。
存储在列表中的值可以使用切片运算符([]和[:])进行访问,索引从列表开头的0开始,然后一直运行到结束-1。 加号(+)是列表连接运算符,星号(*)是重复运算符。 例如 -
#!/usr/bin/python
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
print list # Prints complete list
print list[0] # Prints first element of the list
print list[1:3] # Prints elements starting from 2nd till 3rd
print list[2:] # Prints elements starting from 3rd element
print tinylist * 2 # Prints list two times
print list + tinylist # Prints concatenated lists
这产生以下结果 -
['abcd', 786, 2.23, 'john', 70.2]
abcd
[786, 2.23]
[2.23, 'john', 70.2]
[123, 'john', 123, 'john']
['abcd', 786, 2.23, 'john', 70.2, 123, 'john']
Python Tuples
元组是另一种与列表类似的序列数据类型。 元组由逗号分隔的许多值组成。 但是,与列表不同,元组括在括号内。
列表和元组之间的主要区别是:列表括在括号([])中,它们的元素和大小可以更改,而元组括在括号(()中)并且无法更新。 元组可以被认为是read-only列表。 例如 -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
tinytuple = (123, 'john')
print tuple # Prints complete list
print tuple[0] # Prints first element of the list
print tuple[1:3] # Prints elements starting from 2nd till 3rd
print tuple[2:] # Prints elements starting from 3rd element
print tinytuple * 2 # Prints list two times
print tuple + tinytuple # Prints concatenated lists
这产生以下结果 -
('abcd', 786, 2.23, 'john', 70.2)
abcd
(786, 2.23)
(2.23, 'john', 70.2)
(123, 'john', 123, 'john')
('abcd', 786, 2.23, 'john', 70.2, 123, 'john')
以下代码对元组无效,因为我们尝试更新元组,这是不允许的。 列表可能有类似的情况 -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # Invalid syntax with tuple
list[2] = 1000 # Valid syntax with list
Python Dictionary
Python的字典是一种哈希表类型。 它们像在Perl中找到的关联数组或哈希一样工作,并由键值对组成。 字典键几乎可以是任何Python类型,但通常是数字或字符串。 另一方面,值可以是任意Python对象。
字典用大括号({})括起来,可以使用方括号([])分配和访问值。 例如 -
#!/usr/bin/python
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'john','code':6734, 'dept': 'sales'}
print dict['one'] # Prints value for 'one' key
print dict[2] # Prints value for 2 key
print tinydict # Prints complete dictionary
print tinydict.keys() # Prints all the keys
print tinydict.values() # Prints all the values
这产生以下结果 -
This is one
This is two
{'dept': 'sales', 'code': 6734, 'name': 'john'}
['dept', 'code', 'name']
['sales', 6734, 'john']
字典在元素之间没有顺序概念。 说元素是“乱序”是不正确的; 它们只是无序的。
数据类型转换
有时,您可能需要在内置类型之间执行转换。 要在类型之间进行转换,只需使用类型名称作为函数。
有几个内置函数可以执行从一种数据类型到另一种数据类型的转换。 这些函数返回表示转换值的新对象。
| Sr.No. | 功能说明 |
|---|---|
| 1 | int(x [,base]) 将x转换为整数。 base指定x是字符串的基数。 |
| 2 | long(x [,base] ) 将x转换为长整数。 base指定x是字符串的基数。 |
| 3 | float(x) 将x转换为浮点数。 |
| 4 | complex(real [,imag]) 创建一个复数。 |
| 5 | str(x) 将对象x转换为字符串表示形式。 |
| 6 | repr(x) 将对象x转换为表达式字符串。 |
| 7 | eval(str) 计算字符串并返回一个对象。 |
| 8 | tuple(s) 将s转换为元组。 |
| 9 | list(s) 将s转换为列表。 |
| 10 | set(s) 将s转换为集合。 |
| 11 | dict(d) 创建一个字典。 d必须是(键,值)元组的序列。 |
| 12 | frozenset(s) 将s转换为冻结集。 |
| 13 | chr(x) 将整数转换为字符。 |
| 14 | unichr(x) 将整数转换为Unicode字符。 |
| 15 | ord(x) 将单个字符转换为其整数值。 |
| 16 | hex(x) 将整数转换为十六进制字符串。 |
| 17 | oct(x) 将整数转换为八进制字符串。 |
Python - Basic Operators
运算符是可以操纵操作数值的构造。
考虑表达式4 + 5 = 9.这里,4和5被称为操作数,+被称为运算符。
运算符的类型
Python语言支持以下类型的运算符。
- 算术运算符
- 比较(关系)运算符
- 分配运算符
- 逻辑运算符
- 按位运算符
- 成员运算符
- Identity运算符
让我们逐一了解所有运算符。
Python Arithmetic Operators
假设变量a保持10,变量b保持20,则 -
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| +加法 | 在运算符的任一侧添加值。 | a + b = 30 |
| - 减法 | 从左手操作数中减去右手操作数。 | a - b = -10 |
| *乘法 | 将运算符两侧的值相乘 | a * b = 200 |
| /除法 | 用左手操作数除左手操作数 | b/a = 2 |
| % Modulus | 用左手操作数除左手操作数并返回余数 | b%a = 0 |
| **指数 | 对运算符执行指数(幂)计算 | a ** b = 10到20的功率 |
| // | Floor Division - 操作数的除法,其结果是小数点后的数字被移除的商。 但是如果其中一个操作数是负数,则结果会被消除,即从零开始(向负无穷大)舍入 - | 9 // 2 = 4和9.0 // 2.0 = 4.0,-11 // 3 = -4,-11.0 // 3 = -4.0 |
Python Comparison Operators
这些运算符比较它们两侧的值并确定它们之间的关系。 它们也称为关系运算符。
假设变量a保持10,变量b保持20,则 -
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| == | 如果两个操作数的值相等,则条件成立。 | (a == b)不是真的。 |
| != | 如果两个操作数的值不相等,则条件成立。 | (a!= b)是真的。 |
| <> | 如果两个操作数的值不相等,则条件成立。 | (a <> b)是真的。 这类似于!=运算符。 |
| > | 如果左操作数的值大于右操作数的值,则条件变为真。 | (a> b)不是真的。 |
| < | 如果左操作数的值小于右操作数的值,则条件变为真。 | (a |
| >= | 如果左操作数的值大于或等于右操作数的值,则condition变为true。 | (a> = b)不是真的。 |
| <= | 如果左操作数的值小于或等于右操作数的值,则条件变为真。 | (a <= b)是真的。 |
Python Assignment Operators
假设变量a保持10,变量b保持20,则 -
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| = | 将右侧操作数的值分配给左侧操作数 | c = a + b将a + b的值分配给c |
| += Add AND | 它将右操作数添加到左操作数并将结果分配给左操作数 | c + = a等于c = c + a |
| -= Subtract AND | 它从左操作数中减去右操作数,并将结果赋给左操作数 | c - = a相当于c = c - a |
| *= Multiply AND | 它将右操作数与左操作数相乘,并将结果赋给左操作数 | c * = a等于c = c * a |
| /= Divide AND | 它将左操作数与右操作数分开,并将结果赋给左操作数 | c/= a等于c = c/ac/= a等于c = c/a |
| %= Modulus AND | 它使用两个操作数来获取模数,并将结果赋给左操作数 | c%= a等于c = c%a |
| **= Exponent AND | 对运算符执行指数(幂)计算并将值赋给左操作数 | c ** = a相当于c = c ** a |
| //= Floor Division | 它对运算符执行floor分割,并为左操作数赋值 | c // = a等于c = c // a |
Python Bitwise Operators
按位运算符处理位并执行逐位运算。 假设a = 60; 和b = 13; 现在采用二进制格式,它们如下 -
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a | b = 0011 1101
a ^ b = 0011 0001
~a = 1100 0011
Python语言支持以下Bitwise运算符
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| & Binary AND | 如果两个操作数中都存在,则运算符会将结果复制到结果中 | (a&b)(指0000 1100) |
| | Binary OR | 如果它存在于任一操作数中,它会复制一点。 | (a | b)= 61(表示0011 1101) |
| ^ Binary XOR | 如果它在一个操作数中设置但不在两个操作数中,则复制该位。 | (a ^ b)= 49(表示0011 0001) |
| ~ Binary Ones Complement | 它是一元的,具有'翻转'位的效果。 | (~a)= -61(由于带符号的二进制数,表示以2的补码形式的1100 0011。 |
| << Binary Left Shift | 左操作数值向左移动右操作数指定的位数。 | a << 2 = 240(表示1111 0000) |
| >> Binary Right Shift | 左操作数值向右移动右操作数指定的位数。 | a >> 2 = 15(表示0000 1111) |
Python Logical Operators
Python语言支持以下逻辑运算符。 假设变量a保持10,变量b保持20
[ 显示示例 ]
用于反转其操作数的逻辑状态。Python Membership Operators
Python的成员资格运算符测试序列中的成员资格,例如字符串,列表或元组。 有两个会员运算符,如下所述 -
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| in | 如果在指定序列中找到变量,则求值为true,否则求值为false。 | x在y中,如果x是序列y的成员,则在此处得到1。 |
| not in | 如果找不到指定序列中的变量,则求值为true,否则求值为false。 | x不在y中,如果x不是序列y的成员,则此处不会产生1。 |
Python Identity Operators
身份运算符比较两个对象的内存位置。 下面介绍了两个Identity运算符 -
[ 显示示例 ]
| 操作者 | 描述 | 例 |
|---|---|---|
| is | 如果运算符任一侧的变量指向同一对象,则求值为true,否则求值为false。 | x是y,如果id(x)等于id(y), is结果为1。 |
| is not | 如果运算符两侧的变量指向同一对象,则求值为false,否则为true。 | x不是y,如果id(x)不等于id(y), is not产生1。 |
Python Operators Precedence
下表列出了从最高优先级到最低优先级的所有运算符。
[ 显示示例 ]
| Sr.No. | 操作符和说明 |
|---|---|
| 1 | ** 指数(提升到权力) |
| 2 | ~ + - 补语,一元加号和减号(最后两个的方法名是+ @和 - @) |
| 3 | */% // 乘法,除法,模数和地面划分 |
| 4 | + - 加减 |
| 5 | 》》 《《 左右按位移位 |
| 6 | & 按位'与' |
| 7 | ^ | 按位排除“OR”和常规“OR” |
| 8 | 《= 《 》 》= 比较运算符 |
| 9 | 《》 == != 平等运算符 |
| 10 | = %= /= //= -= += *= **= 分配运算符 |
| 11 | is is not Identity运算符 |
| 12 | in not in 成员运算符 |
| 13 | not or and 逻辑运算符 |
Python - Decision Making
决策是预期在执行程序时发生的条件并指定根据条件采取的行动。
决策结构评估多个表达式,这些表达式产生TRUE或FALSE作为结果。 如果结果为TRUE,则需要确定要采取的操作以及要执行的语句,否则需要执行FALSE。
以下是大多数编程语言中常见决策结构的一般形式 -
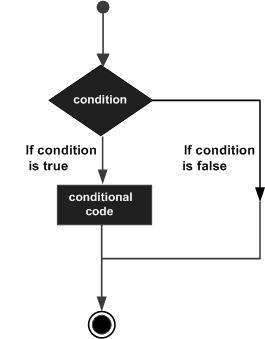
Python编程语言将任何non-zero和non-null值假定为TRUE,如果它zero或null ,则假定为FALSE值。
Python编程语言提供以下类型的决策制定语句。 单击以下链接以检查其详细信息。
| Sr.No. | 声明和说明 |
|---|---|
| 1 | if语句 if statement由布尔表达式后跟一个或多个语句组成。 |
| 2 | if ... else语句 if statement后面可以跟一个可选的else statement ,该else statement在布尔表达式为FALSE时执行。 |
| 3 | 嵌套if语句 您可以在另一个if或else if语句中使用if或else if语句。 |
让我们简要介绍一下每个决策 -
单一套房
如果if子句的套件只包含一行,则它可能与header语句位于同一行。
以下是one-line if子句的示例 -
#!/usr/bin/python
var = 100
if ( var == 100 ) : print "Value of expression is 100"
print "Good bye!"
执行上述代码时,会产生以下结果 -
Value of expression is 100
Good bye!
Python - Loops
通常,语句按顺序执行:首先执行函数中的第一个语句,然后执行第二个语句,依此类推。 可能存在需要多次执行代码块的情况。
编程语言提供各种控制结构,允许更复杂的执行路径。
循环语句允许我们多次执行语句或语句组。 下图说明了一个循环语句 -
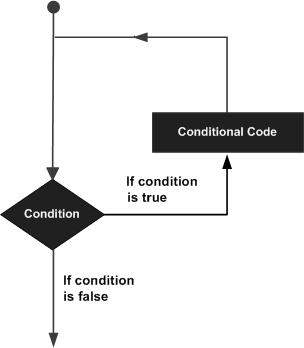
Python编程语言提供以下类型的循环来处理循环要求。
| Sr.No. | 循环类型和描述 |
|---|---|
| 1 | while 循环 在给定条件为TRUE时重复语句或语句组。 它在执行循环体之前测试条件。 |
| 2 | for循环 多次执行一系列语句,并缩写管理循环变量的代码。 |
| 3 | 嵌套循环 您可以在任何其他循环中使用一个或多个循环,而for或do..while循环。 |
循环控制语句 (Loop Control Statements)
循环控制语句将执行从其正常序列更改。 当执行离开作用域时,将销毁在该作用域中创建的所有自动对象。
Python支持以下控制语句。 单击以下链接以检查其详细信息。
让我们简要介绍一下循环控制语句
| Sr.No. | 控制声明和描述 |
|---|---|
| 1 | break statement 终止循环语句并将执行转移到循环后的语句。 |
| 2 | continue statement 导致循环跳过其身体的其余部分,并在重复之前立即重新测试其状态。 |
| 3 | pass statement 当语法需要语句但您不希望执行任何命令或代码时,将使用Python中的pass语句。 |
Python - Numbers
数字数据类型存储数值。 它们是不可变数据类型,意味着更改数字数据类型的值会导致新分配的对象。
为它们分配值时会创建数字对象。 例如 -
var1 = 1
var2 = 10
您还可以使用del语句删除对数字对象的引用。 del语句的语法是 -
del var1[,var2[,var3[....,varN]]]]
您可以使用del语句删除单个对象或多个对象。 例如 -
del var
del var_a, var_b
Python支持四种不同的数字类型 -
int (signed integers) - 它们通常被称为整数或整数,是正整数或负整数,没有小数点。
long (long integers ) - 也称为long,它们是无限大小的整数,写成整数,后跟大写或小写L.
float (floating point real values) - 也称为浮点数,它们表示实数,并用小数点写成整数和小数部分。 浮点数也可以是科学计数法,E或e表示10的幂(2.5e2 = 2.5 x 10 2 = 250)。
complex (complex numbers) - 具有a + bJ的形式,其中a和b是浮点数,J(或j)表示-1的平方根(这是一个虚数)。 数字的实部是a,虚部是b。 复杂的数字在Python编程中使用不多。
例子 (Examples)
以下是一些数字示例
| INT | 长 | 浮动 | 复杂 |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEL | 32.3+e18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7j |
Python允许您使用带有long的小写L,但建议您仅使用大写L来避免与数字1混淆.Python使用大写L显示长整数。
复数由一对有序的实浮点数组成,由a + bj表示,其中a是实部,b是复数的虚部。
数字类型转换
Python将包含混合类型的表达式内部的数字转换为常用类型以进行评估。 但有时,您需要明确地将一个数字从一种类型强制转换为另一种类型,以满足运算符或函数参数的要求。
输入int(x)将x转换为普通整数。
输入long(x)将x转换为长整数。
键入float(x)以将x转换为浮点数。
键入complex(x)将x转换为具有实部x和虚部0的复数。
键入complex(x, y)将x和y转换为具有实部x和虚部y的复数。 x和y是数字表达式
数学函数 (Mathematical Functions)
Python包括以下执行数学计算的函数。
| Sr.No. | 功能与退货(介绍) |
|---|---|
| 1 | abs(x) x的绝对值:x和零之间的(正)距离。 |
| 2 | ceil(x) x的上限:不小于x的最小整数 |
| 3 | cmp(x, y) 如果x |
| 4 | exp(x) x:e x的指数 |
| 5 | fabs(x) x的绝对值。 |
| 6 | floor(x) x的底限:不大于x的最大整数 |
| 7 | log(x) x的自然对数,x> 0 |
| 8 | log10(x) 对于x> 0,x的基数为10的对数。 |
| 9 | max(x1, x2,...) 最大的论点:最接近正无穷大的值 |
| 10 | min(x1, x2,...) 它的最小参数:最接近负无穷大的值 |
| 11 | modf(x) 两项元组中x的小数和整数部分。 两个部分都具有与x相同的符号。 整数部分作为float返回。 |
| 12 | pow(x, y) x ** y的值。 |
| 13 | 圆(x [,n]) x从小数点四舍五入到n位数。 Python从零开始作为平局:圆(0.5)为1.0,圆(-0.5)为-1.0。 |
| 14 | sqrt(x) x的平方根为x> 0 |
随机数函数 (Random Number Functions)
随机数用于游戏,模拟,测试,安全和隐私应用程序。 Python包括以下常用的函数。
| Sr.No. | 功能说明 |
|---|---|
| 1 | choice(seq) 列表,元组或字符串中的随机项。 |
| 2 | randrange([start,] stop [,step]) 从范围(开始,停止,步骤)中随机选择的元素 |
| 3 | random() 随机浮点r,使得0小于或等于r且r小于1 |
| 4 | seed([x]) 设置用于生成随机数的整数起始值。 在调用任何其他随机模块函数之前调用此函数。 返回None。 |
| 5 | shuffle(lst) 随机化列表中的项目。 返回None。 |
| 6 | uniform(x, y) 随机浮点r,使得x小于或等于r且r小于y |
三角函数 (Trigonometric Functions)
Python包括以下执行三角计算的函数。
| Sr.No. | 功能说明 |
|---|---|
| 1 | acos(x) 以弧度为单位返回x的反余弦值。 |
| 2 | asin(x) 以弧度为单位返回x的反正弦值。 |
| 3 | atan(x) 以弧度为单位返回x的反正切值。 |
| 4 | atan2(y, x) 以弧度为单位返回atan(y/x)。 |
| 5 | cos(x) 返回x弧度的余弦值。 |
| 6 | hypot(x, y) 返回欧几里德范数sqrt(x * x + y * y)。 |
| 7 | sin(x) 返回x弧度的正弦值。 |
| 8 | tan(x) 返回x弧度的正切值。 |
| 9 | degrees(x) 将角度x从弧度转换为度数。 |
| 10 | radians(x) 将角度x从度数转换为弧度。 |
数学常数
该模块还定义了两个数学常数 -
| Sr.No. | 常数和描述 |
|---|---|
| 1 | pi 数学常数pi。 |
| 2 | e 数学常数e。 |
Python - Strings
字符串是Python中最流行的类型之一。 我们可以通过在引号中包含字符来创建它们。 Python将单引号视为双引号。 创建字符串就像为变量赋值一样简单。 例如 -
var1 = 'Hello World!'
var2 = "Python Programming"
访问字符串中的值
Python不支持字符类型; 这些被视为长度为1的字符串,因此也被视为子字符串。
要访问子字符串,请使用方括号进行切片以及索引或索引以获取子字符串。 例如 -
#!/usr/bin/python
var1 = 'Hello World!'
var2 = "Python Programming"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]
执行上述代码时,会产生以下结果 -
var1[0]: H
var2[1:5]: ytho
更新字符串
您可以通过(重新)将变量分配给另一个字符串来“更新”现有字符串。 新值可以与其先前的值相关联,也可以与完全不同的字符串相关联。 例如 -
#!/usr/bin/python
var1 = 'Hello World!'
print "Updated String :- ", var1[:6] + 'Python'
执行上述代码时,会产生以下结果 -
Updated String :- Hello Python
逃脱角色
下表是可以使用反斜杠表示法表示的转义或不可打印字符的列表。
转义字符被解释; 在单引号和双引号字符串中。
| 反斜杠表示法 | 十六进制字符 | 描述 |
|---|---|---|
| \a | 0x07 | Bell or alert |
| \b | 0x08 | Backspace |
| \cx | Control-x | |
| \C-x | Control-x | |
| \e | 0x1b | Escape |
| \f | 0x0c | Formfeed |
| \M-\C-x | Meta-Control-x | |
| \n | 0x0a | Newline |
| \nnn | 八进制表示法,其中n在0.7范围内 | |
| \r | 0x0d | Carriage return |
| \s | 0x20 | Space |
| \t | 0x09 | Tab |
| \v | 0x0b | 垂直标签 |
| \x | Character x | |
| \xnn | 十六进制表示法,其中n在0.9,af或AF范围内 |
字符串特殊运算符
假设字符串变量a保存'Hello'而变量b保存'Python',然后 -
| 操作者 | 描述 | 例 |
|---|---|---|
| + | 连接 - 在运算符的任一侧添加值 | a + b将给出HelloPython |
| * | 重复 - 创建新字符串,连接同一字符串的多个副本 | a * 2会给-HelloHello |
| [] | 切片 - 给出指定索引中的字符 | a [1]会给e |
| [:] | 范围切片 - 给出给定范围内的字符 | a [1:4]会给出一个 |
| in | Membership - 如果给定字符串中存在字符,则返回true | H在一个意志中给1 |
| not in | Membership - 如果给定字符串中不存在某个字符,则返回true | M不在意志中给1 |
| r/R | 原始字符串 - 抑制Escape字符的实际含义。 原始字符串的语法与普通字符串的语法完全相同,原始字符串运算符除外,字母“r”在引号之前。 “r”可以是小写(r)或大写(R),并且必须紧接在第一个引号之前。 | print r'\ n'打印\ n并打印R'\ n'prints\n |
| % | 格式 - 执行字符串格式 | See at next section |
字符串格式化运算符
Python最酷的功能之一是字符串格式运算符%。 这个操作符对于字符串是唯一的,并且补充了具有C的printf()系列功能的包。 以下是一个简单的例子 -
#!/usr/bin/python
print "My name is %s and weight is %d kg!" % ('Zara', 21)
执行上述代码时,会产生以下结果 -
My name is Zara and weight is 21 kg!
