Lucene - 快速指南
Lucene - Overview
Lucene是一个简单但功能强大的基于Java的Search库。 它可以在任何应用程序中用于向其添加搜索功能。 Lucene是一个开源项目。 它是可扩展的。 这个高性能库用于索引和搜索几乎任何类型的文本。 Lucene库提供任何搜索应用程序所需的核心操作。 索引和搜索。
Search Search的工作原理如何?
搜索应用程序执行以下所有或一些操作 -
| 步 | 标题 | 描述 |
|---|---|---|
| 1 | Acquire Raw Content | 任何搜索应用程序的第一步是收集要在其上进行搜索应用程序的目标内容。 |
| 2 | Build the document | 下一步是从原始内容构建文档,搜索应用程序可以轻松理解和解释这些文档。 |
| 3 | Analyze the document | 在索引过程开始之前,将分析文档以确定文本的哪一部分是要编入索引的候选者。 此过程是分析文档的位置。 |
| 4 | Indexing the document | 构建和分析文档后,下一步是索引它们,以便可以根据某些键而不是文档的整个内容检索此文档。 索引过程类似于书籍末尾的索引,其中显示常用词及其页码,以便可以快速跟踪这些词,而不是搜索完整的书。 |
| 5 | User Interface for Search | 一旦索引数据库准备就绪,应用程序就可以进行任何搜索。 为了便于用户进行搜索,应用程序必须向用户提供用户可以输入文本并开始搜索过程a mean或a user interface 。 |
| 6 | Build Query | 一旦用户发出搜索文本的请求,应用程序应使用该文本准备Query对象,该对象可用于查询索引数据库以获取相关详细信息。 |
| 7 | Search Query | 然后使用查询对象检查索引数据库以获取相关详细信息和内容文档。 |
| 8 | Render Results | 收到结果后,应用程序应决定如何使用用户界面向用户显示结果。 初看时会显示多少信息,依此类推。 |
除了这些基本操作之外,搜索应用程序还可以提供administration user interface并帮助应用程序的管理员基于用户配置文件控制搜索级别。 搜索结果分析是任何搜索应用程序的另一个重要和高级方面。
Lucene在搜索应用程序中的角色
Lucene在上述步骤2到步骤7中扮演角色,并提供了执行所需操作的类。 简而言之,Lucene是任何搜索应用程序的核心,并提供与索引和搜索相关的重要操作。 获取内容并显示结果留给应用程序部分处理。
在下一章中,我们将使用Lucene Search库执行一个简单的搜索应用程序。
Lucene - Environment Setup
本教程将指导您如何准备开发环境以开始使用Spring Framework。 本教程还将教您如何在设置Spring Framework之前在计算机上设置JDK,Tomcat和Eclipse -
第1步 - Java Development Kit(JDK)安装程序
您可以从Oracle的Java站点下载最新版本的SDK: Java SE Downloads 。 您将找到有关在下载文件中安装JDK的说明; 按照给定的说明安装和配置设置。 最后设置PATH和JAVA_HOME环境变量来引用包含Java和javac的目录,通常分别是java_install_dir/bin和java_install_dir。
如果您运行的是Windows并在C:\_ jdk1.6.0_15中安装了JDK,则必须将以下行放在C:\autoexec.bat文件中。
set PATH = C:\jdk1.6.0_15\bin;%PATH%
set JAVA_HOME = C:\jdk1.6.0_15
或者,在Windows NT/2000/XP上,您也可以右键单击“ My Computer ,选择“ Properties ,然后选择“ Advanced ,再选择“ Environment Variables 。 然后,您将更新PATH值并按OK按钮。
在Unix(Solaris,Linux等)上,如果SDK安装在/usr/local/jdk1.6.0_15中并且您使用C shell,则应将以下内容放入.cshrc文件中。
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATH
setenv JAVA_HOME /usr/local/jdk1.6.0_15
或者,如果您使用Borland JBuilder,Eclipse,IntelliJ IDEA或Sun ONE Studio等Integrated Development Environment (IDE) ,请编译并运行一个简单程序以确认IDE知道您在何处安装Java,否则请按照IDE的文档。
第2步 - Eclipse IDE安装程序
本教程中的所有示例都是使用Eclipse IDE编写的。 所以我建议你应该在你的机器上安装最新版本的Eclipse。