以下是可与%一起使用的完整符号列表 -
| 格式符号 | 转变 |
|---|---|
| %c | character |
| %s | 格式化之前通过str()进行字符串转换 |
| %i | signed decimal integer |
| %d | signed decimal integer |
| %u | unsigned decimal integer |
| %o | 八进制整数 |
| %x | 十六进制整数(小写字母) |
| %X | 十六进制整数(大写字母) |
| %e | 指数表示法(小写'e') |
| %E | 指数表示法(使用UPPERcase'E') |
| %f | 浮点实数 |
| %g | %f和%e中的较短者 |
| %G | %f和%E中的较短者 |
下表列出了其他支持的符号和功能 -
| 符号 | 功能 |
|---|---|
| * | 参数指定宽度或精度 |
| - | 左对齐 |
| + | display the sign |
| <sp> | 在正数之前留一个空格 |
| # | 添加八进制前导零('0')或十六进制前导'0x'或'0X',具体取决于是使用'x'还是'X'。 |
| 0 | 从左边用零填充(而不是空格) |
| % | '%%'为您留下一个文字'%' |
| (var) | mapping variable (dictionary arguments) |
| m.n. | m是最小总宽度,n是小数点后显示的位数(如果应用) |
三重行情
Python的三重引号通过允许字符串跨越多行来实现,包括逐字NEWLINE,TAB和任何其他特殊字符。
三引号的语法由三个连续的single or double引号single or double引号组成。
#!/usr/bin/python
para_str = """this is a long string that is made up of
several lines and non-printable characters such as
TAB ( \t ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [ \n ], or just a NEWLINE within
the variable assignment will also show up.
"""
print para_str
执行上述代码时,会产生以下结果。 注意每个特殊字符是如何转换为其打印形式的,直到“up”之间字符串末尾的最后一个NEWLINE。 并关闭三重报价。 另请注意,NEWLINE会出现在行尾的显式回车符或其转义码(\ n) -
this is a long string that is made up of
several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up.
原始字符串根本不会将反斜杠视为特殊字符。 您放入原始字符串的每个字符都保持您编写的方式 -
#!/usr/bin/python
print 'C:\\nowhere'
执行上述代码时,会产生以下结果 -
C:\nowhere
现在让我们使用原始字符串。 我们将表达式放在r'expression' ,如下所示 -
#!/usr/bin/python
print r'C:\\nowhere'
执行上述代码时,会产生以下结果 -
C:\\nowhere
Unicode字符串
Python中的普通字符串在内部存储为8位ASCII,而Unicode字符串存储为16位Unicode。 这允许更多变化的字符集,包括来自世界上大多数语言的特殊字符。 我将限制我对Unicode字符串的处理如下 -
#!/usr/bin/python
print u'Hello, world!'
执行上述代码时,会产生以下结果 -
Hello, world!
如您所见,Unicode字符串使用前缀u,就像原始字符串使用前缀r一样。
内置字符串方法
Python包含以下内置方法来操作字符串 -
| Sr.No. | 带描述的方法 |
|---|---|
| 1 | capitalize() 大写首字母串 |
| 2 | center(width, fillchar) 返回以空格填充的字符串,其中原始字符串以总宽度列为中心。 |
| 3 | count(str,beg = 0,end = len(string)) 如果给出起始索引beg和结束索引结束,则计算str在字符串或字符串的子字符串中出现的次数。 |
| 4 | decode(encoding='UTF-8',errors='strict') 使用为编码注册的编解码器对字符串进行解码。 encoding默认为默认字符串编码。 |
| 5 | encode(encoding='UTF-8',errors='strict') 返回字符串的编码字符串版本; 出错时,默认是引发ValueError,除非使用'ignore'或'replace'给出错误。 |
| 6 | endswith(suffix, beg=0, end=len(string)) 确定string的字符串或子字符串(如果给出起始索引beg和结束索引结束)是否以后缀结尾; 如果是,则返回true,否则返回false。 |
| 7 | expandtabs(tabsize=8) 将字符串中的制表符扩展为多个空格; 如果未提供tabsize,则每个选项卡默认为8个空格。 |
| 8 | find(str,beg = 0 end = len(string)) 如果找到起始索引beg和结束索引结束,则确定str是出现在字符串中还是字符串的子字符串中,如果找到则返回索引,否则返回-1。 |
| 9 | index(str, beg=0, end=len(string)) 与find()相同,但如果未找到str则引发异常。 |
| 10 | isalnum() 如果string至少包含1个字符且所有字符都是字母数字,则返回true,否则返回false。 |
| 11 | isalpha() 如果string至少包含1个字符且所有字符都是字母,则返回true,否则返回false。 |
| 12 | isdigit() 如果string只包含数字,则返回true,否则返回false。 |
| 13 | islower() 如果string具有至少1个套管字符且所有套管字符均为小写,则返回true,否则返回false。 |
| 14 | isnumeric() 如果unicode字符串仅包含数字字符,则返回true,否则返回false。 |
| 15 | isspace() 如果string只包含空格字符,则返回true,否则返回false。 |
| 16 | istitle() 如果string被正确“标记”,则返回true,否则返回false。 |
| 17 | isupper() 如果string至少有一个cased字符且所有cased字符都是大写,则返回true,否则返回false。 |
| 18 | join(seq) 将序列seq中元素的字符串表示形式(连接)合并为一个字符串,并带有分隔符字符串。 |
| 19 | len(string) 返回字符串的长度 |
| 20 | ljust(width[, fillchar]) 返回一个空格填充的字符串,其原始字符串左对齐为总宽度列。 |
| 21 | lower() 将字符串中的所有大写字母转换为小写。 |
| 22 | lstrip() 删除字符串中的所有前导空格。 |
| 23 | maketrans() 返回要在translate函数中使用的转换表。 |
| 24 | max(str) 返回字符串str中的最大字母字符。 |
| 25 | min(str) 返回字符串str中的min字母字符。 |
| 26 | replace(old, new [, max]) 如果给定最大值,则将所有出现的旧字符串替换为新的或最多出现的最大值。 |
| 27 | rfind(str, beg=0,end=len(string)) 与find()相同,但在字符串中向后搜索。 |
| 28 | rindex(str,beg = 0,end = len(string)) 与index()相同,但在字符串中向后搜索。 |
| 29 | rjust(width,[, fillchar]) 返回一个以空格填充的字符串,其原始字符串右对齐为总宽度列。 |
| 30 | rstrip() 删除字符串的所有尾随空格。 |
| 31 | split(str="", num=string.count(str)) 根据分隔符str(如果未提供空格)拆分字符串并返回子字符串列表; 如果给出,最多分成多个子串。 |
| 32 | splitlines(num = string.count('\ n')) 在所有(或num)NEWLINE处拆分字符串,并返回已删除NEWLINE的每行的列表。 |
| 33 | startswith(str, beg=0,end=len(string)) 确定string的字符串或子字符串(如果给出起始索引beg和结束索引结束)是否以substring str开头; 如果是,则返回true,否则返回false。 |
| 34 | strip([chars]) 在字符串上执行lstrip()和rstrip()。 |
| 35 | swapcase() 反转字符串中所有字母的大小写。 |
| 36 | title() 返回字符串的“titlecased”版本,即所有单词都以大写字母开头,其余字母以小写字母开头。 |
| 37 | translate(table, deletechars="") 根据转换表str(256个字符)转换字符串,删除del字符串中的字符串。 |
| 38 | upper() 将字符串中的小写字母转换为大写。 |
| 39 | zfill (width) 返回用零填充的原始字符串到总宽度字符; 对于数字,zfill()保留给定的任何符号(少于零)。 |
| 40 | isdecimal() 如果unicode字符串仅包含十进制字符,则返回true,否则返回false。 |
Python - Lists
Python中最基本的数据结构是sequence 。 序列的每个元素都被赋予一个数字 - 它的位置或索引。 第一个索引为零,第二个索引为1,依此类推。
Python有六种内置类型的序列,但最常见的是列表和元组,我们将在本教程中看到。
您可以对所有序列类型执行某些操作。 这些操作包括索引,切片,添加,乘法和检查成员资格。 此外,Python还具有内置函数,用于查找序列的长度以及查找其最大和最小元素。
Python Lists
该列表是Python中最通用的数据类型,可以写为方括号之间的逗号分隔值(项)列表。 关于列表的重要事项是列表中的项不必是相同类型。
创建列表就像在方括号之间放置不同的逗号分隔值一样简单。 例如 -
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"]
与字符串索引类似,列表索引从0开始,列表可以切片,连接等等。
访问列表中的值
要访问列表中的值,请使用方括号进行切片以及索引或索引以获取该索引处可用的值。 例如 -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5, 6, 7 ];
print "list1[0]: ", list1[0]
print "list2[1:5]: ", list2[1:5]
执行上述代码时,会产生以下结果 -
list1[0]: physics
list2[1:5]: [2, 3, 4, 5]
更新列表
您可以通过在赋值运算符的左侧给出切片来更新列表的单个或多个元素,并且可以使用append()方法添加到列表中的元素。 例如 -
#!/usr/bin/python
list = ['physics', 'chemistry', 1997, 2000];
print "Value available at index 2 : "
print list[2]
list[2] = 2001;
print "New value available at index 2 : "
print list[2]
Note - append()方法将在后续章节中讨论。
执行上述代码时,会产生以下结果 -
Value available at index 2 :
1997
New value available at index 2 :
2001
删除列表元素
要删除列表元素,如果您确切知道要删除的元素,则可以使用del语句,如果您不知道,则可以使用remove()方法。 例如 -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
print list1
del list1[2];
print "After deleting value at index 2 : "
print list1
执行上面的代码时,会产生以下结果 -
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 :
['physics', 'chemistry', 2000]
Note - remove()方法将在后续章节中讨论。
基本清单操作
列表对+和*运算符的响应非常类似于字符串; 它们也意味着连接和重复,除了结果是新列表,而不是字符串。
实际上,列表响应了我们在前一章中对字符串使用的所有通用序列操作。
| Python表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | Length |
| [1,2,3] + [4,5,6] | [1, 2, 3, 4, 5, 6] | Concatenation |
| ['嗨!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | Repetition |
| [1,2,3]中的3 | True | Membership |
| 对于[1,2,3]中的x:print x, | 1 2 3 | Iteration |
索引,切片和矩阵
因为列表是序列,所以索引和切片对列表的工作方式与对字符串的工作方式相同。
假设以下输入 -
L = ['spam', 'Spam', 'SPAM!']
| Python表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | SPAM! | Offsets start at zero |
| L[-2] | Spam | 否定:从右边算起 |
| L[1:] | ['Spam', 'SPAM!'] | Slicing fetches sections |
内置列表功能和方法
Python包括以下列表函数 -
| Sr.No. | 具有描述的功能 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素。 |
| 2 | len(list) 给出列表的总长度。 |
| 3 | max(list) 从列表中返回具有最大值的项目。 |
| 4 | min(list) 使用最小值返回列表中的项目。 |
| 5 | list(seq) 将元组转换为列表。 |
Python包括以下列表方法
| Sr.No. | 带描述的方法 |
|---|---|
| 1 | list.append(obj) 将对象obj追加到列表中 |
| 2 | list.count(obj) 返回obj在列表中出现的次数 |
| 3 | list.extend(seq) 将seq的内容追加到列表中 |
| 4 | list.index(obj) 返回obj出现的列表中的最低索引 |
| 5 | list.insert(index, obj) 在offset索引处将对象obj插入到列表中 |
| 6 | list.pop(obj=list[-1]) 从列表中删除并返回最后一个对象或obj |
| 7 | list.remove(obj) 从列表中删除对象obj |
| 8 | list.reverse() 反转列表对象 |
| 9 | list.sort([func]) 对列表对象进行排序,如果给出则使用compare func |
Python - Tuples
元组是一系列不可变的Python对象。 元组是序列,就像列表一样。 元组和列表之间的区别是,与列表和元组不同,元组不能更改使用括号,而列表使用方括号。
创建元组就像放置不同的逗号分隔值一样简单。 您也可以选择将这些以逗号分隔的值放在括号中。 例如 -
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";
空元组写成两个括号不包含任何内容 -
tup1 = ();
要编写包含单个值的元组,您必须包含逗号,即使只有一个值 -
tup1 = (50,);
与字符串索引一样,元组索引从0开始,它们可以被切片,连接等等。
访问元组中的值
要访问元组中的值,请使用方括号进行切片以及索引或索引以获取该索引处可用的值。 例如 -
#!/usr/bin/python
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5, 6, 7 );
print "tup1[0]: ", tup1[0];
print "tup2[1:5]: ", tup2[1:5];
执行上述代码时,会产生以下结果 -
tup1[0]: physics
tup2[1:5]: [2, 3, 4, 5]
更新元组
元组是不可变的,这意味着您无法更新或更改元组元素的值。 您可以使用现有元组的一部分来创建新元组,如以下示例所示 -
#!/usr/bin/python
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# Following action is not valid for tuples
# tup1[0] = 100;
# So let's create a new tuple as follows
tup3 = tup1 + tup2;
print tup3;
执行上述代码时,会产生以下结果 -
(12, 34.56, 'abc', 'xyz')
删除元组元素
无法删除单个元组元素。 当然,将另一个元组放在一起并丢弃不需要的元素也没有错。
要显式删除整个元组,只需使用del语句。 例如 -
#!/usr/bin/python
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
print "After deleting tup : ";
print tup;
这产生以下结果。 注意引发异常,这是因为在del tup tup之后元组不再存在 -
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup;
NameError: name 'tup' is not defined
基本元组操作
元组响应+和*运算符很像字符串; 它们也意味着连接和重复,除了结果是一个新的元组,而不是一个字符串。
实际上,元组响应了我们在前一章中对字符串使用的所有通用序列操作 -
| Python表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | Length |
| (1,2,3)+(4,5,6) | (1, 2, 3, 4, 5, 6) | Concatenation |
| ('嗨!',)* 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | Repetition |
| 3英寸(1,2,3) | True | Membership |
| for x in(1,2,3):print x, | 1 2 3 | Iteration |
索引,切片和矩阵
因为元组是序列,所以索引和切片对于元组的工作方式与对字符串的工作方式相同。 假设以下输入 -
L = ('spam', 'Spam', 'SPAM!')
| Python表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | Offsets start at zero |
| L[-2] | 'Spam' | 否定:从右边算起 |
| L[1:] | ['Spam', 'SPAM!'] | Slicing fetches sections |
没有封闭的分隔符
任何一组多个对象,以逗号分隔,没有标识符号,即列表括号,元组括号等,默认为元组,如这些简短示例所示 -
#!/usr/bin/python
print 'abc', -4.24e93, 18+6.6j, 'xyz';
x, y = 1, 2;
print "Value of x , y : ", x,y;
执行上述代码时,会产生以下结果 -
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2
内置的Tuple函数 (Built-in Tuple Functions)
Python包含以下元组函数 -
| Sr.No. | 具有描述的功能 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组的元素。 |
| 2 | len(tuple) 给出元组的总长度。 |
| 3 | max(tuple) 返回具有最大值的元组中的项。 |
| 4 | min(tuple) 返回具有最小值的元组中的项。 |
| 5 | tuple(seq) 将列表转换为元组。 |
Python - Dictionary
每个键都通过冒号(:)与其值分隔,项目用逗号分隔,整个内容用大括号括起来。 没有任何项目的空字典只用两个花括号写成,如下所示:{}。
键在字典中是唯一的,而值可能不是。 字典的值可以是任何类型,但键必须是不可变的数据类型,如字符串,数字或元组。
访问字典中的值
要访问字典元素,可以使用熟悉的方括号和键来获取其值。 以下是一个简单的例子 -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Name']: ", dict['Name']
print "dict['Age']: ", dict['Age']
执行上述代码时,会产生以下结果 -
dict['Name']: Zara
dict['Age']: 7
如果我们尝试使用不属于字典的键访问数据项,我们会收到如下错误 -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Alice']: ", dict['Alice']
执行上述代码时,会产生以下结果 -
dict['Alice']:
Traceback (most recent call last):
File "test.py", line 4, in <module>
print "dict['Alice']: ", dict['Alice'];
KeyError: 'Alice'
更新字典
您可以通过添加新条目或键值对来更新字典,修改现有条目或删除现有条目,如下面的简单示例所示 -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']
执行上述代码时,会产生以下结果 -
dict['Age']: 8
dict['School']: DPS School
删除字典元素
您可以删除单个词典元素或清除词典的全部内容。 您也可以在一次操作中删除整个字典。
要显式删除整个字典,只需使用del语句。 以下是一个简单的例子 -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name']; # remove entry with key 'Name'
dict.clear(); # remove all entries in dict
del dict ; # delete entire dictionary
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']
这产生以下结果。 请注意,引发异常是因为在del dict字典不再存在之后 -
dict['Age']:
Traceback (most recent call last):
File "test.py", line 8, in <module>
print "dict['Age']: ", dict['Age'];
TypeError: 'type' object is unsubscriptable
Note - del()方法将在后续章节中讨论。
字典键的属性
字典值没有限制。 它们可以是任意Python对象,可以是标准对象,也可以是用户定义的对象。 但是,密钥也不是这样。
关于字典键有两点需要记住 -
(a)每个密钥不允许多个条目。 这意味着不允许重复键。 在分配期间遇到重复键时,最后一个分配获胜。 例如 -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}
print "dict['Name']: ", dict['Name']
执行上述代码时,会产生以下结果 -
dict['Name']: Manni
(b)钥匙必须是不变的。 这意味着您可以使用字符串,数字或元组作为字典键,但不允许使用['key']之类的字符串。 以下是一个简单的例子 -
#!/usr/bin/python
dict = {['Name']: 'Zara', 'Age': 7}
print "dict['Name']: ", dict['Name']
执行上述代码时,会产生以下结果 -
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Zara', 'Age': 7};
TypeError: unhashable type: 'list'
内置字典功能和方法
Python包含以下字典函数 -
| Sr.No. | 具有描述的功能 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个词的元素。 |
| 2 | len(dict) 给出字典的总长度。 这将等于字典中的项目数。 |
| 3 | str(dict) 生成字典的可打印字符串表示 |
| 4 | type(variable) 返回传递的变量的类型。 如果传递的变量是字典,那么它将返回字典类型。 |
Python包括以下字典方法 -
| Sr.No. | 带描述的方法 |
|---|---|
| 1 | dict.clear() 删除字典dict所有元素 |
| 2 | dict.copy() 返回字典dict的浅表副本 |
| 3 | dict.fromkeys() 使用seq中的键创建一个新字典,并将值set为value 。 |
| 4 | dict.get(key, default=None) 对于key键,如果键不在字典中,则返回值或默认值 |
| 5 | dict.has_key(key) 如果字典dict键,则返回true ,否则返回false |
| 6 | dict.items() 返回dict (键,值)元组对的列表 |
| 7 | dict.keys() 返回字典dict键的列表 |
| 8 | dict.setdefault(key, default=None) 与get()类似,但如果key不在dict中,则会设置dict [key] = default |
| 9 | dict.update(dict2) 将字典dict2的键值对添加到dict |
| 10 | dict.values() 返回字典dict的值列表 |
Python - Date & Time
Python程序可以通过多种方式处理日期和时间。 日期格式之间的转换是计算机的常见工作。 Python的时间和日历模块有助于跟踪日期和时间。
什么是Tick?
时间间隔是以秒为单位的浮点数。 特定的时间瞬间以1970年1月1日凌晨12:00(纪元)的秒数表示。
Python中有一个流行的time模块,它提供了处理时间和表示之间转换的功能。 函数time.time()以1970年1月1日凌晨12:00(纪元)为单位返回当前系统时间。
例子 (Example)
#!/usr/bin/python
import time; # This is required to include time module.
ticks = time.time()
print "Number of ticks since 12:00am, January 1, 1970:", ticks
这会产生如下结果 -
Number of ticks since 12:00am, January 1, 1970: 7186862.73399
使用刻度线很容易进行日期算术。 但是,时期之前的日期无法以此形式表示。 远期未来的日期也无法用这种方式表示 - 截止点是2038年UNIX和Windows的某个时间点。
什么是TimeTuple?
许多Python的时间函数将时间作为9个数字的元组处理,如下所示 -
| 指数 | 领域 | 值 |
|---|---|---|
| 0 | 4-digit year | 2008 |
| 1 | Month | 1 to 12 |
| 2 | Day | 1 to 31 |
| 3 | Hour | 0到23 |
| 4 | Minute | 0到59 |
| 5 | Second | 0到61(60或61是闰秒) |
| 6 | 星期几 | 0到6(0是星期一) |
| 7 | Day of year | 1至366(朱利安日) |
| 8 | Daylight savings | -1,0,1,-1表示库确定DST |
上面的元组等同于struct_time结构。 该结构具有以下属性 -
| 指数 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 to 12 |
| 2 | tm_mday | 1 to 31 |
| 3 | tm_hour | 0到23 |
| 4 | tm_min | 0到59 |
| 5 | tm_sec | 0到61(60或61是闰秒) |
| 6 | tm_wday | 0到6(0是星期一) |
| 7 | tm_yday | 1至366(朱利安日) |
| 8 | tm_isdst | -1,0,1,-1表示库确定DST |
获取当前时间
要将时间点从从seconds since the epoch浮点值开始的seconds since the epoch转换为时间元组,请将浮点值传递给函数(例如,本地时间),该函数返回所有九个项有效的时间元组。
#!/usr/bin/python
import time;
localtime = time.localtime(time.time())
print "Local current time :", localtime
这将产生以下结果,可以用任何其他可呈现的形式格式化 -
Local current time : time.struct_time(tm_year=2013, tm_mon=7,
tm_mday=17, tm_hour=21, tm_min=26, tm_sec=3, tm_wday=2, tm_yday=198, tm_isdst=0)
获得格式化时间
您可以根据您的要求随时格式化,但是以可读格式获取时间的简单方法是asctime() -
#!/usr/bin/python
import time;
localtime = time.asctime( time.localtime(time.time()) )
print "Local current time :", localtime
这会产生以下结果 -
Local current time : Tue Jan 13 10:17:09 2009
获得一个月的日历
日历模块提供了多种方法来播放年度和月度日历。 在这里,我们打印给定月份的日历(2008年1月) -
#!/usr/bin/python
import calendar
cal = calendar.month(2008, 1)
print "Here is the calendar:"
print cal
这会产生以下结果 -
Here is the calendar:
January 2008
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31
time模块
Python中有一个流行的time模块,它提供了处理时间和表示之间转换的功能。 以下是所有可用方法的列表 -
| Sr.No. | 具有描述的功能 |
|---|---|
| 1 | time.altzone 本地DST时区的偏移量,以UTC为单位的秒数(如果已定义)。 如果当地DST时区在UTC以东(如在西欧,包括英国),这是否定的。 只有在日光非零时才使用此功能。 |
| 2 | time.asctime([tupletime]) 接受时间元组并返回一个可读的24个字符的字符串,例如'Tue Dec 11 18:07:14 2008'。 |
| 3 | time.clock() 以浮点秒数形式返回当前CPU时间。 为了测量不同方法的计算成本,time.clock的值比time.time()更有用。 |
| 4 | time.ctime([secs]) 像asctime(localtime(secs))和没有参数就像asctime() |
| 5 | time.gmtime([secs]) 接受自纪元以来以秒为单位表示的瞬间,并返回UTC时间的时间元组t。 注意:t.tm_isdst始终为0 |
| 6 | time.localtime([secs]) 接受自纪元以来以秒为单位表示的瞬间,并返回具有本地时间的时间元组t(t.tm_isdst为0或1,具体取决于DST是否适用于本地规则的即时秒)。 |
| 7 | time.mktime(tupletime) 接受以本地时间表示为时间元组的瞬间,并返回浮点值,其中以从纪元开始的秒数表示。 |
| 8 | time.sleep(secs) 暂停调用线程秒秒。 |
| 9 | time.strftime(fmt[,tupletime]) 接受以本地时间表示为时间元组的瞬间,并返回表示字符串fmt指定的瞬间的字符串。 |
| 10 | time.strptime(str,fmt ='%a%b%d%H:%M:%S%Y') 根据格式字符串fmt解析str并以时间元组格式返回瞬间。 |
| 11 | time.time() 返回当前时刻,即自纪元以来的浮点秒数。 |
| 12 | time.tzset() 重置库例程使用的时间转换规则。 环境变量TZ指定了如何完成此操作。 |
让我们简要介绍一下这些功能 -
时间模块有以下两个重要属性 -
| Sr.No. | 带描述的属性 |
|---|---|
| 1 | time.timezone 属性time.timezone是UTC的本地时区(没有DST)的偏移量(在美洲> 0;在欧洲,亚洲,非洲的大部分地区<= 0)。 |
| 2 | time.tzname 属性time.tzname是一对依赖于语言环境的字符串,它们分别是没有和有DST的本地时区的名称。 |
calendar模块
日历模块提供与日历相关的功能,包括打印给定月份或年份的文本日历的功能。
默认情况下,日历将星期一视为一周的第一天,将星期日视为最后一天。 要更改此设置,请调用calendar.setfirstweekday()函数。
以下是calendar模块可用的功能列表 -
| Sr.No. | 具有描述的功能 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串,其中包含年份的日历,格式化为由c空格分隔的三列。 w是每个日期的字符宽度; 每行的长度为21 * w + 18 + 2 * c。 l是每周的行数。 |
| 2 | calendar.firstweekday( ) 返回每周开始的工作日的当前设置。 默认情况下,首次导入日历时,此值为0,表示星期一。 |
| 3 | calendar.isleap(year) 如果年份是闰年,则返回True; 否则,错误。 |
| 4 | calendar.leapdays(y1,y2) 返回范围(y1,y2)内年份中的闰天总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串,其中包含一年中月份的日历,每周一行以及两个标题行。 w是每个日期的字符宽度; 每行的长度为7 * w + 6。 l是每周的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回整数列表的列表。 每个子列表表示一周。 一年中月外的天数设为0; 这个月内的日期设置为他们的日期,1日及以上。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。 第一个是年中第一天的工作日代码; 第二个是该月的天数。 工作日代码为0(星期一)至6(星期日); 月数是1到12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 喜欢打印calendar.calendar(年,w,l,c)。 |
| 9 | calendar.prmonth(year,month,w=2,l=1) 像打印calendar.month(年,月,w,l)。 |
| 10 | calendar.setfirstweekday(weekday) 将每周的第一天设置为工作日代码工作日。 工作日代码为0(星期一)至6(星期日)。 |
| 11 | calendar.timegm(tupletime) time.gmtime的倒数:接受时间元组形式的时间瞬间,并返回与纪元以来的浮点秒数相同的瞬间。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的工作日代码。 工作日代码为0(星期一)至6(星期日); 月数是1(1月)到12(12月)。 |
Other Modules & 函数
如果您有兴趣,那么您可以在这里找到其他重要的模块和函数列表,以便在Python中使用日期和时间 -
Python - Functions
函数是有组织的可重用代码块,用于执行单个相关操作。 函数为您的应用程序提供了更好的模块化,并且可以高度重用代码。
如您所知,Python为您提供了许多内置函数,如print()等,但您也可以创建自己的函数。 这些函数称为user-defined functions.
定义一个函数 (Defining a Function)
您可以定义函数以提供所需的功能。 以下是在Python中定义函数的简单规则。
功能块以关键字def开头,后跟函数名称和括号(())。
任何输入参数或参数都应放在这些括号内。 您还可以在这些括号内定义参数。
函数的第一个语句可以是可选语句 - 函数或docstring 。
每个函数中的代码块以冒号(:)开头并缩进。
语句return [expression]退出函数,可选地将表达式传递给调用者。 不带参数的return语句与return None相同。
语法 (Syntax)
def functionname( parameters ):
"function_docstring"
function_suite
return [expression]
默认情况下,参数具有位置行为,您需要按照定义的顺序通知它们。
例子 (Example)
以下函数将字符串作为输入参数并将其打印在标准屏幕上。
def printme( str ):
"This prints a passed string into this function"
print str
return
调用一个函数 (Calling a Function)
定义函数只会给它一个名称,指定要包含在函数中的参数并构造代码块。
一旦函数的基本结构最终确定,您可以通过从另一个函数调用它或直接从Python提示符执行它。 以下是调用printme()函数的示例 -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme("I'm first call to user defined function!")
printme("Again second call to the same function")
执行上述代码时,会产生以下结果 -
I'm first call to user defined function!
Again second call to the same function
通过引用vs值传递
Python语言中的所有参数(参数)都通过引用传递。 这意味着如果您更改参数在函数中引用的内容,则更改也会反映在调用函数中。 例如 -
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist.append([1,2,3,4]);
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylist
在这里,我们维护传递对象的引用并在同一对象中追加值。 因此,这将产生以下结果 -
Values inside the function: [10, 20, 30, [1, 2, 3, 4]]
Values outside the function: [10, 20, 30, [1, 2, 3, 4]]
还有一个例子,其中参数通过引用传递,并且引用被覆盖在被调用函数内。
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist = [1,2,3,4]; # This would assig new reference in mylist
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylist
参数mylist是函数changeme的本地。 更改函数中的mylist不会影响mylist 。 该功能完成任何事情,最后这将产生以下结果 -
Values inside the function: [1, 2, 3, 4]
Values outside the function: [10, 20, 30]
函数参数(Function Arguments)
您可以使用以下类型的正式参数来调用函数 -
- 必需的参数
- 关键字参数
- 默认参数
- 可变长度参数
必需的参数
必需参数是以正确的位置顺序传递给函数的参数。 这里,函数调用中的参数个数应与函数定义完全匹配。
要调用函数printme() ,你肯定需要传递一个参数,否则它会产生如下语法错误 -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme()
执行上述代码时,会产生以下结果 -
Traceback (most recent call last):
File "test.py", line 11, in <module>
printme();
TypeError: printme() takes exactly 1 argument (0 given)
关键字参数
关键字参数与函数调用有关。 在函数调用中使用关键字参数时,调用者通过参数名称标识参数。
这允许您跳过参数或将它们排除在外,因为Python解释器能够使用提供的关键字将值与参数匹配。 您还可以通过以下方式对printme()函数进行关键字调用 -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme( str = "My string")
执行上述代码时,会产生以下结果 -
My string
以下示例给出了更清晰的图片。 请注意,参数的顺序无关紧要。
#!/usr/bin/python
# Function definition is here
def printinfo( name, age ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )
执行上述代码时,会产生以下结果 -
Name: miki
Age 50
默认参数
默认参数是一个参数,如果在该参数的函数调用中未提供值,则该参数采用默认值。 以下示例给出了默认参数的概念,如果未传递,则打印默认年龄 -
#!/usr/bin/python
# Function definition is here
def printinfo( name, age = 35 ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )
printinfo( name="miki" )
执行上述代码时,会产生以下结果 -
Name: miki
Age 50
Name: miki
Age 35
Variable-length arguments
在定义函数时,您可能需要处理比您指定的参数更多的参数。 这些参数称为variable-length参数,并且在函数定义中未命名,与required和default参数不同。
具有非关键字变量参数的函数的语法是这样的 -
def functionname([formal_args,] *var_args_tuple ):
"function_docstring"
function_suite
return [expression]
星号(*)放在保存所有非关键字变量参数值的变量名之前。 如果在函数调用期间未指定其他参数,则此元组将保持为空。 以下是一个简单的例子 -
#!/usr/bin/python
# Function definition is here
def printinfo( arg1, *vartuple ):
"This prints a variable passed arguments"
print "Output is: "
print arg1
for var in vartuple:
print var
return;
# Now you can call printinfo function
printinfo( 10 )
printinfo( 70, 60, 50 )
执行上述代码时,会产生以下结果 -
Output is:
10
Output is:
70
60
50
Anonymous函数
这些函数称为匿名函数,因为它们不是使用def关键字以标准方式声明的。 您可以使用lambda关键字来创建小型匿名函数。
Lambda表单可以使用任意数量的参数,但只能以表达式的形式返回一个值。 它们不能包含命令或多个表达式。
匿名函数不能直接调用print,因为lambda需要表达式
Lambda函数具有自己的本地名称空间,并且不能访问参数列表中的变量以及全局名称空间中的变量。
虽然看起来lambda是函数的单行版本,但它们并不等同于C或C ++中的内联语句,其目的是在调用期间为了性能原因传递函数堆栈分配。
语法 (Syntax)
lambda函数的语法只包含一个语句,如下所示 -
lambda [arg1 [,arg2,.....argn]]:expression
下面的例子展示了lambda形式的函数是如何工作的 -
#!/usr/bin/python
# Function definition is here
sum = lambda arg1, arg2: arg1 + arg2;
# Now you can call sum as a function
print "Value of total : ", sum( 10, 20 )
print "Value of total : ", sum( 20, 20 )
执行上述代码时,会产生以下结果 -
Value of total : 30
Value of total : 40
return声明
语句return [expression]退出函数,可选地将表达式传递给调用者。 不带参数的return语句与return None相同。
以上所有示例均未返回任何值。 您可以从函数返回值,如下所示 -
#!/usr/bin/python
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2
print "Inside the function : ", total
return total;
# Now you can call sum function
total = sum( 10, 20 );
print "Outside the function : ", total
执行上述代码时,会产生以下结果 -
Inside the function : 30
Outside the function : 30
变量范围
程序中的所有变量可能无法在该程序中的所有位置访问。 这取决于您声明变量的位置。
变量的范围确定程序中可以访问特定标识符的部分。 Python中有两个基本的变量范围 -
- 全局变量
- 局部变量
全局与局部变量
在函数体内定义的变量具有局部范围,而在外部定义的变量具有全局范围。
这意味着局部变量只能在声明它们的函数内部访问,而全局变量可以通过所有函数在整个程序体中访问。 调用函数时,在其中声明的变量将进入范围。 以下是一个简单的例子 -
#!/usr/bin/python
total = 0; # This is global variable.
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2; # Here total is local variable.
print "Inside the function local total : ", total
return total;
# Now you can call sum function
sum( 10, 20 );
print "Outside the function global total : ", total
执行上述代码时,会产生以下结果 -
Inside the function local total : 30
Outside the function global total : 0
Python - Modules
模块允许您逻辑地组织Python代码。 将相关代码分组到模块中使代码更易于理解和使用。 模块是一个Python对象,具有可以绑定和引用的任意命名属性。
简单地说,模块是由Python代码组成的文件。 模块可以定义函数,类和变量。 模块还可以包括可运行代码。
例子 (Example)
名为aname的模块的Python代码通常位于名为aname.py的文件中。 这是一个简单模块support.py的示例
def print_func( par ):
print "Hello : ", par
return
import声明
您可以通过在其他Python源文件中执行import语句,将任何Python源文件用作模块。 import具有以下语法 -
import module1[, module2[,... moduleN]
当解释器遇到import语句时,如果模块存在于搜索路径中,它将导入模块。 搜索路径是解释程序在导入模块之前搜索的目录列表。 例如,要导入模块support.py,您需要将以下命令放在脚本的顶部 -
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Zara")
执行上述代码时,会产生以下结果 -
Hello : Zara
无论导入的次数如何,模块仅加载一次。 如果发生多次导入,这可以防止模块执行一次又一次地发生。
from...import语句
Python的from语句允许您将模块中的特定属性导入当前命名空间。 from...import具有以下语法 -
from modname import name1[, name2[, ... nameN]]
例如,要从模块fib导入函数fibonacci,请使用以下语句 -
from fib import fibonacci
此语句不会将整个模块fib导入当前名称空间; 它只是将模块fib中的项目fibonacci引入导入模块的全局符号表中。
from...import *语句
也可以使用以下import语句将模块中的所有名称导入当前名称空间 -
from modname import *
这提供了一种将模块中的所有项目导入当前名称空间的简便方法; 但是,这个陈述应该谨慎使用。
定位模块
导入模块时,Python解释器按以下顺序搜索模块 -
当前目录。
如果找不到该模块,Python随后会搜索shell变量PYTHONPATH中的每个目录。
如果所有其他方法都失败,Python会检查默认路径。 在UNIX上,此默认路径通常为/ usr/local/lib/python /。
模块搜索路径作为sys.path变量存储在系统模块sys中。 sys.path变量包含当前目录PYTHONPATH和依赖于安装的缺省值。
PYTHONPATH变量
PYTHONPATH是一个环境变量,由一系列目录组成。 PYTHONPATH的语法与shell变量PATH的语法相同。
这是Windows系统中典型的PYTHONPATH -
set PYTHONPATH = c:\python20\lib;
这是来自UNIX系统的典型PYTHONPATH -
set PYTHONPATH = /usr/local/lib/python
命名空间和范围
变量是映射到对象的名称(标识符)。 namespace是变量名称(键)及其对应的对象(值)的字典。
Python语句可以访问local namespace和global namespace local namespace中的变量。 如果局部变量和全局变量具有相同的名称,则局部变量将影响全局变量。
每个函数都有自己的本地名称空间。 类方法遵循与普通函数相同的范围规则。
Python对变量是局部变量还是全局变量进行了有根据的猜测。 它假定在函数中赋值的任何变量都是本地的。
因此,要为函数中的全局变量赋值,必须首先使用全局语句。
语句global VarName告诉Python VarName是一个全局变量。 Python停止在本地命名空间中搜索变量。
例如,我们在全局命名空间中定义变量Money 。 在Money函数中,我们为Money分配一个值,因此Python将Money视为局部变量。 但是,我们在设置之前访问了局部变量Money的值,因此结果是UnboundLocalError。 取消注释全局语句可以解决问题。
#!/usr/bin/python
Money = 2000
def AddMoney():
# Uncomment the following line to fix the code:
# global Money
Money = Money + 1
print Money
AddMoney()
print Money
The dir( ) Function
dir()内置函数返回包含模块定义的名称的字符串的排序列表。
该列表包含模块中定义的所有模块,变量和函数的名称。 以下是一个简单的例子 -
#!/usr/bin/python
# Import built-in module math
import math
content = dir(math)
print content
执行上述代码时,会产生以下结果 -
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']
这里,特殊字符串变量__name__是模块的名称, __name__是加载模块的文件名。
globals()和locals()函数
globals()和locals()函数可用于返回全局和本地名称空间中的名称,具体取决于调用它们的位置。
如果从函数内调用locals(),它将返回可从该函数本地访问的所有名称。
如果从函数内调用globals(),它将返回可以从该函数全局访问的所有名称。
这两个函数的返回类型是字典。 因此,可以使用keys()函数提取名称。
The reload() Function
将模块导入脚本时,模块顶层部分的代码只执行一次。
因此,如果要重新执行模块中的顶级代码,可以使用reload()函数。 reload()函数再次导入先前导入的模块。 reload()函数的语法是这样的 -
reload(module_name)
这里, module_name是要重新加载的模块的名称,而不是包含模块名称的字符串。 例如,要重新加载hello模块,请执行以下操作 -
reload(hello)
Python中的包
包是一个分层文件目录结构,它定义了一个由模块,子包和子子包组成的Python应用程序环境,依此类推。
考虑Phone目录中可用的文件Pots.py 此文件包含以下源代码行 -
#!/usr/bin/python
def Pots():
print "I'm Pots Phone"
类似地,我们有另外两个文件具有与上面相同名称的不同功能 -
具有Phone/Isdn.py功能的Phone/Isdn.py文件
具有功能G3()的Phone/G3.py文件
现在,在Phone目录中再创建一个__init__.py文件 -
- Phone/__init__.py
要在导入Phone时使所有功能可用,您需要在__init__.py中输入显式的import语句,如下所示 -
from Pots import Pots
from Isdn import Isdn
from G3 import G3
将这些行添加到__init__.py后,导入Phone包时可以使用所有这些类。
#!/usr/bin/python
# Now import your Phone Package.
import Phone
Phone.Pots()
Phone.Isdn()
Phone.G3()
执行上述代码时,会产生以下结果 -
I'm Pots Phone
I'm 3G Phone
I'm ISDN Phone
在上面的示例中,我们以每个文件中的单个函数为例,但您可以在文件中保留多个函数。 您还可以在这些文件中定义不同的Python类,然后您可以从这些类中创建包。
Python - Files I/O
本章介绍Python中可用的所有基本I/O函数。 有关更多功能,请参阅标准Python文档。
打印到屏幕
生成输出的最简单方法是使用print语句,您可以在其中传递由逗号分隔的零个或多个表达式。 此函数将传递的表达式转换为字符串,并将结果写入标准输出,如下所示 -
#!/usr/bin/python
print "Python is really a great language,", "isn't it?"