要安装Eclipse IDE,请从https://www.eclipse.org/downloads/下载最新的Eclipse二进制文件。 下载安装后,将二进制分发包解压到一个方便的位置。 例如,在C:\eclipse on windows,或/usr/local/eclipse on Linux/Unix ,最后适当地设置PATH变量。
可以通过在Windows机器上执行以下命令来启动Eclipse,或者只需双击eclipse.exe
%C:\eclipse\eclipse.exe
可以通过在Unix(Solaris,Linux等)机器上执行以下命令来启动Eclipse -
$/usr/local/eclipse/eclipse
成功启动后,它应显示以下结果 -
第3步 - 设置Lucene框架库
如果启动成功,那么您可以继续设置Lucene框架。 以下是在您的计算机上下载和安装框架的简单步骤。
https://archive.apache.org/dist/lucene/java/3.6.2/
选择是否要在Windows或Unix上安装Lucene,然后继续下一步下载Windows的.zip文件和Unix的.tz文件。
从https://archive.apache.org/dist/lucene/java/下载合适的Lucene框架二进制版本。
在编写本教程时,我在我的Windows机器上下载了lucene-3.6.2.zip,当你解压缩下载的文件时,它将在C:\lucene-3.6.2中为你提供目录结构,如下所示。

您将在目录C:\lucene-3.6.2找到所有Lucene库。 确保正确设置此目录上的CLASSPATH变量,否则在运行应用程序时将遇到问题。 如果您使用的是Eclipse,则不需要设置CLASSPATH,因为所有设置都将通过Eclipse完成。
完成最后一步后,您就可以继续学习第一个Lucene示例,您将在下一章中看到它。
Lucene - First Application
在本章中,我们将学习Lucene Framework的实际编程。 在开始使用Lucene框架编写第一个示例之前,必须确保已按照Lucene - Environment Setup教程中的说明正确设置了Lucene环境。 建议您具备Eclipse IDE的工作知识。
现在让我们开始编写一个简单的搜索应用程序,它将打印找到的搜索结果的数量。 我们还将看到在此过程中创建的索引列表。
第1步 - 创建Java项目
第一步是使用Eclipse IDE创建一个简单的Java项目。 按照File 》 New -》 Project选项,最后从向导列表中选择Java Project向导。 现在使用向导窗口将项目命名为LuceneFirstApplication ,如下所示 -
成功创建项目后,您将在Project Explorer拥有以下内容 -
第2步 - 添加所需的库
现在让我们在项目中添加Lucene核心框架库。 为此,右键单击项目名称LuceneFirstApplication ,然后按照上下文菜单中的以下选项进行操作: Build Path -》 Configure Build Path以显示“Java构建路径”窗口,如下所示 -
现在使用Libraries选项卡下的Add External JARs按钮从Lucene安装目录添加以下核心JAR -
- lucene-core-3.6.2
第3步 - 创建源文件
现在让我们在LuceneFirstApplication项目下创建实际的源文件。 首先,我们需要创建一个名为com.iowiki.lucene.的包com.iowiki.lucene. 要执行此操作,请右键单击package explorer部分中的src,然后按照选项: New -》 Package 。
接下来,我们将在com.iowiki.lucene包下创建LuceneTester.java和其他java类。
LuceneConstants.java
此类用于提供跨示例应用程序使用的各种常量。
package com.iowiki.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此类用作.txt file筛选器。
package com.iowiki.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
此类用于索引原始数据,以便我们可以使用Lucene库对其进行搜索。
package com.iowiki.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}
Searcher.java
此类用于搜索由Indexer创建的索引以搜索所请求的内容。
package com.iowiki.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
该类用于测试lucene库的索引和搜索功能。
package com.iowiki.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