这会在您的标准屏幕上产生以下结果 -
Python is really a great language, isn't it?
读键盘输入
Python提供了两个内置函数来从标准输入读取一行文本,默认情况下来自键盘。 这些功能是 -
- raw_input
- input
raw_input函数
raw_input([prompt])函数从标准输入读取一行并将其作为字符串返回(删除尾随换行符)。
#!/usr/bin/python
str = raw_input("Enter your input: ");
print "Received input is : ", str
这会提示您输入任何字符串,它将在屏幕上显示相同的字符串。 当我输入“Hello Python!”时,它的输出是这样的 -
Enter your input: Hello Python
Received input is : Hello Python
input功能
input([prompt])函数等效于raw_input,除了它假定输入是有效的Python表达式并将评估结果返回给您。
#!/usr/bin/python
str = input("Enter your input: ");
print "Received input is : ", str
这将对输入的输入产生以下结果 -
Enter your input: [x*5 for x in range(2,10,2)]
Recieved input is : [10, 20, 30, 40]
打开和关闭文件 (Opening and Closing Files)
到目前为止,您一直在阅读和写入标准输入和输出。 现在,我们将看到如何使用实际的数据文件。
Python提供了默认操作文件所需的基本功能和方法。 您可以使用file对象执行大部分文件操作。
open功能
在您可以读取或写入文件之前,必须使用Python的内置open()函数打开它。 此函数创建一个file对象,用于调用与其关联的其他支持方法。
语法 (Syntax)
file object = open(file_name [, access_mode][, buffering])
以下是参数详情 -
file_name - file_name参数是一个字符串值,其中包含要访问的文件的名称。
access_mode - access_mode确定必须打开文件的模式,即读取,写入,追加等。下表中给出了可能值的完整列表。 这是可选参数,读取默认文件访问模式(r)。
buffering - 如果缓冲值设置为0,则不进行缓冲。 如果缓冲值为1,则在访问文件时执行行缓冲。 如果将缓冲值指定为大于1的整数,则使用指示的缓冲区大小执行缓冲操作。 如果为负,则缓冲区大小是系统默认值(默认行为)。
以下是打开文件的不同模式列表 -
| Sr.No. | 模式和描述 |
|---|---|
| 1 | r 打开文件以供阅读。 文件指针位于文件的开头。 这是默认模式。 |
| 2 | rb 打开文件以仅以二进制格式读取。 文件指针位于文件的开头。 这是默认模式。 |
| 3 | r+ 打开文件进行读写。 文件指针放在文件的开头。 |
| 4 | rb+ 打开二进制格式的读写文件。 文件指针放在文件的开头。 |
| 5 | w 打开文件仅供写入。 如果文件存在,则覆盖文件。 如果该文件不存在,则创建一个用于写入的新文件。 |
| 6 | wb 打开文件以仅以二进制格式写入。 如果文件存在,则覆盖文件。 如果该文件不存在,则创建一个用于写入的新文件。 |
| 7 | w+ 打开文件进行写入和读取。 如果文件存在,则覆盖现有文件。 如果该文件不存在,则创建一个用于读写的新文件。 |
| 8 | wb+ 打开以二进制格式写入和读取的文件。 如果文件存在,则覆盖现有文件。 如果该文件不存在,则创建一个用于读写的新文件。 |
| 9 | a 打开要附加的文件。 如果文件存在,则文件指针位于文件的末尾。 也就是说,文件处于追加模式。 如果该文件不存在,则会创建一个用于写入的新文件。 |
| 10 | ab 打开文件以二进制格式附加。 如果文件存在,则文件指针位于文件的末尾。 也就是说,文件处于追加模式。 如果该文件不存在,则会创建一个用于写入的新文件。 |
| 11 | a+ 打开文件以进行追加和阅读。 如果文件存在,则文件指针位于文件的末尾。 该文件以追加模式打开。 如果该文件不存在,则会创建一个用于读写的新文件。 |
| 12 | ab+ 打开文件,以二进制格式追加和读取。 如果文件存在,则文件指针位于文件的末尾。 该文件以追加模式打开。 如果该文件不存在,则会创建一个用于读写的新文件。 |
file对象属性
打开文件并且您有一个file对象后,您可以获得与该文件相关的各种信息。
以下是与文件对象相关的所有属性的列表 -
| Sr.No. | 属性和描述 |
|---|---|
| 1 | file.closed 如果文件关闭则返回true,否则返回false。 |
| 2 | file.mode 返回打开文件的访问模式。 |
| 3 | file.name 返回文件的名称。 |
| 4 | file.softspace 如果print明确要求空间,则返回false,否则返回true。 |
例子 (Example)
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspace
这会产生以下结果 -
Name of the file: foo.txt
Closed or not : False
Opening mode : wb
Softspace flag : 0
The close() Method
file对象的close()方法刷新任何未写入的信息并关闭文件对象,之后不再进行写入。
当文件的引用对象被重新分配给另一个文件时,Python会自动关闭文件。 使用close()方法关闭文件是一种很好的做法。
语法 (Syntax)
fileObject.close();
例子 (Example)
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
# Close opend file
fo.close()
这会产生以下结果 -
Name of the file: foo.txt
读写文件 (Reading and Writing Files)
file对象提供了一组访问方法,使我们的生活更轻松。 我们将看到如何使用read()和write()方法来读写文件。
The write() Method
write()方法将任何字符串写入打开的文件。 值得注意的是,Python字符串可以包含二进制数据而不仅仅是文本。
write()方法不会在字符串的末尾添加换行符('\ n') -
语法 (Syntax)
fileObject.write(string);
这里,传递参数是要写入打开文件的内容。
例子 (Example)
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
fo.write( "Python is a great language.\nYeah its great!!\n");
# Close opend file
fo.close()
上面的方法将创建foo.txt文件,并将在该文件中写入给定内容,最后它将关闭该文件。 如果您要打开此文件,它将具有以下内容。
Python is a great language.
Yeah its great!!
The read() Method
read()方法从打开的文件中读取字符串。 值得注意的是,Python字符串可以包含二进制数据。 除了文本数据。
语法 (Syntax)
fileObject.read([count]);
这里,传递的参数是要从打开的文件中读取的字节数。 此方法从文件的开头开始读取,如果缺少count ,则尝试尽可能多地读取,可能直到文件结束。
例子 (Example)
我们来看一个上面创建的文件foo.txt 。
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Close opend file
fo.close()
这会产生以下结果 -
Read String is : Python is
档案位置
tell()方法告诉你文件中的当前位置; 换句话说,下一次读或写将发生在文件开头的那么多字节处。
seek(offset[, from])方法更改当前文件位置。 offset参数指示要移动的字节数。 from参数指定从哪里移动字节的引用位置。
如果from设置为0,则表示使用文件的开头作为参考位置,1表示使用当前位置作为参考位置,如果设置为2,则将文件末尾作为参考位置。
例子 (Example)
我们来看一个上面创建的文件foo.txt 。
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Check current position
position = fo.tell();
print "Current file position : ", position
# Reposition pointer at the beginning once again
position = fo.seek(0, 0);
str = fo.read(10);
print "Again read String is : ", str
# Close opend file
fo.close()
这会产生以下结果 -
Read String is : Python is
Current file position : 10
Again read String is : Python is
重命名和删除文件
Python os模块提供了帮助您执行文件处理操作的方法,例如重命名和删除文件。
要使用此模块,您需要先导入它,然后才能调用任何相关的功能。
The rename() Method
rename()方法有两个参数,即当前文件名和新文件名。
语法 (Syntax)
os.rename(current_file_name, new_file_name)
例子 (Example)
以下是重命名现有文件test1.txt的示例 -
#!/usr/bin/python
import os
# Rename a file from test1.txt to test2.txt
os.rename( "test1.txt", "test2.txt" )
The remove() Method
您可以使用remove()方法通过提供要删除的文件的名称作为参数来删除文件。
语法 (Syntax)
os.remove(file_name)
例子 (Example)
以下是删除现有文件test2.txt的示例 -
#!/usr/bin/python
import os
# Delete file test2.txt
os.remove("text2.txt")
Python目录
所有文件都包含在各种目录中,Python也没有问题。 os模块有几种方法可以帮助您创建,删除和更改目录。
The mkdir() Method
您可以使用os模块的mkdir()方法在当前目录中创建目录。 您需要为此方法提供一个参数,该参数包含要创建的目录的名称。
语法 (Syntax)
os.mkdir("newdir")
例子 (Example)
以下是在当前目录中创建目录test的示例 -
#!/usr/bin/python
import os
# Create a directory "test"
os.mkdir("test")
The chdir() Method
您可以使用chdir()方法更改当前目录。 chdir()方法接受一个参数,该参数是您要创建当前目录的目录的名称。
语法 (Syntax)
os.chdir("newdir")
例子 (Example)
以下是进入“/ home/newdir”目录的示例 -
#!/usr/bin/python
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")
The getcwd() Method
getcwd()方法显示当前工作目录。
语法 (Syntax)
os.getcwd()
例子 (Example)
以下是给出当前目录的示例 -
#!/usr/bin/python
import os
# This would give location of the current directory
os.getcwd()
The rmdir() Method
rmdir()方法删除目录,该目录作为方法中的参数传递。
在删除目录之前,应删除其中的所有内容。
语法 (Syntax)
os.rmdir('dirname')
例子 (Example)
以下是删除“/ tmp/test”目录的示例。 需要提供目录的完全限定名称,否则它将在当前目录中搜索该目录。
#!/usr/bin/python
import os
# This would remove "/tmp/test" directory.
os.rmdir( "/tmp/test" )
文件和目录相关方法
有三个重要的来源,它们提供了广泛的实用方法来处理和操作Windows和Unix操作系统上的文件和目录。 它们如下 -
Python - Exceptions Handling
Python提供了两个非常重要的功能来处理Python程序中的任何意外错误并在其中添加调试功能 -
Exception Handling - 本教程将介绍这一点。 以下是Python中可用的列表标准异常: 标准异常 。
Assertions - 这将在Python中的Assertions教程中介绍。
标准例外清单 -
| Sr.No. | 例外名称和描述 |
|---|---|
| 1 | Exception 所有例外的基类 |
| 2 | StopIteration 当迭代器的next()方法没有指向任何对象时引发。 |
| 3 | SystemExit 由sys.exit()函数引发。 |
| 4 | StandardError 除StopIteration和SystemExit之外的所有内置异常的基类。 |
| 5 | ArithmeticError 用于数值计算的所有错误的基类。 |
| 6 | OverflowError 计算超出数字类型的最大限制时引发。 |
| 7 | FloatingPointError 浮点计算失败时引发。 |
| 8 | ZeroDivisionError 当为所有数字类型进行除法或模数为零时引发。 |
| 9 | AssertionError 在Assert语句失败的情况下引发。 |
| 10 | AttributeError 在属性引用或赋值失败的情况下引发。 |
| 11 | EOFError 当没有来自raw_input()或input()函数的输入并且到达文件末尾时引发。 |
| 12 | ImportError 导入语句失败时引发。 |
| 13 | KeyboardInterrupt 当用户中断程序执行时,通常按Ctrl + c引发。 |
| 14 | LookupError 所有查找错误的基类。 |
| 15 | IndexError 在序列中找不到索引时引发。 |
| 16 | KeyError 在字典中找不到指定的键时引发。 |
| 17 | NameError 在本地或全局命名空间中找不到标识符时引发。 |
| 18 | UnboundLocalError 尝试访问函数或方法中的局部变量但未分配任何值时引发。 |
| 19 | EnvironmentError 在Python环境之外发生的所有异常的基类。 |
| 20 | IOError 在输入/输出操作失败时引发,例如在尝试打开不存在的文件时使用print语句或open()函数。 |
| 21 | IOError 引发与操作系统相关的错误。 |
| 22 | SyntaxError 在Python语法中出现错误时引发。 |
| 23 | IndentationError 没有正确指定缩进时引发。 |
| 24 | SystemError 解释器发现内部问题时引发,但遇到此错误时,Python解释器不会退出。 |
| 25 | SystemExit 使用sys.exit()函数退出Python解释器时引发。 如果未在代码中处理,则导致解释器退出。 |
| 26 | TypeError 尝试对指定数据类型无效的操作或函数时引发。 |
| 27 | ValueError 当数据类型的内置函数具有有效的参数类型但参数指定了无效值时引发。 |
| 28 | RuntimeError 当生成的错误不属于任何类别时引发。 |
| 29 | NotImplementedError 当实际上没有实现需要在继承类中实现的抽象方法时引发。 |
Python中的断言
断言是一种完整性检查,您可以在完成程序测试后打开或关闭。
想到断言的最简单方法是将它比作一个raise-if语句(或者更准确,即使是if-if-not语句)。 测试表达式,如果结果为false,则引发异常。
断言由assert语句执行,这是Python的最新关键字,在1.5版中引入。
程序员经常在函数的开头放置断言以检查有效输入,并在函数调用之后检查有效输出。
assert声明
遇到assert语句时,Python会对伴随的表达式求值,这有望成为现实。 如果表达式为false,则Python会引发AssertionError异常。
assert的语法是 -
assert Expression[, Arguments]
如果断言失败,Python使用ArgumentExpression作为AssertionError的参数。 可以使用try-except语句像任何其他异常一样捕获和处理AssertionError异常,但如果不处理,它们将终止程序并产生回溯。
例子 (Example)
这是一个将温度从开尔文度转换为华氏度的函数。 由于开尔文的零度和它一样冷,如果看到负温度,该功能就会失效 -
#!/usr/bin/python
def KelvinToFahrenheit(Temperature):
assert (Temperature >= 0),"Colder than absolute zero!"
return ((Temperature-273)*1.8)+32
print KelvinToFahrenheit(273)
print int(KelvinToFahrenheit(505.78))
print KelvinToFahrenheit(-5)
执行上述代码时,会产生以下结果 -
32.0
451
Traceback (most recent call last):
File "test.py", line 9, in <module>
print KelvinToFahrenheit(-5)
File "test.py", line 4, in KelvinToFahrenheit
assert (Temperature >= 0),"Colder than absolute zero!"
AssertionError: Colder than absolute zero!
什么是例外?
异常是在执行程序期间发生的事件,该程序会中断程序指令的正常流程。 通常,当Python脚本遇到无法处理的情况时,会引发异常。 异常是表示错误的Python对象。
当Python脚本引发异常时,它必须立即处理异常,否则它将终止并退出。
处理异常
如果您有一些可能引发异常的suspicious代码,您可以通过将可疑代码放在try: block中来保护您的程序。 在try:block之后,包含一个except:语句,后跟一个代码块,尽可能优雅地处理问题。
语法 (Syntax)
这是try....except...else简单语法try....except...else blocks -
try:
You do your operations here;
......................
except <i>ExceptionI</i>:
If there is ExceptionI, then execute this block.
except <i>ExceptionII</i>:
If there is ExceptionII, then execute this block.
......................
else:
If there is no exception then execute this block.
以下是关于上述语法的几点重点 -
单个try语句可以有多个except语句。 当try块包含可能引发不同类型异常的语句时,这很有用。
您还可以提供一个通用的except子句,它处理任何异常。
在except子句之后,您可以包含else子句。 如果try:block中的代码不引发异常,则执行else-block中的代码。
else-block是一个不需要try:block保护的代码的好地方。
例子 (Example)
这个例子打开一个文件,在文件中写入内容并优雅地出来,因为根本没有问题 -
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"
fh.close()
这会产生以下结果 -
Written content in the file successfully
例子 (Example)
此示例尝试打开您没有写入权限的文件,因此会引发异常 -
#!/usr/bin/python
try:
fh = open("testfile", "r")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"
这会产生以下结果 -
Error: can't find file or read data
except没有例外的条款
您也可以使用except语句,没有例外定义如下 -
try:
You do your operations here;
......................
except:
If there is any exception, then execute this block.
......................
else:
If there is no exception then execute this block.
这种try-except语句捕获所有发生的异常。 使用这种try-except语句虽然不被认为是一种很好的编程实践,因为它捕获了所有异常但却没有使程序员找出可能发生的问题的根本原因。
具有多个例外的except条款
您还可以使用相同的except语句来处理多个异常,如下所示 -
try:
You do your operations here;
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
If there is any exception from the given exception list,
then execute this block.
......................
else:
If there is no exception then execute this block.
try-finally Clause
您可以使用finally:块和try:块。 finally块是放置必须执行的任何代码的地方,无论try-block是否引发异常。 try-finally语句的语法是这样的 -
try:
You do your operations here;
......................
Due to any exception, this may be skipped.
finally:
This would always be executed.
......................
你也不能使用else子句和finally子句。
例子 (Example)
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
finally:
print "Error: can\'t find file or read data"
如果您无权以书面模式打开文件,则会产生以下结果 -
Error: can't find file or read data
同样的例子可以写得更干净如下 -
#!/usr/bin/python
try:
fh = open("testfile", "w")
try:
fh.write("This is my test file for exception handling!!")
finally:
print "Going to close the file"
fh.close()
except IOError:
print "Error: can\'t find file or read data"
当在try块中抛出异常时,执行会立即传递给finally块。 在执行finally块中的所有语句之后,再次引发异常并在except语句中处理(如果存在于try-except语句的下一个更高层中)。
一个例外的争论
异常可以有一个argument ,该argument是一个值,提供有关该问题的其他信息。 参数的内容因异常而异。 您通过在except子句中提供变量来捕获异常的参数,如下所示 -
try:
You do your operations here;
......................
except <i>ExceptionType, Argument</i>:
You can print value of Argument here...
如果编写代码来处理单个异常,则可以在except语句中使用变量的名称。 如果要捕获多个异常,则可以使用变量跟随异常的元组。
此变量接收主要包含异常原因的异常值。 变量可以以元组的形式接收单个值或多个值。 此元组通常包含错误字符串,错误号和错误位置。
例子 (Example)
以下是单个例外的示例 -
#!/usr/bin/python
# Define a function here.
def temp_convert(var):
try:
return int(var)
except ValueError, Argument:
print "The argument does not contain numbers\n", Argument
# Call above function here.
temp_convert("xyz");
这会产生以下结果 -
The argument does not contain numbers
invalid literal for int() with base 10: 'xyz'
提出例外
您可以使用raise语句以多种方式引发异常。 raise语句的一般语法如下。
语法 (Syntax)
raise [Exception [, args [, traceback]]]
这里, Exception是Exception的类型(例如,NameError),而argument是exception参数的值。 参数是可选的; 如果未提供,则异常参数为None。
最后一个参数traceback也是可选的(在实践中很少使用),如果存在,则是用于异常的回溯对象。
例子 (Example)
异常可以是字符串,类或对象。 Python核心引发的大多数异常都是类,其中一个参数是类的一个实例。 定义新的异常非常简单,可以按如下方式完成 -
def functionName( level ):
if level < 1:
raise "Invalid level!", level
# The code below to this would not be executed
# if we raise the exception
Note:为了捕获异常,“except”子句必须引用抛出类对象或简单字符串的相同异常。 例如,要捕获上述异常,我们必须编写except子句,如下所示 -
try:
Business Logic here...
except "Invalid level!":
Exception handling here...
else:
Rest of the code here...
用户定义的例外
Python还允许您通过从标准内置异常派生类来创建自己的异常。
这是一个与RuntimeError相关的示例。 这里,创建了一个从RuntimeError子类RuntimeError类。 当捕获异常时需要显示更具体的信息时,这非常有用。
在try块中,引发用户定义的异常并在except块中捕获。 变量e用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg
因此,一旦定义了上面的类,就可以按如下方式引发异常 -
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.args
Python - Object Oriented
Python一直是面向对象的语言,因为它存在。 因此,创建和使用类和对象非常简单。 本章帮助您成为使用Python面向对象编程支持的专家。
如果您之前没有任何面向对象(OO)编程的经验,您可能需要参考它的入门课程或至少某种类型的教程,以便掌握基本概念。
但是,这里是面向对象编程(OOP)的小型介绍,以加快您的速度 -
OOP术语概述
Class - 用户定义的对象原型,它定义了一组表征类的任何对象的属性。 属性是数据成员(类变量和实例变量)和方法,可通过点表示法访问。
Class variable - 由类的所有实例共享的变量。 类变量在类中定义,但在类的任何方法之外。 类变量的使用频率与实例变量不同。
Data member - 包含与类及其对象关联的数据的类变量或实例变量。
Function overloading - 为特定函数分配多个行为。 执行的操作因所涉及的对象或参数的类型而异。
Instance variable - 在方法内定义的变量,仅属于类的当前实例。
Inheritance - 将类的特征传递给从其派生的其他类。
Instance - 某个类的单个对象。 例如,属于Circle类的对象obj是Circle类的实例。
Instantiation - 创建类的实例。
Method - 在类定义中定义的一种特殊函数。
Object - 由其类定义的数据结构的唯一实例。 对象包括数据成员(类变量和实例变量)和方法。
Operator overloading - 为特定运算符分配多个函数。
创建类
class语句创建一个新的类定义。 该类的名称紧跟在关键字class之后,后跟冒号,如下所示 -
class ClassName:
'Optional class documentation string'
class_suite
该类有一个文档字符串,可以通过ClassName.__doc__访问。
class_suite由定义类成员,数据属性和函数的所有组件语句组成。
例子 (Example)
以下是一个简单的Python类的示例 -
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
变量empCount是一个类变量,其值在此类的所有实例之间共享。 这可以从类内部或类外部以Employee.empCount形式访问。
第一个方法__init__()是一个特殊的方法,它被称为类构造函数或初始化方法,当您创建此类的新实例时,Python会调用它们。
您声明其他类方法,如普通函数,但每个方法的第一个参数是self 。 Python将self参数添加到列表中; 调用方法时不需要包含它。
创建实例对象
要创建类的实例,可以使用类名调用该类,并传入__init__方法接受的任何参数。
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)
访问属性
您可以使用带有对象的点运算符来访问对象的属性。 可以使用类名访问类变量,如下所示 -
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
现在,将所有概念放在一起 -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
执行上述代码时,会产生以下结果 -
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2
您可以随时添加,删除或修改类和对象的属性 -
emp1.age = 7 # Add an 'age' attribute.
emp1.age = 8 # Modify 'age' attribute.
del emp1.age # Delete 'age' attribute.
您可以使用以下函数 - 而不是使用常规语句来访问属性 -
getattr(obj, name[, default]) - 访问object的属性。
hasattr(obj,name) - 检查属性是否存在。
setattr(obj,name,value) - 设置属性。 如果属性不存在,则会创建它。
delattr(obj, name) - 删除属性。
hasattr(emp1, 'age') # Returns true if 'age' attribute exists
getattr(emp1, 'age') # Returns value of 'age' attribute
setattr(emp1, 'age', 8) # Set attribute 'age' at 8
delattr(empl, 'age') # Delete attribute 'age'
内置类属性
每个Python类都遵循内置属性,并且可以使用点运算符访问它们,就像任何其他属性一样 -
__dict__ - 包含类名称空间的字典。
__doc__ - 类文档字符串或无,如果未定义。
__name__ - class名称。
__module__ - 定义类的模块名称。 此属性在交互模式下为“__main__”。
__bases__ - 一个可能为空的元组,包含基类,按它们在基类列表中出现的顺序排列。
对于上面的类,让我们尝试访问所有这些属性 -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
print "Employee.__doc__:", Employee.__doc__
print "Employee.__name__:", Employee.__name__
print "Employee.__module__:", Employee.__module__
print "Employee.__bases__:", Employee.__bases__
print "Employee.__dict__:", Employee.__dict__
执行上述代码时,会产生以下结果 -
Employee.__doc__: Common base class for all employees
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: ()
Employee.__dict__: {'__module__': '__main__', 'displayCount':
<function displayCount at 0xb7c84994>, 'empCount': 2,
'displayEmployee': <function displayEmployee at 0xb7c8441c>,
'__doc__': 'Common base class for all employees',
'__init__': <function __init__ at 0xb7c846bc>}
Destroying Objects (Garbage Collection)
Python会自动删除不需要的对象(内置类型或类实例)以释放内存空间。 Python定期回收不再使用的内存块的过程称为垃圾收集。
Python的垃圾收集器在程序执行期间运行,并在对象的引用计数达到零时触发。 对象的引用计数随指向它的别名数量的变化而变化。
对象的引用计数在分配新名称或放置在容器(列表,元组或字典)中时会增加。 当删除del时,对象的引用计数减少,其引用被重新分配,或者引用超出范围。 当对象的引用计数达到零时,Python会自动收集它。
a = 40 # Create object <40>
b = a # Increase ref. count of <40>
c = [b] # Increase ref. count of <40>
del a # Decrease ref. count of <40>
b = 100 # Decrease ref. count of <40>
c[0] = -1 # Decrease ref. count of <40>
您通常不会注意到垃圾收集器何时销毁孤立实例并回收其空间。 但是类可以实现特殊方法__del__() ,称为析构函数,在实例即将被销毁时调用。 此方法可用于清除实例使用的任何非内存资源。
例子 (Example)
这个__del __()析构函数打印一个即将被销毁的实例的类名 -
#!/usr/bin/python
class Point:
def __init__( self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print class_name, "destroyed"
pt1 = Point()
pt2 = pt1
pt3 = pt1
print id(pt1), id(pt2), id(pt3) # prints the ids of the obejcts
del pt1
del pt2
del pt3
执行上面的代码时,会产生以下结果 -
3083401324 3083401324 3083401324
Point destroyed
Note - 理想情况下,您应该在单独的文件中定义类,然后您应该使用import语句将它们导入主程序文件中。
类继承
您可以通过在新类名后面的括号中列出父类,而不是从头开始,通过从预先存在的类派生它来创建类。
子类继承其父类的属性,您可以使用这些属性,就好像它们是在子类中定义的一样。 子类还可以覆盖父级的数据成员和方法。
语法 (Syntax)
派生类的声明与其父类非常相似; 但是,在类名后面给出了一个要继承的基类列表 -
class SubClassName (ParentClass1[, ParentClass2, ...]):
'Optional class documentation string'
class_suite
例子 (Example)
#!/usr/bin/python
class Parent: # define parent class
parentAttr = 100
def __init__(self):
print "Calling parent constructor"
def parentMethod(self):
print 'Calling parent method'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "Parent attribute :", Parent.parentAttr
class Child(Parent): # define child class
def __init__(self):
print "Calling child constructor"
def childMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.childMethod() # child calls its method
c.parentMethod() # calls parent's method
c.setAttr(200) # again call parent's method
c.getAttr() # again call parent's method
执行上述代码时,会产生以下结果 -
Calling child constructor
Calling child method
Calling parent method
Parent attribute : 200
类似地,您可以从多个父类驱动一个类,如下所示 -
class A: # define your class A
.....
class B: # define your class B
.....
class C(A, B): # subclass of A and B
.....
您可以使用issubclass()或isinstance()函数来检查两个类和实例的关系。
如果给定的子类sub确实是超类sup的子类,则issubclass(sub, sup)布尔函数返回true。
如果obj是类Class的实例或者是Class的子类的实例,则isinstance(obj, Class)布尔函数返回true
重写方法
您始终可以覆盖父类方法。 覆盖父方法的一个原因是因为您可能需要子类中的特殊功能或不同功能。
例子 (Example)
#!/usr/bin/python
class Parent: # define parent class
def myMethod(self):
print 'Calling parent method'
class Child(Parent): # define child class
def myMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.myMethod() # child calls overridden method
执行上述代码时,会产生以下结果 -
Calling child method
基础重载方法
下表列出了一些您可以在自己的类中覆盖的通用功能 -
| Sr.No. | 方法,描述和样本调用 |
|---|---|
| 1 | __init__ ( self [,args...] ) 构造函数(带有任何可选参数) 示例调用: obj = className(args) |
| 2 | __del__( self ) 析构函数,删除一个对象 样本调用: del obj |
| 3 | __repr__( self ) 可评估的字符串表示 样本电话: repr(obj) |
| 4 | __str__( self ) 可打印的字符串表示 样本调用: str(obj) |
| 5 | __cmp__ ( self, x ) 对象比较 样本调用: cmp(obj, x) |
重载运算符
假设您已经创建了一个Vector类来表示二维向量,当您使用加号运算符添加它们时会发生什么? 很可能Python会对你大喊大叫。
但是,您可以在类中定义__add__方法以执行向量添加,然后加号运算符将按预期运行 -
例子 (Example)
#!/usr/bin/python
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2
执行上述代码时,会产生以下结果 -
Vector(7,8)
数据隐藏
对象的属性在类定义之外可能可见也可能不可见。 您需要使用双下划线前缀命名属性,然后这些属性不会被外人直接看到。
例子 (Example)
#!/usr/bin/python
class JustCounter:
__secretCount = 0
def count(self):
self.__secretCount += 1
print self.__secretCount
counter = JustCounter()
counter.count()
counter.count()
print counter.__secretCount
执行上述代码时,会产生以下结果 -
1
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print counter.__secretCount
AttributeError: JustCounter instance has no attribute '__secretCount'
Python通过内部更改名称来包含类名来保护这些成员。 您可以访问object._className__attrName等属性。 如果你将以下内容替换你的最后一行,那么它适合你 -
.........................
print counter._JustCounter__secretCount
执行上述代码时,会产生以下结果 -
1
2
2
Python - Regular Expressions
regular expression是一种特殊的字符序列,可帮助您使用模式中保存的专用语法来匹配或查找其他字符串或字符串集。 正则表达式在UNIX世界中被广泛使用。
该模块在Python中为类似Perl的正则表达式提供了完全支持。 如果在编译或使用正则表达式时发生错误,则re模块会引发异常re.error。
我们将介绍两个重要的函数,它们将用于处理正则表达式。 但首先要做的是:有各种各样的字符,当它们用于正则表达式时会有特殊意义。 为了避免在处理正则表达式时出现任何混淆,我们将使用Raw Strings作为r'expression' 。
match功能
此函数尝试将RE pattern与带有可选flags string匹配。
这是此函数的语法 -
re.match(pattern, string, flags=0)
以下是参数的说明 -
| Sr.No. | 参数和描述 |
|---|---|
| 1 | pattern 这是要匹配的正则表达式。 |
| 2 | string 这是字符串,将搜索该字符串以匹配字符串开头的模式。 |
| 3 | flags 您可以使用按位OR(|)指定不同的标志。 这些是修饰符,列在下表中。 |
re.match函数在成功时返回match对象,在失败时返回None 。 我们使用match对象的group(num)或groups()函数来获得匹配的表达式。
| Sr.No. | 匹配对象方法和描述 |
|---|---|
| 1 | group(num=0) 此方法返回整个匹配(或特定子组num) |
| 2 | groups() 此方法返回元组中所有匹配的子组(如果没有则为空) |
例子 (Example)
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
执行上面的代码时,会产生以下结果 -
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
search功能
此函数使用可选flags在string搜索第一次出现的RE pattern 。
这是此函数的语法 -
re.search(pattern, string, flags=0)
以下是参数的说明 -
| Sr.No. | 参数和描述 |
|---|---|
| 1 | pattern 这是要匹配的正则表达式。 |
| 2 | string 这是字符串,将搜索该字符串以匹配字符串中任何位置的模式。 |
| 3 | flags 您可以使用按位OR(|)指定不同的标志。 这些是修饰符,列在下表中。 |
re.search函数在成功时返回match对象,在失败时返回none 。 我们使用match对象的group(num)或groups()函数来获得匹配的表达式。
| Sr.No. | 匹配对象方法和描述 |
|---|---|
| 1 | group(num=0) 此方法返回整个匹配(或特定子组num) |
| 2 | groups() 此方法返回元组中所有匹配的子组(如果没有则为空) |
例子 (Example)
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"
执行上面的代码时,会产生以下结果 -
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarter
匹配与搜索
Python提供了两种基于正则表达式的不同原语操作: match仅在字符串的开头检查匹配,而search在字符串中的任何位置检查匹配(这是Perl默认执行的操作)。
例子 (Example)
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print "search --> searchObj.group() : ", searchObj.group()
else:
print "Nothing found!!"
执行上述代码时,会产生以下结果 -
No match!!
search --> matchObj.group() : dogs
搜索和替换
使用正则表达式的最重要的re方法之一是sub 。
语法 (Syntax)
re.sub(pattern, repl, string, max=0)
此方法用repl替换string所有出现的RE pattern ,替换所有出现,除非提供max 。 此方法返回修改的字符串。
例子 (Example)
#!/usr/bin/python
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", num
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print "Phone Num : ", num
执行上述代码时,会产生以下结果 -
Phone Num : 2004-959-559
Phone Num : 2004959559
正则表达式修饰符:选项标志
正则表达式文字可以包括可选修饰符来控制匹配的各个方面。 修饰符被指定为可选标志。 您可以使用异或(|)提供多个修饰符,如前所示,可以用其中一个来表示 -
| Sr.No. | 修饰符和描述 |
|---|---|
| 1 | re.I 执行不区分大小写的匹配。 |
| 2 | re.L 根据当前区域设置解释单词。 此解释会影响字母组(\ w和\ W)以及字边界行为(\ b和\ B)。 |
| 3 | re.M 使$匹配行的结尾(不仅仅是字符串的结尾)并使^匹配任何行的开头(不仅仅是字符串的开头)。 |
| 4 | re.S 使句点(点)匹配任何字符,包括换行符。 |
| 5 | re.U 根据Unicode字符集解释字母。 此标志会影响\ w,\ W,\ b,\ B的行为。 |
| 6 | re.X 允许“cuter”正则表达式语法。 它忽略了空格(除了set []内部或者用反斜杠转义时),并将未转义的#视为注释标记。 |
正则表达式
除了控制字符, (+ ? . * ^ $ ( ) [ ] { } | \) ,所有字符都匹配。 您可以通过在控制字符前加一个反斜杠来转义它。
下表列出了Python中可用的正则表达式语法 -
| Sr.No. | 模式和描述 |
|---|---|
| 1 | ^ 匹配行首。 |
| 2 | $ 匹配行尾。 |
| 3 | . 匹配除换行符之外的任何单个字符。 使用m选项也可以匹配换行符。 |
| 4 | [...] 匹配括号中的任何单个字符。 |
| 5 | [^...] 匹配不在括号中的任何单个字符 |
| 6 | re* 匹配前面表达式的0次或更多次出现。 |
| 7 | re+ 匹配1个或多个前面的表达式。 |
| 8 | re? 匹配前面表达式的0或1次出现。 |
| 9 | re{ n} 准确匹配前面表达式的n个出现次数。 |
| 10 | re{ n,} 匹配前面表达式的n次或多次出现。 |
| 11 | re{ n, m} 匹配前面表达式的至少n次和最多m次出现。 |
| 12 | a| b 匹配a或b。 |
| 13 | (re) 对正则表达式进行分组并记住匹配的文本。 |
| 14 | (?imx) 暂时切换正则表达式中的i,m或x选项。 如果在括号中,只有该区域受到影响。 |
| 15 | (?-imx) 暂时切换正则表达式中的i,m或x选项。 如果在括号中,只有该区域受到影响。 |
| 16 | (?: re) 将正则表达式分组而不记住匹配的文本。 |
| 17 | (?imx: re) 暂时切换括号内的i,m或x选项。 |
| 18 | (?-imx: re) 暂时切换括号内的i,m或x选项。 |
| 19 | (?#...) 评论。 |
| 20 | (?= re) 使用模式指定位置。 没有范围。 |
| 21 | (?! re) 使用模式否定指定位置。 没有范围。 |
| 22 | (?》 re) 匹配独立模式,无需回溯。 |
| 23 | \w 匹配单词字符。 |
| 24 | \W 匹配非单词字符。 |
| 25 | \s 匹配空白。 相当于[\ t\n\r\n]。 |
| 26 | \S 匹配非空白。 |
| 27 | \d 匹配数字。 相当于[0-9]。 |
| 28 | \D 匹配非数字。 |
| 29 | \A 匹配字符串的开头。 |
| 30 | \Z 匹配字符串的结尾。 如果存在换行符,则它在换行符之前匹配。 |
| 31 | \z 匹配字符串的结尾。 |
| 32 | \G 匹配指向上一场比赛结束的位置。 |
| 33 | \b 在括号外匹配单词边界。 在括号内匹配退格(0x08)。 |
| 34 | \B 匹配非字边界。 |
| 35 | \n, \t, etc. 匹配换行符,回车符,制表符等。 |
| 36 | \1...\9 匹配第n个分组子表达式。 |
| 37 | \10 如果已匹配,则匹配第n个分组子表达式。 否则指的是字符代码的八进制表示。 |
正则表达式示例
文字字符
| Sr.No. | 示例和说明 |
|---|---|
| 1 | python 匹配“python”。 |
角色类
| Sr.No. | 示例和说明 |
|---|---|
| 1 | [Pp]ython 匹配“Python”或“python” |
| 2 | rub[ye] 匹配“红宝石”或“鲁布” |
| 3 | [aeiou] 匹配任何一个小写元音 |
| 4 | [0-9] 匹配任何数字; 与[0123456789]相同 |
| 5 | [az] 匹配任何小写ASCII字母 |
| 6 | [AZ] 匹配任何大写的ASCII字母 |
| 7 | [a-zA-Z0-9] 匹配上述任何一项 |
| 8 | [^aeiou] 匹配小写元音以外的任何内容 |
| 9 | [^0-9] 匹配除数字之外的任何内容 |
特殊字符类
| Sr.No. | 示例和说明 |
|---|---|
| 1 | . 匹配除换行符之外的任何字符 |
| 2 | \d 匹配数字:[0-9] |
| 3 | \D 匹配非数字:[^ 0-9] |
| 4 | \s 匹配空白字符:[\ t\r\n\f] |
| 5 | \S 匹配非空白:[^\t\r\n\f] |
| 6 | \w 匹配单个字符:[A-Za-z0-9_] |
| 7 | \W 匹配非单词字符:[^ A-Za-z0-9_] |
重复案件
| Sr.No. | 示例和说明 |
|---|---|
| 1 | ruby? 匹配“rub”或“ruby”:y是可选的 |
| 2 | ruby* 匹配“擦”加0或更多ys |
| 3 | ruby+ 匹配“擦”加1或更多ys |
| 4 | \d{3} 正好匹配3位数 |
| 5 | \d{3,} 匹配3位或更多位数 |
| 6 | \d{3,5} 匹配3,4或5位数 |
Nongreedy重复
这匹配最小的重复次数 -
| Sr.No. | 示例和说明 |
|---|---|
| 1 | 《.*》 贪心重复:匹配“ |
| 2 | 《.*?》 Nongreedy:匹配“ |
用括号分组
| Sr.No. | 示例和说明 |
|---|---|
| 1 | \D\d+ 没有组:+重复\ d |
| 2 | (\D\d)+ 分组:+重复\ D\d对 |
| 3 | ([Pp]ython(, )?)+ 匹配“Python”,“Python,python,python”等。 |
反向引用(Backreferences)
这与之前匹配的组再次匹配 -
| Sr.No. | 示例和说明 |
|---|---|
| 1 | ([Pp])ython&\1ails 匹配python和pails或Python&Pails |
| 2 | (['"])[^\1]*\1 单引号或双引号。 \1匹配第一组匹配的任何内容。 \2匹配第二组匹配的任何内容等。 |
替代品(Alternatives)
| Sr.No. | 示例和说明 |
|---|---|
| 1 | python|perl 匹配“python”或“perl” |
| 2 | rub(y|le)) 匹配“红宝石”或“卢布” |
| 3 | Python(!+|\?) “Python”后跟一个或多个! 还是一个? |
Anchors
这需要指定匹配位置。
| Sr.No. | 示例和说明 |
|---|---|
| 1 | ^Python 在字符串或内部行的开头匹配“Python” |
| 2 | Python$ 在字符串或行的末尾匹配“Python” |
| 3 | \APython 在字符串的开头匹配“Python” |
| 4 | Python\Z 在字符串末尾匹配“Python” |
| 5 | \bPython\b 在单词边界匹配“Python” |
| 6 | \brub\B \B是非单词边界:在“rube”和“ruby”中匹配“rub”但不单独 |
| 7 | Python(?=!) 匹配“Python”,如果后跟感叹号。 |
| 8 | Python(?!!) 匹配“Python”,如果没有后跟感叹号。 |
带括号的特殊语法
| Sr.No. | 示例和说明 |
|---|---|
| 1 | R(?#comment) 匹配“R”。 其余的都是评论 |
| 2 | R(?i)uby 匹配“uby”时不区分大小写 |
| 3 | R(?i:uby) 与上面相同 |
| 4 | rub(?:y|le)) 仅在不创建\ 1反向引用的情况下进行分组 |
Python - CGI Programming
通用网关接口(CGI)是一组标准,用于定义如何在Web服务器和自定义脚本之间交换信息。 CGI规范目前由NCSA维护。
什么是CGI?