第4步 - 创建数据和索引目录
我们使用了来自record1.txt的10个文本文件到包含学生姓名和其他详细信息的record10.txt,并将它们放在目录E:\Lucene\Data 。 测试数据 。 索引目录路径应创建为E:\Lucene\Index 。 运行此程序后,您可以看到在该文件夹中创建的索引文件列表。
第5步 - 运行程序
完成源,原始数据,数据目录和索引目录的创建后,就可以编译和运行程序了。 为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用Eclipse IDE中提供的Run选项或使用Ctrl + F11编译并运行LuceneTester应用程序。 如果应用程序成功运行,它将在Eclipse IDE的控制台中打印以下消息 -
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:\Lucene\Data\record4.txt
成功运行程序后,您的index directory中将包含以下内容 -
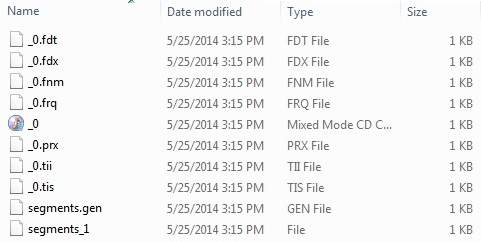
Lucene - Indexing Classes
索引过程是Lucene提供的核心功能之一。 下图说明了索引过程和类的使用。 IndexWriter是索引过程中最重要和最核心的组件。
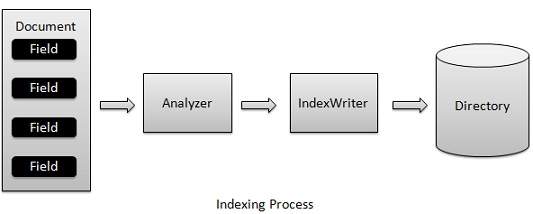
我们将包含Field(s) Document(s)添加到IndexWriter,它使用Analyzer分析Document(s) ,然后根据需要创建/打开/编辑索引,并在Directory存储/更新它们。 IndexWriter用于更新或创建索引。 它不用于读取索引。
索引类
以下是索引过程中常用类的列表。
| S.No. | 类和描述 |
|---|---|
| 1 | IndexWriter 此类充当核心组件,在索引过程中创建/更新索引。 |
| 2 | Directory 此类表示索引的存储位置。 |
| 3 | Analyzer 该类负责分析文档并从要编制索引的文本中获取标记/单词。 如果没有完成分析,IndexWriter无法创建索引。 |
| 4 | Document 此类表示带有Fields的虚拟文档,其中Field是一个对象,可以包含物理文档的内容,元数据等。 分析器只能理解文档。 |
| 5 | Field 这是索引过程的最低单位或起点。 它表示键值对关系,其中键用于标识要编制索引的值。 让我们假设用于表示文档内容的字段将具有作为“内容”的键,并且该值可以包含文档的部分或全部文本或数字内容。 Lucene只能索引文本或数字内容。 |
Lucene - Searching Classes
搜索过程再次成为Lucene提供的核心功能之一。 它的流程类似于索引过程。 可以使用以下类来进行Lucene的基本搜索,这些类也可以被称为所有与搜索相关的操作的基础类。
搜索类
以下是搜索过程中常用类的列表。
| S.No. | 类和描述 |
|---|---|
| 1 | IndexSearcher 此类充当核心组件,用于读取/搜索索引过程后创建的索引。 它需要指向包含索引的位置的目录实例。 |
| 2 | Term 这个类是最低的搜索单位。 它在索引过程中类似于Field。 |
| 3 | Query Query是一个抽象类,包含各种实用程序方法,是Lucene在搜索过程中使用的所有类型查询的父级。 |
| 4 | TermQuery TermQuery是最常用的查询对象,是Lucene可以使用的许多复杂查询的基础。 |
| 5 | TopDocs TopDocs指向与搜索条件匹配的前N个搜索结果。 它是指向文档的简单指针容器,文档是搜索结果的输出。 |
Lucene - Indexing Process
索引过程是Lucene提供的核心功能之一。 下图说明了索引过程和类的使用。 IndexWriter是索引过程中最重要和最核心的组件。
我们将包含Field(s) Document(s)添加到IndexWriter,它使用Analyzer分析Document,然后根据需要creates/open/edit索引,并在Directory存储/更新它们。 IndexWriter用于更新或创建索引。 它不用于读取索引。
现在,我们将逐步向您展示如何使用基本示例开始理解索引过程。
创建一个文档
创建一个从文本文件中获取lucene文档的方法。
创建各种类型的字段,这些字段是包含键作为名称和值的键值对,作为要编制索引的内容。
设置要分析的字段与否。 在我们的例子中,只分析内容,因为它可以包含搜索操作中不需要的数据,例如a,am,are等。
将新创建的字段添加到文档对象并将其返回给调用方法。
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
创建一个IndexWriter
IndexWriter类充当在索引过程中创建/更新索引的核心组件。 请按照以下步骤创建IndexWriter -