通用网关接口(CGI)是外部网关程序的标准,用于与信息服务器(如HTTP服务器)连接。
目前的版本是CGI/1.1,CGI/1.2正在进行中。
网页浏览 (Web Browsing)
要理解CGI的概念,让我们看看当我们点击超链接浏览特定网页或URL时会发生什么。
您的浏览器会联系HTTP Web服务器并要求提供URL,即文件名。
Web Server解析URL并查找文件名。 如果它发现该文件然后将其发送回浏览器,否则会发送一条错误消息,指出您请求了错误的文件。
Web浏览器从Web服务器获取响应,并显示接收的文件或错误消息。
但是,可以设置HTTP服务器,以便每当请求某个目录中的文件时不发回该文件; 相反,它作为一个程序执行,无论该程序输出什么,都会被发回给您的浏览器进行显示。 此功能称为公共网关接口或CGI,程序称为CGI脚本。 这些CGI程序可以是Python脚本,PERL脚本,Shell脚本,C或C ++程序等。
CGI架构图 (CGI Architecture Diagram)
Web服务器支持和配置
在继续进行CGI编程之前,请确保您的Web服务器支持CGI并配置为处理CGI程序。 HTTP服务器要执行的所有CGI程序都保存在预先配置的目录中。 此目录称为CGI目录,按照惯例,它名为/ var/www/cgi-bin。 按照惯例,CGI文件的扩展名为。 cgi,但你也可以用python扩展名.py来保存你的文件。
默认情况下,Linux服务器配置为仅运行/ var/www中cgi-bin目录中的脚本。 如果要指定任何其他目录来运行CGI脚本,请在httpd.conf文件中注释以下行 -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>
在这里,我们假设您已经成功运行Web Server,并且您可以运行任何其他CGI程序,如Perl或Shell等。
第一个CGI程序 (First CGI Program)
这是一个简单的链接,它链接到一个名为hello.py的CGI脚本。 此文件保存在/ var/www/cgi-bin目录中,并具有以下内容。 在运行CGI程序之前,请确保使用chmod 755 hello.py UNIX命令更改文件模式以使文件可执行。
#!/usr/bin/python
print "Content-type:text/html\r\n\r\n"
print '<html>'
print '<head>'
print '<title>Hello Word - First CGI Program</title>'
print '</head>'
print '<body>'
print '<h2>Hello Word! This is my first CGI program</h2>'
print '</body>'
print '</html>'
如果单击hello.py,则会生成以下输出 -
你好Word! 这是我的第一个CGI计划 |
这个hello.py脚本是一个简单的Python脚本,它将其输出写入STDOUT文件,即屏幕。 有一个重要的额外功能,第一行打印Content-type:text/html\r\n\r\n 。 此行将发送回浏览器,并指定要在浏览器屏幕上显示的内容类型。
到目前为止,您必须了解CGI的基本概念,并且可以使用Python编写许多复杂的CGI程序。 此脚本还可以与任何其他外部系统交互,以交换RDBMS等信息。
HTTP标头
Content-type:text/html\r\n\r\n是HTTP标头的一部分,它被发送到浏览器以了解内容。 所有HTTP标头将采用以下形式 -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\n
很少有其他重要的HTTP标头,您将在CGI编程中经常使用它们。
| Sr.No. | 标题和说明 |
|---|---|
| 1 | Content-type: MIME字符串,用于定义要返回的文件的格式。 示例是Content-type:text/html |
| 2 | Expires: Date 信息失效的日期。 浏览器使用它来决定何时需要刷新页面。 有效日期字符串的格式为01 Jan 1998 12:00:00 GMT。 |
| 3 | Location: URL 返回的URL而不是请求的URL。 您可以使用此字段将请求重定向到任何文件。 |
| 4 | Last-modified: Date 上次修改资源的日期。 |
| 5 | Content-length: N 返回数据的长度(以字节为单位)。 浏览器使用此值报告文件的估计下载时间。 |
| 6 | Set-Cookie: String 设置通过string传递的cookie |
CGI环境变量 (CGI Environment Variables)
所有CGI程序都可以访问以下环境变量。 在编写任何CGI程序时,这些变量都起着重要作用。
| Sr.No. | 变量名称和描述 |
|---|---|
| 1 | CONTENT_TYPE 内容的数据类型。 客户端将附加内容发送到服务器时使用。 例如,文件上传。 |
| 2 | CONTENT_LENGTH 查询信息的长度。 它仅适用于POST请求。 |
| 3 | HTTP_COOKIE 以键和值对的形式返回设置的cookie。 |
| 4 | HTTP_USER_AGENT User-Agent请求标头字段包含有关发起请求的用户代理的信息。 它是Web浏览器的名称。 |
| 5 | PATH_INFO CGI脚本的路径。 |
| 6 | QUERY_STRING 使用GET方法请求发送的URL编码信息。 |
| 7 | REMOTE_ADDR 发出请求的远程主机的IP地址。 这是有用的日志记录或身份验证。 |
| 8 | REMOTE_HOST 发出请求的主机的完全限定名称。 如果此信息不可用,则可以使用REMOTE_ADDR获取IR地址。 |
| 9 | REQUEST_METHOD 用于发出请求的方法。 最常用的方法是GET和POST。 |
| 10 | SCRIPT_FILENAME CGI脚本的完整路径。 |
| 11 | SCRIPT_NAME CGI脚本的名称。 |
| 12 | SERVER_NAME 服务器的主机名或IP地址 |
| 13 | SERVER_SOFTWARE 服务器正在运行的软件的名称和版本。 |
这是一个小型CGI程序,列出了所有CGI变量。 单击此链接可查看结果获取环境
#!/usr/bin/python
import os
print "Content-type: text/html\r\n\r\n";
print "<font size=+1>Environment</font><\br>";
for param in os.environ.keys():
print "<b>%20s</b>: %s<\br>" % (param, os.environ[param])
GET和POST方法 (GET and POST Methods)
当您需要将某些信息从浏览器传递到Web服务器并最终传递到CGI程序时,您必须遇到很多情况。 最常见的是,浏览器使用两种方法将这些信息传递给Web服务器。 这些方法是GET方法和POST方法。
使用GET方法传递信息
GET方法发送附加到页面请求的编码用户信息。 页面和编码信息由?分隔。 性格如下 -
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2
GET方法是将信息从浏览器传递到Web服务器的默认方法,它会生成一个长字符串,显示在浏览器的Location:框中。 如果您要将密码或其他敏感信息传递给服务器,请勿使用GET方法。 GET方法具有大小限制:在请求字符串中只能发送1024个字符。 GET方法使用QUERY_STRING标头发送信息,并可通过QUERY_STRING环境变量在CGI程序中访问。
您可以通过简单地连接键和值对以及任何URL来传递信息,也可以使用HTML
简单URL示例:获取方法
这是一个简单的URL,它使用GET方法将两个值传递给hello_get.py程序。
/cgi-bin/hello_get.py?first_name=ZARA&last_name=ALI下面是hello_get.py脚本,用于处理Web浏览器提供的输入。 我们将使用cgi模块,这使得访问传递的信息变得非常容易 -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"
这将产生以下结果 -
你好ZARA ALI |
简单形式示例:GET方法
此示例使用HTML FORM和提交按钮传递两个值。 我们使用相同的CGI脚本hello_get.py来处理此输入。
<form action = "/cgi-bin/hello_get.py" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>
以下是上述表单的实际输出,您输入名字和姓氏,然后单击提交按钮以查看结果。
使用POST方法传递信息
通常更可靠的将信息传递给CGI程序的方法是POST方法。 这包装信息的方式与GET方法完全相同,但不是在文本字符串之后将其作为文本字符串发送? 在URL中,它将其作为单独的消息发送。 此消息以标准输入的形式进入CGI脚本。
下面是相同的hello_get.py脚本,它处理GET和POST方法。
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"
让我们再次采用与上面相同的示例,它使用HTML FORM和提交按钮传递两个值。 我们使用相同的CGI脚本hello_get.py来处理此输入。
<form action = "/cgi-bin/hello_get.py" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>
以下是上述表格的实际输出。 输入名字和姓氏,然后单击“提交”按钮以查看结果。
将复选框数据传递给CGI程序
如果需要选择多个选项,则使用复选框。
以下是带有两个复选框的表单的示例HTML代码 -
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>
此代码的结果如下:
下面是checkbox.cgi脚本,用于处理Web浏览器为复选框按钮提供的输入。
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('maths'):
math_flag = "ON"
else:
math_flag = "OFF"
if form.getvalue('physics'):
physics_flag = "ON"
else:
physics_flag = "OFF"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Checkbox - Third CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> CheckBox Maths is : %s</h2>" % math_flag
print "<h2> CheckBox Physics is : %s</h2>" % physics_flag
print "</body>"
print "</html>"
将单选按钮数据传递给CGI程序
当只需要选择一个选项时,使用单选按钮。
以下是带有两个单选按钮的表单的示例HTML代码 -
<form action = "/cgi-bin/radiobutton.py" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" /> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>
此代码的结果如下:
下面是radiobutton.py脚本,用于处理网络浏览器为单选按钮提供的输入 -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('subject'):
subject = form.getvalue('subject')
else:
subject = "Not set"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Radio - Fourth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"
将文本区域数据传递给CGI程序
当多行文本必须传递给CGI程序时,使用TEXTAREA元素。
以下是带有TEXTAREA框的表单的示例HTML代码 -
<form action = "/cgi-bin/textarea.py" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>
此代码的结果如下:
下面是textarea.cgi脚本来处理Web浏览器给出的输入 -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Entered Text Content is %s</h2>" % text_content
print "</body>"
将下拉框数据传递给CGI程序
当我们有许多可用选项但只选择一个或两个时,使用下拉框。
以下是带有一个下拉框的表单的示例HTML代码 -
<form action = "/cgi-bin/dropdown.py" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>
此代码的结果如下:
下面是dropdown.py脚本,用于处理Web浏览器提供的输入。
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('dropdown'):
subject = form.getvalue('dropdown')
else:
subject = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Dropdown Box - Sixth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"
在CGI中使用cookie (Using Cookies in CGI)
HTTP协议是无状态协议。 对于商业网站,需要在不同页面之间维护会话信息。 例如,一个用户注册在完成许多页面后结束。 如何在所有网页上维护用户的会话信息?
在许多情况下,使用Cookie是记住和跟踪偏好,购买,佣金以及更好的访问者体验或网站统计所需的其他信息的最有效方法。
它是如何工作的 (How It Works?)
您的服务器以cookie的形式向访问者的浏览器发送一些数据。 浏览器可以接受cookie。 如果是,则将其作为纯文本记录存储在访问者的硬盘上。 现在,当访问者到达您网站上的另一个页面时,该Cookie可供检索。 检索后,您的服务器知道/记住存储的内容。
Cookie是5个可变长度字段的纯文本数据记录 -
Expires - Cookie过期的日期。 如果这是空白,则访问者退出浏览器时cookie将过期。
Domain - 您网站的域名。
Path - 设置cookie的目录或网页的路径。 如果要从任何目录或页面检索cookie,这可能为空。
Secure - 如果此字段包含单词“secure”,则只能使用安全服务器检索cookie。 如果此字段为空,则不存在此类限制。
Name=Value - 以键和值对的形式设置和检索Cookie。
设置Cookies (Setting up Cookies)
将cookie发送到浏览器非常容易。 这些cookie与HTTP标头一起发送到Content-type字段。 假设您要将UserID和密码设置为cookie。 设置cookie如下 -
#!/usr/bin/python
print "Set-Cookie:UserID = XYZ;\r\n"
print "Set-Cookie:Password = XYZ123;\r\n"
print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT";\r\n"
print "Set-Cookie:Domain = www.iowiki.com;\r\n"
print "Set-Cookie:Path = /perl;\n"
print "Content-type:text/html\r\n\r\n"
...........Rest of the HTML Content....
从这个例子中,您必须了解如何设置cookie。 我们使用Set-Cookie HTTP标头来设置cookie。
可以选择设置Expires,Domain和Path等Cookie属性。 值得注意的是,在发送魔术行之前设置了cookie "Content-type:text/html\r\n\r\n 。
检索Cookies (Retrieving Cookies)
检索所有设置的cookie非常容易。 Cookie存储在CGI环境变量HTTP_COOKIE中,它们将具有以下形式 -
key1 = value1;key2 = value2;key3 = value3....
以下是如何检索Cookie的示例。
#!/usr/bin/python
# Import modules for CGI handling
from os import environ
import cgi, cgitb
if environ.has_key('HTTP_COOKIE'):
for cookie in map(strip, split(environ['HTTP_COOKIE'], ';')):
(key, value ) = split(cookie, '=');
if key == "UserID":
user_id = value
if key == "Password":
password = value
print "User ID = %s" % user_id
print "Password = %s" % password
这会对上面脚本设置的cookie产生以下结果 -
User ID = XYZ
Password = XYZ123
文件上传示例
要上载文件,HTML表单必须将enctype属性设置为multipart/form-data 。 具有文件类型的输入标记创建“浏览”按钮。
<html>
<body>
<form enctype = "multipart/form-data"
action = "save_file.py" method = "post">
<p>File: <input type = "file" name = "filename" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>
此代码的结果如下:
以上示例已被故意禁用以保存人们在我们的服务器上上传文件,但您可以尝试使用您的服务器上面的代码。
这是用于处理文件上传的脚本save_file.py -
#!/usr/bin/python
import cgi, os
import cgitb; cgitb.enable()
form = cgi.FieldStorage()
# Get filename here.
fileitem = form['filename']
# Test if the file was uploaded
if fileitem.filename:
# strip leading path from file name to avoid
# directory traversal attacks
fn = os.path.basename(fileitem.filename)
open('/tmp/' + fn, 'wb').write(fileitem.file.read())
message = 'The file "' + fn + '" was uploaded successfully'
else:
message = 'No file was uploaded'
print """\
Content-Type: text/html\n
<html>
<body>
<p>%s</p>
</body>
</html>
""" % (message,)
如果你在Unix/Linux上运行上面的脚本,那么你需要注意如下替换文件分隔符,否则在windows机器上面open()语句应该可以正常工作。
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))
如何提高“文件下载”对话框?
有时,您希望提供用户可以单击链接的选项,它会向用户弹出“文件下载”对话框,而不是显示实际内容。 这非常简单,可以通过HTTP标头实现。 此HTTP标头与上一节中提到的标头不同。
例如,如果您希望从给定链接下载FileName文件,则其语法如下 -
#!/usr/bin/python
# HTTP Header
print "<b class="notranslate">Content-Type:</b>application/octet-stream; name = \"FileName\"\r\n";
print "<b class="notranslate">Content-Disposition:</b> attachment; filename = \"FileName\"\r\n\n";
# Actual File Content will go here.
fo = open("foo.txt", "rb")
str = fo.read();
print str
# Close opend file
fo.close()
希望你喜欢这个教程。 如果是,请将您的反馈发送给我: 联系我们
Python - MySQL Database Access
数据库接口的Python标准是Python DB-API。 大多数Python数据库接口都遵循此标准。
您可以为您的应用程序选择正确的数据库。 Python Database API支持各种数据库服务器,例如 -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
以下是可用的Python数据库接口列表: Python数据库接口和API 。 您必须为需要访问的每个数据库下载单独的DB API模块。 例如,如果您需要访问Oracle数据库以及MySQL数据库,则必须同时下载Oracle和MySQL数据库模块。
DB API提供了使用Python结构和语法尽可能使用数据库的最低标准。 此API包括以下内容 -
- 导入API模块。
- 获取与数据库的连接。
- 发出SQL语句和存储过程。
- 关闭连接
我们将学习使用MySQL的所有概念,所以让我们来谈谈MySQLdb模块。
什么是MySQLdb?
MySQLdb是用于从Python连接到MySQL数据库服务器的接口。 它实现了Python Database API v2.0,并构建在MySQL C API之上。
如何安装MySQLdb?
在继续之前,请确保在您的计算机上安装了MySQLdb。 只需在Python脚本中键入以下内容并执行它 -
#!/usr/bin/python
import MySQLdb
如果它产生以下结果,那么它意味着没有安装MySQLdb模块 -
Traceback (most recent call last):
File "test.py", line 3, in <module>
import MySQLdb
ImportError: No module named MySQLdb
要安装MySQLdb模块,请使用以下命令 -
For Ubuntu, use the following command -
$ sudo apt-get install python-pip python-dev libmysqlclient-dev
For Fedora, use the following command -
$ sudo dnf install python python-devel mysql-devel redhat-rpm-config gcc
For Python command prompt, use the following command -
pip install MySQL-python
Note - 确保您具有root权限以安装上述模块。
数据库连接 (Database Connection)
在连接MySQL数据库之前,请确保以下内容 -
您已经创建了一个数据库TESTDB。
您已在TESTDB中创建了一个表EMPLOYEE。
此表包含FIRST_NAME,LAST_NAME,AGE,SEX和INCOME字段。
用户ID“testuser”和密码“test123”设置为访问TESTDB。
Python模块MySQLdb已正确安装在您的计算机上。
您已经通过MySQL教程来了解MySQL基础知识。
例子 (Example)
以下是连接MySQL数据库“TESTDB”的示例
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# execute SQL query using <i>execute()</i> method.
cursor.execute("SELECT VERSION()")
# Fetch a single row using <i>fetchone()</i> method.
data = cursor.fetchone()
print "Database version : %s " % data
# disconnect from server
db.close()
运行此脚本时,它在我的Linux机器上产生以下结果。
Database version : 5.0.45
如果与数据源建立连接,则返回连接对象并将其保存到db以供进一步使用,否则db将设置为None。 接下来, db对象用于创建cursor对象,而cursor对象又用于执行SQL查询。 最后,在出来之前,它确保关闭数据库连接并释放资源。
创建数据库表
建立数据库连接后,我们就可以使用创建的游标的execute方法在数据库表中创建表或记录。
例子 (Example)
让我们创建数据库表EMPLOYEE -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# Drop table if it already exist using <i>execute()</i> method.
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# Create table as per requirement
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
# disconnect from server
db.close()
插入操作
当您想要将记录创建到数据库表中时,它是必需的。
例子 (Example)
以下示例,执行SQL INSERT语句以创建记录到EMPLOYEE表中 -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
以上示例可以编写如下以动态创建SQL查询 -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO EMPLOYEE(FIRST_NAME, \
LAST_NAME, AGE, SEX, INCOME) \
VALUES ('%s', '%s', '%d', '%c', '%d' )" % \
('Mac', 'Mohan', 20, 'M', 2000)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
例子 (Example)
以下代码段是另一种执行形式,您可以直接传递参数 -
..................................
user_id = "test123"
password = "password"
con.execute('insert into Login values("%s", "%s")' % \
(user_id, password))
..................................