Step 1 - 创建IndexWriter的对象。
Step 2 - 创建一个Lucene目录,该目录应指向要存储索引的位置。
Step 3 - 初始化使用索引目录创建的IndexWriter对象,该目标是具有版本信息和其他必需/可选参数的标准分析器。
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
开始索引过程
以下程序显示了如何启动索引过程 -
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
例子 Example Application
要测试索引过程,我们需要创建一个Lucene应用程序测试。
| 步 | 描述 |
|---|---|
| 1 | 在Lucene - First Application chapter解释,在com.iowiki.lucene包下创建一个名为LuceneFirstApplication的项目。 您还可以使用Lucene - First Application创建的项目Lucene - First Application本章的Lucene - First Application章节来理解索引过程。 |
| 2 | 按照Lucene - First Application章节中的说明创建LuceneConstants.java,TextFileFilter.java和LuceneConstants.java,TextFileFilter.java 。 保持其余文件不变。 |
| 3 | 创建LuceneTester.java ,如下所述。 |
| 4 | 清理并构建应用程序以确保业务逻辑按照要求运行。 |
LuceneConstants.java
此类用于提供跨示例应用程序使用的各种常量。
package com.iowiki.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此类用作.txt文件筛选器。
package com.iowiki.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Indexer.java
此类用于索引原始数据,以便我们可以使用Lucene库对其进行搜索。
package com.iowiki.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}
LuceneTester.java
该类用于测试Lucene库的索引功能。
package com.iowiki.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}
数据和索引目录创建
我们使用了来自record1.txt的10个文本文件到包含学生姓名和其他详细信息的record10.txt,并将它们放在目录E:\Lucene\Data. 测试数据 。 索引目录路径应创建为E:\Lucene\Index 。 运行此程序后,您可以看到在该文件夹中创建的索引文件列表。
运行程序 (Running the Program)
完成源,原始数据,数据目录和索引目录的创建后,您可以继续编译和运行程序。 为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用Eclipse IDE中提供的Run选项或使用Ctrl + F11编译并运行LuceneTester应用程序。 如果您的应用程序成功运行,它将在Eclipse IDE的控制台中打印以下消息 -
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
成功运行程序后,您的index directory −中将包含以下内容index directory −
Lucene - Indexing Operations
在本章中,我们将讨论索引的四个主要操作。 这些操作在不同时间都是有用的,并且在整个软件搜索应用程序中使用。
索引操作
以下是索引过程中常用操作的列表。
| S.No. | 操作和说明 |
|---|---|
| 1 | Add Document 此操作在索引过程的初始阶段用于在新可用内容上创建索引。 |
| 2 | Update Document 此操作用于更新索引以反映更新内容中的更改。 它类似于重新创建索引。 |
| 3 | 删除文件 此操作用于更新索引以排除不需要索引/搜索的文档。 |
| 4 | Field Options 字段选项指定方式或控制字段内容可搜索的方式。 |
Lucene - Search Operation
搜索过程是Lucene提供的核心功能之一。 下图说明了该过程及其用途。 IndexSearcher是搜索过程的核心组件之一。
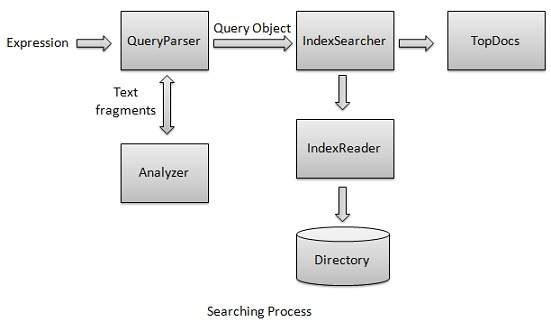
我们首先创建包含indexes ,然后将其传递给IndexSearcher ,后者使用IndexReader打开Directory 。 然后我们使用Term创建一个Query ,并通过将Query传递给搜索器来使用IndexSearcher进行搜索。 IndexSearcher返回一个TopDocs对象,该对象包含搜索详细信息以及作为搜索操作结果的Document文档ID。
我们现在将向您展示一种逐步的方法,并使用一个基本示例帮助您理解索引过程。
创建QueryParser
QueryParser类将用户输入的输入解析为Lucene可理解的格式查询。 请按照以下步骤创建QueryParser -
Step 1 - 创建QueryParser的对象。
Step 2 - 初始化使用标准分析器创建的QueryParser对象,该分析器具有要在其上运行此查询的版本信息和索引名称。
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
创建一个IndexSearcher
IndexSearcher类充当索引过程中创建的搜索器索引的核心组件。 请按照以下步骤创建IndexSearcher -
Step 1 - 创建IndexSearcher的对象。
Step 2 - 创建一个Lucene目录,该目录应指向要存储索引的位置。
Step 3 - 初始化使用索引目录创建的IndexSearcher对象。
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}
进行搜索
按照以下步骤进行搜索 -
Step 1 - 通过QueryParser解析搜索表达式来创建Query对象。
Step 2 - 通过调用IndexSearcher.search()方法进行搜索。
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
获取文档
以下程序显示了如何获取文档。
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
关闭IndexSearcher
以下程序显示如何关闭IndexSearcher。
public void close() throws IOException {
indexSearcher.close();
}
例子 Example Application
让我们创建一个测试Lucene应用程序来测试搜索过程。
| 步 | 描述 |
|---|---|
| 1 | 在Lucene - First Application章节中解释,在com.iowiki.lucene包下创建一个名为LuceneFirstApplication的项目。 您还可以使用Lucene - First Application创建的项目Lucene - First Application本章的Lucene - First Application章节来理解搜索过程。 |
| 2 | 按照Lucene - First Application章节中的说明创建LuceneConstants.java,TextFileFilter.java和Searcher.java 。 保持其余文件不变。 |
| 3 | 创建LuceneTester.java ,如下所述。 |
| 4 | 清理并构建应用程序以确保业务逻辑按照要求运行。 |
LuceneConstants.java
此类用于提供跨示例应用程序使用的各种常量。
package com.iowiki.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此类用作.txt文件筛选器。
package com.iowiki.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
此类用于读取对原始数据所做的索引,并使用Lucene库搜索数据。
package com.iowiki.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
该类用于测试Lucene库的搜索功能。
package com.iowiki.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
数据和索引目录创建
我们使用10个名为record1.txt的文本文件来记录包含学生姓名和其他详细信息的record10.txt,并将它们放在目录E:\Lucene\Data中。 测试数据 。 索引目录路径应创建为E:\Lucene\Index。 在Lucene - Indexing Process一章中运行索引程序后,您可以看到在该文件夹中创建的索引文件列表。
运行程序 (Running the Program)
完成源,原始数据,数据目录,索引目录和索引的创建后,可以继续编译和运行程序。 为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用Eclipse IDE中提供的“运行”选项或使用Ctrl + F11编译并运行LuceneTesterapplication 。 如果您的应用程序成功运行,它将在Eclipse IDE的控制台中打印以下消息 -