读操作 (READ Operation)
READ对任何数据库的操作意味着从数据库中获取一些有用的信息。
建立数据库连接后,您就可以对此数据库进行查询。 您可以使用fetchone()方法从数据库表中获取单个记录或fetchall()方法来获取多个值。
fetchone() - 它获取查询结果集的下一行。 结果集是在使用游标对象查询表时返回的对象。
fetchall() - 它获取结果集中的所有行。 如果已从结果集中提取某些行,则它将从结果集中检索剩余的行。
rowcount - 这是一个只读属性,它返回受execute()方法影响的行数。
例子 (Example)
以下过程查询EMPLOYEE表中薪水超过1000的所有记录 -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > '%d'" % (1000)
try:
# Execute the SQL command
cursor.execute(sql)
# Fetch all the rows in a list of lists.
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# Now print fetched result
print "fname=%s,lname=%s,age=%d,sex=%s,income=%d" % \
(fname, lname, age, sex, income )
except:
print "Error: unable to fecth data"
# disconnect from server
db.close()
这将产生以下结果 -
fname=Mac, lname=Mohan, age=20, sex=M, income=2000
更新操作 (Update Operation)
UPDATE对任何数据库的操作意味着更新一个或多个已在数据库中可用的记录。
以下过程将SEX的所有记录更新为'M' 。 在这里,我们将所有男性的年龄增加一年。
例子 (Example)
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# Prepare SQL query to UPDATE required records
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1
WHERE SEX = '%c'" % ('M')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
删除操作
如果要从数据库中删除某些记录,则需要DELETE操作。 以下是从AGE超过20的EMPLOYEE中删除所有记录的程序 -
例子 (Example)
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using <i>cursor()</i> method
cursor = db.cursor()
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()
执行事务 (Performing Transactions)
事务是一种确保数据一致性的机制。 交易具有以下四个属性 -
Atomicity - 事务完成或根本没有任何事情发生。
Consistency - 事务必须以一致状态启动,并使系统保持一致状态。
Isolation - 在当前事务之外不可见事务的中间结果。
Durability - 一旦提交了事务,即使系统出现故障,影响也会持续存在。
Python DB API 2.0提供了两种commit或rollback事务的方法。
例子 (Example)
您已经知道如何实现事务。 这是类似的例子 -
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
COMMIT操作
提交是操作,它向数据库发出绿色信号以完成更改,并且在此操作之后,不能恢复任何更改。
这是一个调用commit方法的简单示例。
db.commit()
回滚操作
如果您对一个或多个更改不满意并且想要完全还原这些更改,请使用rollback()方法。
这是一个调用rollback()方法的简单示例。
db.rollback()
断开数据库 (Disconnecting Database)
要断开数据库连接,请使用close()方法。
db.close()
如果用户使用close()方法关闭与数据库的连接,则DB将回滚所有未完成的事务。 但是,不依赖于任何DB较低级别的实现细节,您的应用程序最好明确地调用commit或rollback。
处理错误 (Handling Errors)
有许多错误来源。 一些示例是执行的SQL语句中的语法错误,连接失败,或者对已经取消或已完成的语句句柄调用fetch方法。
DB API定义了每个数据库模块中必须存在的许多错误。 下表列出了这些例外情况。
| Sr.No. | 例外与描述 |
|---|---|
| 1 | Warning 用于非致命问题。 必须是StandardError的子类。 |
| 2 | Error 错误的基类。 必须是StandardError的子类。 |
| 3 | InterfaceError 用于数据库模块中的错误,而不是数据库本身。 必须是子类Error。 |
| 4 | DatabaseError 用于数据库中的错误。 必须是子类Error。 |
| 5 | DataError DatabaseError的子类,引用数据中的错误。 |
| 6 | OperationalError DatabaseError的子类,指的是丢失与数据库的连接等错误。 这些错误通常不受Python脚本程序的控制。 |
| 7 | IntegrityError DatabaseError的子类,用于可能破坏关系完整性的情况,例如唯一性约束或外键。 |
| 8 | InternalError DatabaseError的子类,引用数据库模块内部的错误,例如游标不再处于活动状态。 |
| 9 | ProgrammingError DatabaseError的子类,引用错误,例如错误的表名和其他可以安全地归咎于你的东西。 |
| 10 | NotSupportedError DatabaseError的子类,指的是尝试调用不支持的功能。 |
您的Python脚本应该处理这些错误,但在使用上述任何异常之前,请确保您的MySQLdb支持该异常。 您可以通过阅读DB API 2.0规范获得有关它们的更多信息。
Python - Network Programming
Python提供两种级别的网络服务访问。 在较低级别,您可以访问底层操作系统中的基本套接字支持,这允许您为面向连接的协议和无连接协议实现客户端和服务器。
Python还具有库,可以提供对特定应用程序级网络协议的更高级别访问,例如FTP,HTTP等。
本章将帮助您了解网络中最着名的概念 - 套接字编程。
什么是套接字?
套接字是双向通信信道的端点。 套接字可以在进程内,同一台机器上的进程之间或不同大洲的进程之间进行通信。
套接字可以在许多不同的通道类型上实现:Unix域套接字,TCP,UDP等。 socket库提供了用于处理公共传输的特定类以及用于处理其余传输的通用接口。
套接字有自己的词汇 -
| Sr.No. | 术语和描述 |
|---|---|
| 1 | Domain 用作传输机制的协议族。 这些值是常量,如AF_INET,PF_INET,PF_UNIX,PF_X25等。 |
| 2 | type 两个端点之间的通信类型,通常是面向连接的协议的SOCK_STREAM和无连接协议的SOCK_DGRAM。 |
| 3 | protocol 通常为零,这可以用于识别域内的协议的变体和类型。 |
| 4 | hostname 网络接口的标识符 -
|
| 5 | port 每个服务器侦听在一个或多个端口上调用的客户端。 端口可以是Fixnum端口号,包含端口号的字符串或服务名称。 |
socket模块
要创建套接字,必须使用socket模块中提供的socket.socket()函数,该函数具有一般语法 -
s = socket.socket (socket_family, socket_type, protocol=0)
以下是参数的说明 -
socket_family - 这是AF_UNIX或AF_INET,如前所述。
socket_type - 这是SOCK_STREAM或SOCK_DGRAM。
protocol - 通常被省略,默认为0。
一旦有了socket对象,就可以使用所需的函数来创建客户端或服务器程序。 以下是所需的功能列表 -
服务器套接字方法
| Sr.No. | 方法和描述 |
|---|---|
| 1 | s.bind() 此方法将地址(主机名,端口号对)绑定到套接字。 |
| 2 | s.listen() 此方法设置并启动TCP侦听器。 |
| 3 | s.accept() 这被动地接受TCP客户端连接,等待连接到达(阻塞)。 |
客户端套接字方法
| Sr.No. | 方法和描述 |
|---|---|
| 1 | s.connect() 此方法主动启动TCP服务器连接。 |
通用套接字方法
| Sr.No. | 方法和描述 |
|---|---|
| 1 | s.recv() 此方法接收TCP消息 |
| 2 | s.send() 该方法传输TCP消息 |
| 3 | s.recvfrom() 此方法接收UDP消息 |
| 4 | s.sendto() 该方法发送UDP消息 |
| 5 | s.close() 此方法关闭套接字 |
| 6 | socket.gethostname() 返回主机名。 |
简单的服务器
要编写Internet服务器,我们使用套接字模块中提供的socket函数来创建套接字对象。 然后使用套接字对象调用其他函数来设置套接字服务器。
现在调用bind(hostname, port)函数为给定主机上的服务指定port 。
接下来,调用返回对象的accept方法。 此方法等待,直到客户端连接到您指定的端口,然后返回表示与该客户端的连接的connection对象。
#!/usr/bin/python # This is server.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.bind((host, port)) # Bind to the port
s.listen(5) # Now wait for client connection.
while True:
c, addr = s.accept() # Establish connection with client.
print 'Got connection from', addr
c.send('Thank you for connecting')
c.close() # Close the connection
一个简单的客户
让我们编写一个非常简单的客户端程序,它打开与给定端口12345和给定主机的连接。 使用Python的socket模块函数创建套接字客户端非常简单。
socket.connect(hosname, port )打开与port上hostname的TCP连接。 打开套接字后,可以像任何IO对象一样从中读取。 完成后,请记得关闭它,就像关闭文件一样。
以下代码是一个非常简单的客户端,它连接到给定的主机和端口,从套接字读取任何可用数据,然后退出 -
#!/usr/bin/python # This is client.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.connect((host, port))
print s.recv(1024)
s.close # Close the socket when done
现在在后台运行此server.py,然后在client.py上运行以查看结果。
# Following would start a server in background.
$ python server.py &
# Once server is started run client as follows:
$ python client.py
这将产生以下结果 -
Got connection from ('127.0.0.1', 48437)
Thank you for connecting
Python Internet modules
Python网络/ Internet编程中一些重要模块的列表。
| 协议 | 常用功能 | 港口号 | Python模块 |
|---|---|---|---|
| HTTP | 网页 | 80 | httplib, urllib, xmlrpclib |
| NNTP | Usenet news | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送电子邮件 | 25 | smtplib |
| POP3 | 获取电子邮件 | 110 | poplib |
| IMAP4 | 获取电子邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 文件转移 | 70 | gopherlib, urllib |
请检查上面提到的所有库以使用FTP,SMTP,POP和IMAP协议。
进一步的阅读 (Further Readings)
这是Socket编程的快速入门。 这是一个广泛的主题。 建议通过以下链接查找更多详细信息 -
Python - Sending Email using SMTP
简单邮件传输协议(SMTP)是一种协议,用于处理在邮件服务器之间发送电子邮件和路由电子邮件。
Python提供了smtplib模块,该模块定义了一个SMTP客户端会话对象,可用于通过SMTP或ESMTP侦听器守护程序将邮件发送到任何Internet计算机。
以下是创建一个SMTP对象的简单语法,稍后可用于发送电子邮件 -
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
以下是参数的详细信息 -
host - 这是运行SMTP服务器的主机。 您可以指定主机的IP地址或域名,例如iowiki.com。 这是可选参数。
port - 如果要提供host参数,则需要指定SMTP服务器正在侦听的端口。 通常这个端口是25。
local_hostname - 如果您的SMTP服务器在本地计算机上运行,则您可以在此选项中指定localhost 。
SMTP对象具有名为sendmail的实例方法,该方法通常用于执行邮件发送的工作。 它需要三个参数 -
sender - 包含发件人地址的字符串。
receivers - 字符串列表,每个接收者一个。
message - 作为字符串格式的消息,如各种RFC中指定的那样。
例子 (Example)
这是使用Python脚本发送一封电子邮件的简单方法。 尝试一次 -
#!/usr/bin/python
import smtplib
sender = 'from@fromdomain.com'
receivers = ['to@todomain.com']
message = """From: From Person <from@fromdomain.com>
To: To Person <to@todomain.com>
Subject: SMTP e-mail test
This is a test e-mail message.
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"
在这里,您已使用三重引号在消息中放置了基本电子邮件,注意正确格式化标题。 电子邮件需要“ From ,“ To ”和“ Subject标题,并使用空行与电子邮件正文分隔。
要发送邮件,请使用smtpObj连接到本地计算机上的SMTP服务器,然后使用sendmail方法以及消息,发件人地址和目标地址作为参数(即使from和to地址在e内)邮件本身,这些并不总是用于路由邮件)。
如果未在本地计算机上运行SMTP服务器,则可以使用smtplib客户端与远程SMTP服务器进行通信。 除非您使用的是Webmail服务(例如Hotmail或Yahoo! Mail),否则您的电子邮件提供商必须为您提供可以提供的外发邮件服务器详细信息,如下所示 -
smtplib.SMTP('mail.your-domain.com', 25)
使用Python发送HTML电子邮件
使用Python发送文本消息时,所有内容都被视为简单文本。 即使您在文本消息中包含HTML标记,它也会显示为简单文本,HTML标记将不会根据HTML语法进行格式化。 但Python提供了将HTML消息作为实际HTML消息发送的选项。
发送电子邮件时,您可以指定Mime版本,内容类型和字符集以发送HTML电子邮件。
例子 (Example)
以下是将HTML内容作为电子邮件发送的示例。 尝试一次 -
#!/usr/bin/python
import smtplib
message = """From: From Person <from@fromdomain.com>
To: To Person <to@todomain.com>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP HTML e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"
将附件作为电子邮件发送
要发送包含混合内容的电子邮件,需要将Content-type标头设置为multipart/mixed 。 然后,可以在boundaries内指定文本和附件部分。
边界以两个连字符开头,后跟唯一编号,该编号不能出现在电子邮件的邮件部分中。 表示电子邮件最后部分的最后边界也必须以两个连字符结尾。
附加文件应使用pack("m")函数进行编码,以便在传输之前进行base64编码。
例子 (Example)
以下是示例,它将文件/tmp/test.txt作为附件发送。 尝试一次 -
#!/usr/bin/python
import smtplib
import base64
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
fo = open(filename, "rb")
filecontent = fo.read()
encodedcontent = base64.b64encode(filecontent) # base64
sender = 'webmaster@tutorialpoint.com'
reciever = 'amrood.admin@gmail.com'
marker = "AUNIQUEMARKER"
body ="""
This is a test email to send an attachement.
"""
# Define the main headers.
part1 = """From: From Person <me@fromdomain.net>
To: To Person <amrood.admin@gmail.com>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary=%s
--%s
""" % (marker, marker)
# Define the message action
part2 = """Content-Type: text/plain
Content-Transfer-Encoding:8bit
%s
--%s
""" % (body,marker)
# Define the attachment section
part3 = """Content-Type: multipart/mixed; name=\"%s\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename=%s
%s
--%s--
""" %(filename, filename, encodedcontent, marker)
message = part1 + part2 + part3
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, reciever, message)
print "Successfully sent email"
except Exception:
print "Error: unable to send email"
Python - Multithreaded Programming
运行多个线程类似于同时运行多个不同的程序,但具有以下好处 -
进程中的多个线程与主线程共享相同的数据空间,因此可以比它们是单独的进程更容易地共享信息或相互通信。
线程有时称为轻量级进程,它们不需要太多内存开销; 它们比流程便宜。
线程有一个开头,一个执行序列和一个结论。 它有一个指令指针,可以跟踪当前运行的上下文。
它可以被抢占(中断)
当其他线程正在运行时,它可以暂时被搁置(也称为休眠) - 这称为让步。
开始一个新线程
要生成另一个线程,您需要调用thread模块中可用的以下方法 -
thread.start_new_thread ( function, args[, kwargs] )
此方法调用可以快速有效地在Linux和Windows中创建新线程。
方法调用立即返回,子线程启动并使用传递的args列表调用函数。 当函数返回时,线程终止。
在这里, args是一个参数元组; 使用空元组来调用函数而不传递任何参数。 kwargs是关键字参数的可选字典。
例子 (Example)
#!/usr/bin/python
import thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print "%s: %s" % ( threadName, time.ctime(time.time()) )
# Create two threads as follows
try:
thread.start_new_thread( print_time, ("Thread-1", 2, ) )
thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print "Error: unable to start thread"
while 1:
pass
执行上述代码时,会产生以下结果 -
Thread-1: Thu Jan 22 15:42:17 2009
Thread-1: Thu Jan 22 15:42:19 2009
Thread-2: Thu Jan 22 15:42:19 2009
Thread-1: Thu Jan 22 15:42:21 2009
Thread-2: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:25 2009
Thread-2: Thu Jan 22 15:42:27 2009
Thread-2: Thu Jan 22 15:42:31 2009
Thread-2: Thu Jan 22 15:42:35 2009
虽然它对于低级线程非常有效,但与新的线程模块相比, thread模块非常有限。
Threading模块
Python 2.4中包含的较新的线程模块为线程提供了比前一节中讨论的线程模块更强大,更高级的支持。
threading模块公开了threading模块的所有方法,并提供了一些额外的方法 -
threading.activeCount() - 返回活动的线程对象数。
threading.currentThread() - 返回调用者线程控件中的线程对象数。
threading.enumerate() - 返回当前活动的所有线程对象的列表。
除了这些方法之外,threading模块还有Thread类来实现线程。 Thread类提供的方法如下 -
run() - run()方法是线程的入口点。
start() - start()方法通过调用run方法启动一个线程。
join([time]) - join()等待线程终止。
isAlive() - isAlive()方法检查线程是否仍在执行。
getName() - getName()方法返回线程的名称。
setName() - setName()方法设置线程的名称。
使用Threading模块创建线程
要使用线程模块实现新线程,您必须执行以下操作 -
定义Thread类的新子类。
重写__init__(self [,args])方法以添加其他参数。
然后,重写run(self [,args])方法以实现线程在启动时应该执行的操作。
一旦创建了新的Thread子类,就可以创建它的一个实例,然后通过调用start()启动一个新线程, start()又调用run()方法。
例子 (Example)
#!/usr/bin/python
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
print_time(self.name, self.counter, 5)
print "Exiting " + self.name
def print_time(threadName, counter, delay):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
print "Exiting Main Thread"
执行上述代码时,会产生以下结果 -
Starting Thread-1
Starting Thread-2
Exiting Main Thread
Thread-1: Thu Mar 21 09:10:03 2013
Thread-1: Thu Mar 21 09:10:04 2013
Thread-2: Thu Mar 21 09:10:04 2013
Thread-1: Thu Mar 21 09:10:05 2013
Thread-1: Thu Mar 21 09:10:06 2013
Thread-2: Thu Mar 21 09:10:06 2013
Thread-1: Thu Mar 21 09:10:07 2013
Exiting Thread-1
Thread-2: Thu Mar 21 09:10:08 2013
Thread-2: Thu Mar 21 09:10:10 2013
Thread-2: Thu Mar 21 09:10:12 2013
Exiting Thread-2
同步线程
Python提供的线程模块包含一个易于实现的锁定机制,允许您同步线程。 通过调用Lock()方法创建一个新锁,该方法返回新锁。
新锁对象的acquire(blocking)方法用于强制线程同步运行。 可选的blocking参数使您可以控制线程是否等待获取锁定。
如果blocking设置为0,则如果无法获取锁定,则线程立即返回0值,如果获取了锁定,则返回1。 如果阻塞设置为1,则线程阻塞并等待锁被释放。
新锁对象的release()方法用于在不再需要时释放锁。
例子 (Example)
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"
执行上述代码时,会产生以下结果 -
Starting Thread-1
Starting Thread-2
Thread-1: Thu Mar 21 09:11:28 2013
Thread-1: Thu Mar 21 09:11:29 2013
Thread-1: Thu Mar 21 09:11:30 2013
Thread-2: Thu Mar 21 09:11:32 2013
Thread-2: Thu Mar 21 09:11:34 2013
Thread-2: Thu Mar 21 09:11:36 2013
Exiting Main Thread
多线程优先级队列
Queue模块允许您创建一个可以容纳特定数量项目的新队列对象。 有以下方法来控制队列 -
get() - get()从队列中删除并返回一个项目。
put() - put将项添加到队列中。
qsize() - qsize()返回当前队列中的项目数。
empty() - 如果队列为空,则empty()返回True; 否则,错误。
full() - 如果队列已满,则full()返回True; 否则,错误。
例子 (Example)
#!/usr/bin/python
import Queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print "Starting " + self.name
process_data(self.name, self.q)
print "Exiting " + self.name
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print "%s processing %s" % (threadName, data)
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = Queue.Queue(10)
threads = []
threadID = 1
# Create new threads
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# Fill the queue
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# Wait for queue to empty
while not workQueue.empty():
pass
# Notify threads it's time to exit
exitFlag = 1
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"
执行上述代码时,会产生以下结果 -
Starting Thread-1
Starting Thread-2
Starting Thread-3
Thread-1 processing One
Thread-2 processing Two
Thread-3 processing Three
Thread-1 processing Four
Thread-2 processing Five
Exiting Thread-3
Exiting Thread-1
Exiting Thread-2
Exiting Main Thread
Python - XML Processing
XML是一种可移植的开源语言,它允许程序员开发可由其他应用程序读取的应用程序,而不管操作系统和/或开发语言如何。
什么是XML?
可扩展标记语言(XML)是一种非常类似于HTML或SGML的标记语言。 这是万维网联盟推荐的,可作为开放标准提供。
XML对于跟踪中小数据量而非需要基于SQL的主干非常有用。
XML分析器架构和API
Python标准库提供了一组最小但有用的接口来处理XML。
XML数据的两个最基本和最广泛使用的API是SAX和DOM接口。
Simple API for XML (SAX) - 在这里,您为感兴趣的事件注册回调,然后让解析器继续处理文档。 当文档很大或存在内存限制时,这很有用,它会在从磁盘读取文件时解析文件,并且整个文件永远不会存储在内存中。
Document Object Model (DOM) API - 这是一个万维网联盟建议,其中整个文件被读入内存并以分层(基于树)的形式存储,以表示XML文档的所有功能。
在使用大文件时,SAX显然无法像DOM一样快地处理信息。 另一方面,独占使用DOM可以真正杀死你的资源,特别是如果用在很多小文件上。
SAX是只读的,而DOM允许更改XML文件。 由于这两种不同的API在字面上相互补充,因此没有理由不将它们用于大型项目。
对于我们所有的XML代码示例,让我们使用一个简单的XML文件movies.xml作为输入 -
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>
使用SAX API解析XML
SAX是事件驱动的XML解析的标准接口。 使用SAX解析XML通常需要通过继承xml.sax.ContentHandler来创建自己的ContentHandler。
您的ContentHandler处理您的XML风格的特定标记和属性。 ContentHandler对象提供了处理各种解析事件的方法。 它拥有的解析器在解析XML文件时调用ContentHandler方法。
方法startDocument和endDocument在XML文件的开头和结尾调用。 方法characters(text)通过参数文本传递XML文件的字符数据。
在每个元素的开头和结尾调用ContentHandler。 如果解析器未处于命名空间模式,则调用方法startElement(tag, attributes)和endElement(tag) ; 否则,调用相应的方法startElementNS和endElementNS 。 这里,tag是元素标记,属性是Attributes对象。
在继续之前,还有其他重要的方法需要了解 -
make_parser方法
以下方法创建一个新的解析器对象并返回它。 创建的解析器对象将是系统找到的第一个解析器类型。
xml.sax.make_parser( [parser_list] )
以下是参数的详细信息 -
parser_list - 可选参数,由要使用的解析器列表组成,必须全部实现make_parser方法。
parse方法
以下方法创建SAX解析器并使用它来解析文档。
xml.sax.parse( xmlfile, contenthandler[, errorhandler])
以下是参数的详细信息 -
xmlfile - 这是要读取的XML文件的名称。
contenthandler - 必须是ContentHandler对象。
errorhandler - 如果指定,errorhandler必须是SAX ErrorHandler对象。
parseString方法
还有一种方法可以创建SAX解析器并解析指定的XML string 。
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])
以下是参数的详细信息 -
xmlstring - 这是要读取的XML字符串的名称。
contenthandler - 必须是ContentHandler对象。
errorhandler - 如果指定,errorhandler必须是SAX ErrorHandler对象。
例子 (Example)
#!/usr/bin/python
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print "*****Movie*****"
title = attributes["title"]
print "Title:", title
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print "Type:", self.type
elif self.CurrentData == "format":
print "Format:", self.format
elif self.CurrentData == "year":
print "Year:", self.year
elif self.CurrentData == "rating":
print "Rating:", self.rating
elif self.CurrentData == "stars":
print "Stars:", self.stars
elif self.CurrentData == "description":
print "Description:", self.description
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")
这将产生以下结果 -
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredom
有关SAX API文档的完整详细信息,请参阅标准Python SAX API 。
使用DOM API解析XML
文档对象模型(“DOM”)是来自万维网联盟(W3C)的跨语言API,用于访问和修改XML文档。
DOM对于随机访问应用程序非常有用。 SAX仅允许您一次查看文档的一位。 如果您正在查看一个SAX元素,则无法访问另一个SAX元素。
这是使用xml.dom模块快速加载XML文档和创建minidom对象的最简单方法。 minidom对象提供了一种简单的解析器方法,可以从XML文件中快速创建DOM树。
示例短语调用minidom对象的parse(file [,parser])函数,以将文件指定的XML文件解析为DOM树对象。
#!/usr/bin/python
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print "Root element : %s" % collection.getAttribute("shelf")
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print "*****Movie*****"
if movie.hasAttribute("title"):
print "Title: %s" % movie.getAttribute("title")
type = movie.getElementsByTagName('type')[0]
print "Type: %s" % type.childNodes[0].data
format = movie.getElementsByTagName('format')[0]
print "Format: %s" % format.childNodes[0].data
rating = movie.getElementsByTagName('rating')[0]
print "Rating: %s" % rating.childNodes[0].data
description = movie.getElementsByTagName('description')[0]
print "Description: %s" % description.childNodes[0].data
这会产生以下结果 -
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredom
有关DOM API文档的完整详细信息,请参阅标准Python DOM API 。
Python - GUI Programming (Tkinter)
Python提供了各种用于开发图形用户界面(GUI)的选项。 最重要的是下面列出的。
Tkinter - Tkinter是Python附带的Tk GUI工具包的Python接口。 我们将在本章中看到这个选项。
wxPython - 这是wxWindows http://wxpython.org的开源Python接口。
JPython - JPython是Java的Python端口,它使Python脚本可以无缝访问本地机器上的Java类库http://www.jython.org 。
还有许多其他可用的接口,您可以在网上找到它们。
Tkinter编程
Tkinter是Python的标准GUI库。 Python与Tkinter结合使用时,可以快速轻松地创建GUI应用程序。 Tkinter为Tk GUI工具包提供了强大的面向对象的接口。
使用Tkinter创建GUI应用程序是一项简单的任务。 您需要做的就是执行以下步骤 -
导入Tkinter模块。
创建GUI应用程序主窗口。
将一个或多个上述小部件添加到GUI应用程序。
输入主事件循环以对用户触发的每个事件采取操作。
例子 (Example)
#!/usr/bin/python
import tkinter
top = tkinter.Tk()
# Code to add widgets will go here...
top.mainloop()
这将创建一个以下窗口 -
Tkinter小部件
Tkinter提供各种控件,例如GUI应用程序中使用的按钮,标签和文本框。 这些控件通常称为小部件。
Tkinter目前有15种类型的小部件。 我们提供这些小部件以及下表中的简要说明 -
| Sr.No. | 操作符和说明 |
|---|---|
| 1 | Button Button小部件用于显示应用程序中的按钮。 |
| 2 | Canvas Canvas小部件用于在应用程序中绘制线条,椭圆,多边形和矩形等形状。 |
| 3 | Checkbutton Checkbutton小部件用于显示多个选项作为复选框。 用户可以一次选择多个选项。 |
| 4 | Entry Entry小部件用于显示单行文本字段,用于接受来自用户的值。 |
| 5 | Frame Frame小部件用作容器小部件来组织其他小部件。 |
| 6 | Label Label小部件用于为其他小部件提供单行标题。 它还可以包含图像。 |
| 7 | Listbox 列表框小部件用于向用户提供选项列表。 |
| 8 | Menubutton Menubutton小部件用于显示应用程序中的菜单。 |
| 9 | Menu Menu小部件用于向用户提供各种命令。 这些命令包含在Menubutton中。 |
| 10 | Message Message小部件用于显示多行文本字段,以接受用户的值。 |
| 11 | Radiobutton Radiobutton小部件用于将多个选项显示为单选按钮。 用户一次只能选择一个选项。 |
| 12 | Scale Scale小部件用于提供滑块小部件。 |
| 13 | Scrollbar Scrollbar小部件用于向各种小部件(例如列表框)添加滚动功能。 |
| 14 | Text “文本”小组件用于以多行显示文本。 |
| 15 | Toplevel Toplevel小部件用于提供单独的窗口容器。 |
| 16 | Spinbox Spinbox小部件是标准Tkinter Entry小部件的变体,可用于从固定数量的值中进行选择。 |
| 17 | PanedWindow PanedWindow是一个容器窗口小部件,可以包含水平或垂直排列的任意数量的窗格。 |
| 18 | LabelFrame labelframe是一个简单的容器小部件。 其主要目的是充当复杂窗口布局的间隔物或容器。 |
| 19 | tkMessageBox 此模块用于在应用程序中显示消息框。 |
让我们详细研究这些小部件 -
标准属性 (Standard attributes)
让我们看一下它们的一些常见属性,例如大小,颜色和字体是如何指定的。
让我们简要地研究它们 -
几何管理
所有Tkinter小部件都可以访问特定的几何管理方法,这些方法的目的是在整个父窗口小部件区域中组织窗口小部件。 Tkinter公开以下几何管理器类:pack,grid和place。
pack()方法 - 此几何管理器在将它们放入父窗口小部件之前以块为单位组织窗口小部件。
grid()方法 - 此几何管理器在父窗口小部件中以类似表的结构组织窗口小部件。
place()方法 - 此几何管理器通过将窗口小部件放置在父窗口小部件中的特定位置来组织窗口小部件。
让我们简单地研究几何管理方法 -
Python - Extension Programming with C
使用任何编译语言(如C,C ++或Java)编写的任何代码都可以集成或导入到另一个Python脚本中。 此代码被视为“扩展”。
Python扩展模块只不过是一个普通的C库。 在Unix机器上,这些库通常以.so结尾(对于共享对象)。 在Windows机器上,您通常会看到.dll (用于动态链接库)。
编写扩展的先决条件
要开始编写扩展,您将需要Python头文件。
在Unix机器上,这通常需要安装特定于开发人员的软件包,例如python2.5-dev 。
Windows用户在使用二进制Python安装程序时将这些标头作为包的一部分。
此外,假设您对C或C ++有很好的了解,可以使用C编程编写任何Python扩展。
首先看一下Python扩展
首次查看Python扩展模块,您需要将代码分为四个部分 -
头文件Python.h 。
要作为模块接口公开的C函数。
映射Python函数开发人员的函数名称的表将它们视为扩展模块中的C函数。
初始化函数。
头文件Python.h
您需要在C源文件中包含Python.h头文件,这样您就可以访问用于将模块挂钩到解释器的内部Python API。
确保在您可能需要的任何其他标头之前包含Python.h。 您需要使用包含要从Python调用的函数的包含。
C 函数
函数的C实现的签名总是采用以下三种形式之一 -
static PyObject *MyFunction( PyObject *self, PyObject *args );
static PyObject *MyFunctionWithKeywords(PyObject *self,
PyObject *args,
PyObject *kw);
static PyObject *MyFunctionWithNoArgs( PyObject *self );
前面的每个声明都返回一个Python对象。 在Python中没有像在C中那样的void函数。如果你不希望函数返回一个值,则返回C的等价于Python的None值。 Python标头定义了一个宏Py_RETURN_NONE,它为我们做了这个。
C函数的名称可以是您喜欢的任何名称,因为它们在扩展模块之外从未见过。 它们被定义为static函数。
您的C函数通常通过将Python模块和函数名称组合在一起来命名,如下所示 -
static PyObject *<i>module_func</i>(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
这是一个名为func的Python函数,位于模块module 。 您将把指向C函数的指针放入源代码中通常出现的模块的方法表中。
方法映射表
此方法表是PyMethodDef结构的简单数组。 那个结构看起来像这样 -
struct PyMethodDef {
char *ml_name;
PyCFunction ml_meth;
int ml_flags;
char *ml_doc;
};
以下是该结构成员的描述 -
ml_name - 这是Python解释器在Python程序中使用时提供的函数的名称。
ml_meth - 这必须是具有前面所述的任何一个签名的函数的地址。
ml_flags - 这告诉解释器ml_meth使用的三个签名中的哪一个。
此标志的值通常为METH_VARARGS。
如果要允许关键字参数进入函数,可以使用METH_KEYWORDS对此标志进行按位OR运算。
这也可以具有METH_NOARGS值,表示您不想接受任何参数。
ml_doc - 这是函数的docstring,如果你不想写一个函数,它可能是NULL。
此表需要使用由适当成员的NULL和0值组成的标记终止。
例子 (Example)
对于上面定义的函数,我们有以下方法映射表 -
static PyMethodDef <i>module</i>_methods[] = {
{ "<i>func</i>", (PyCFunction)<i>module_func</i>, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
初始化函数
扩展模块的最后一部分是初始化函数。 加载模块时,Python解释器会调用此函数。 要求该函数名为init Module ,其中Module是Module的名称。
需要从要构建的库中导出初始化函数。 Python标头定义PyMODINIT_FUNC以包含适用于我们正在编译的特定环境的咒语。 您所要做的就是在定义函数时使用它。
您的C初始化函数通常具有以下整体结构 -
PyMODINIT_FUNC init<i>Module</i>() {
Py_InitModule3(<i>func</i>, <i>module</i>_methods, "docstring...");
}
这是Py_InitModule3函数的描述 -
func - 这是要导出的函数。
module _methods - 这是上面定义的映射表名称。
docstring - 这是您要在扩展程序中提供的评论。
把这一切放在一起看起来如下 -
#include <Python.h>
static PyObject *<i>module_func</i>(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
static PyMethodDef <i>module</i>_methods[] = {
{ "<i>func</i>", (PyCFunction)<i>module_func</i>, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
PyMODINIT_FUNC init<i>Module</i>() {
Py_InitModule3(<i>func</i>, <i>module</i>_methods, "docstring...");
}
例子 (Example)
一个利用上述所有概念的简单例子 -
#include <Python.h>
static PyObject* helloworld(PyObject* self) {
return Py_BuildValue("s", "Hello, Python extensions!!");
}
static char helloworld_docs[] =
"helloworld( ): Any message you want to put here!!\n";
static PyMethodDef helloworld_funcs[] = {
{"helloworld", (PyCFunction)helloworld,
METH_NOARGS, helloworld_docs},
{NULL}
};
void inithelloworld(void) {
Py_InitModule3("helloworld", helloworld_funcs,
"Extension module example!");
}
这里Py_BuildValue函数用于构建Python值。 将以上代码保存在hello.c文件中。 我们将看到如何编译和安装此模块以从Python脚本调用。
构建和安装扩展
distutils包使得以标准方式分发Python模块(纯Python和扩展模块)变得非常容易。 模块以源代码形式分发,并通过通常称为setup.py的设置脚本构建和安装,如下所示。
对于上面的模块,您需要准备以下setup.py脚本 -
from distutils.core import setup, Extension
setup(name='helloworld', version='1.0', \
ext_modules=[Extension('helloworld', ['hello.c'])])
现在,使用以下命令,它将执行所有需要的编译和链接步骤,使用正确的编译器和链接器命令和标志,并将生成的动态库复制到适当的目录中 -
$ python setup.py install
在基于Unix的系统上,您很可能需要以root身份运行此命令才能拥有写入site-packages目录的权限。 这通常不是Windows上的问题。
导入扩展
安装扩展程序后,您将能够在Python脚本中导入并调用该扩展程序,如下所示 -
#!/usr/bin/python
import helloworld
print helloworld.helloworld()
这会产生以下结果 -
Hello, Python extensions!!
传递函数参数
由于您很可能希望定义接受参数的函数,因此可以使用C函数的其他签名之一。 例如,接受一些参数的跟随函数将被定义为这样 -
static PyObject *<i>module_func</i>(PyObject *self, PyObject *args) {
/* Parse args and do something interesting here. */
Py_RETURN_NONE;
}
包含新函数条目的方法表如下所示 -
static PyMethodDef <i>module</i>_methods[] = {
{ "<i>func</i>", (PyCFunction)<i>module_func</i>, METH_NOARGS, NULL },
{ "<i>func</i>", <i>module_func</i>, METH_VARARGS, NULL },
{ NULL, NULL, 0, NULL }
};
您可以使用API PyArg_ParseTuple函数从传递给C函数的一个PyObject指针中提取参数。
PyArg_ParseTuple的第一个参数是args参数。 这是您要parsing的对象。 第二个参数是一个格式字符串,用于描述您希望它们出现的参数。 每个参数由格式字符串中的一个或多个字符表示,如下所示。
static PyObject *<i>module_func</i>(PyObject *self, PyObject *args) {
int i;
double d;
char *s;
if (!PyArg_ParseTuple(args, "ids", &i, &d, &s)) {
return NULL;
}
/* Do something interesting here. */
Py_RETURN_NONE;
}
编译模块的新版本并导入它使您可以使用任意类型的任意数量的参数调用新函数 -
module.func(1, s="three", d=2.0)
module.func(i=1, d=2.0, s="three")
module.func(s="three", d=2.0, i=1)
您可能会想出更多变化。
PyArg_ParseTuple函数
这是PyArg_ParseTuple函数的标准签名 -
int PyArg_ParseTuple(PyObject* tuple,char* format,...)
此函数返回0表示错误,值不等于0表示成功。 元组是PyObject *,它是C函数的第二个参数。 这里的format是一个描述强制和可选参数的C字符串。
以下是PyArg_ParseTuple函数的格式代码列表 -
| 码 | C型 | 含义 |
|---|---|---|
| c | char | 长度为1的Python字符串变为C字符。 |
| d | double | Python float变为C double。 |
| f | float | Python float变为C float。 |
| i | int | Python int成为C int。 |
| l | long | Python int变为C long。 |
| L | long long | Python int变为C long long |
| O | PyObject* | 获取对Python参数的非NULL借用引用。 |
| s | char* | Python字符串没有嵌入空值到C char *。 |
| s# | char*+int | 任何Python字符串到C地址和长度。 |
| t# | char*+int | 只读单段缓冲区到C地址和长度。 |
| u | Py_UNICODE* | 没有嵌入空值的Python Unicode到C语言 |
| u# | Py_UNICODE*+int | 任何Python Unicode C地址和长度。 |
| w# | char*+int | 读/写单段缓冲区到C地址和长度。 |
| z | char* | 与s一样,也接受None(将C char *设置为NULL)。 |
| z# | char*+int | 与s#一样,也接受None(将C char *设置为NULL)。 |
| (...) | 按照 ... | Python序列被视为每个项目的一个参数。 |
| | | 以下参数是可选的。 | |
| : | 格式化结束,后跟错误消息的函数名称。 | |
| ; | 格式化结束,然后是整个错误消息文本。 |
回归价值观
Py_BuildValue接受格式字符串,就像PyArg_ParseTuple一样。 您可以传递实际值,而不是传递您正在构建的值的地址。 这是一个展示如何实现添加功能的示例 -
static PyObject *foo_add(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("i", a + b);
}
如果在Python中实现它会是什么样子 -
def add(a, b):
return (a + b)
您可以按如下方式从函数中返回两个值,这将使用Python中的列表进行检查。
static PyObject *foo_add_subtract(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("ii", a + b, a - b);
}
如果在Python中实现它会是什么样子 -
def add_subtract(a, b):
return (a + b, a - b)
Py_BuildValue函数
这是Py_BuildValue函数的标准签名 -
PyObject* Py_BuildValue(char* format,...)
这里的format是一个C字符串,描述了要构建的Python对象。 Py_BuildValue的以下参数是Py_BuildValue构建结果的C值。 PyObject*结果是一个新的引用。
下表列出了常用的代码字符串,其中零个或多个连接成字符串格式。
| 码 | C型 | 含义 |
|---|---|---|
| c | char | AC char成为长度为1的Python字符串。 |
| d | double | AC double成为Python float。 |
| f | float | AC float成为Python float。 |
| i | int | AC int成为Python int。 |
| l | long | AC long成为Python int。 |
| N | PyObject* | 传递Python对象并窃取引用。 |
| O | PyObject* | 传递一个Python对象并正常INCREF它。 |
| O& | convert+void* | Arbitrary conversion |
| s | char* | C 0终止char *到Python字符串,或NULL到None。 |
| s# | char*+int | C char *和Python字符串的长度,或NULL到None。 |
| u | Py_UNICODE* | C宽,以null结尾的字符串到Python Unicode,或NULL到None。 |
| u# | Py_UNICODE*+int | C-wide字符串和长度为Python Unicode,或NULL为None。 |
| w# | char*+int | 读/写单段缓冲区到C地址和长度。 |
| z | char* | 与s一样,也接受None(将C char *设置为NULL)。 |
| z# | char*+int | 与s#一样,也接受None(将C char *设置为NULL)。 |
| (...) | 按照 ... | 从C值构建Python元组。 |
| [...] | 按照 ... | 从C值构建Python列表。 |
| {...} | 按照 ... | 从C值构建Python字典,交替键和值。 |
代码{...}从偶数个C值构建字典,交替键和值。 例如,Py_BuildValue(“{issi}”,23,“zig”,“zag”,42)返回一个字典,如Python的{23:'zig','zag':42}。