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txt
Lucene - Query Programming
我们在前一章Lucene - Search Operation看到,Lucene使用IndexSearcher进行搜索,它使用QueryParser创建的Query对象作为输入。 在本章中,我们将讨论各种类型的Query对象以及以编程方式创建它们的不同方法。 创建不同类型的Query对象可以控制要进行的搜索类型。
考虑一个高级搜索的案例,由许多应用程序提供,其中为用户提供了多个选项来限制搜索结果。 通过Query编程,我们可以很容易地实现同样的目的。
以下是我们将在适当时候讨论的查询类型列表。
| S.No. | 类和描述 |
|---|---|
| 1 | TermQuery 此类充当核心组件,在索引过程中创建/更新索引。 |
| 2 | TermRangeQuery 当要搜索一系列文本术语时使用TermRangeQuery。 |
| 3 | PrefixQuery PrefixQuery用于匹配索引以指定字符串开头的文档。 |
| 4 | BooleanQuery BooleanQuery用于搜索使用AND, OR或NOT运算符进行多次查询的文档。 |
| 5 | PhraseQuery 短语查询用于搜索包含特定术语序列的文档。 |
| 6 | WildCardQuery WildcardQuery用于使用任何字符序列的'*'等通配符搜索文档,? 匹配单个字符。 |
| 7 | FuzzyQuery FuzzyQuery用于使用模糊实现来搜索文档,模糊实现是基于编辑距离算法的近似搜索。 |
| 8 | MatchAllDocsQuery MatchAllDocsQuery顾名思义匹配所有文档。 |
Lucene - Analysis
在前面的一章中,我们已经看到Lucene使用IndexWriter使用Analyzer分析Document(s) ,然后根据需要创建/打开/编辑索引。 在本章中,我们将讨论分析过程中使用的各种类型的Analyzer对象和其他相关对象。 了解Analysis过程以及分析器的工作原理可以让您深入了解Lucene如何为文档编制索引。
以下是我们将在适当时候讨论的对象列表。
| S.No. | 类和描述 |
|---|---|
| 1 | Token 令牌表示文档中的文本或单词,其中包含相关的详细信息,如元数据(位置,起始偏移,结束偏移,标记类型及其位置增量)。 |
| 2 | TokenStream TokenStream是分析过程的输出,它包含一系列标记。 这是一个抽象类。 |
| 3 | Analyzer 这是每种类型的Analyzer的抽象基类。 |
| 4 | WhitespaceAnalyzer 该分析器基于空格分割文档中的文本。 |
| 5 | SimpleAnalyzer 此分析器基于非字母字符拆分文档中的文本,并将文本放在小写中。 |
| 6 | StopAnalyzer 该分析器与SimpleAnalyzer一样工作,并删除常用词,如'a', 'an', 'the',等。 |
| 7 | StandardAnalyzer 这是最复杂的分析器,能够处理名称,电子邮件地址等。它会降低每个令牌的大小,并删除常用的单词和标点符号(如果有的话)。 |
Lucene - Sorting
在本章中,我们将研究Lucene默认提供搜索结果的排序顺序,或者可以根据需要进行操作。
按相关性排序
这是Lucene使用的默认排序模式。 Lucene通过顶部最相关的命中提供结果。
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
按IndexOrder排序
Lucene使用这种排序模式。 这里,索引的第一个文档首先显示在搜索结果中。
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
例子 Example Application
让我们创建一个测试Lucene应用程序来测试排序过程。
| 步 | 描述 |
|---|---|
| 1 | 在Lucene - First Application章节中解释,在com.iowiki.lucene包下创建一个名为LuceneFirstApplication的项目。 您还可以使用Lucene - First Application创建的项目Lucene - First Application本章的Lucene - First Application章节来理解搜索过程。 |
| 2 | 按照Lucene - First Application章节中的说明创建LuceneConstants.java和Searcher.java 。 保持其余文件不变。 |
| 3 | 创建LuceneTester.java ,如下所述。 |
| 4 | 清理并构建应用程序以确保业务逻辑按照要求运行。 |
LuceneConstants.java
此类用于提供跨示例应用程序使用的各种常量。
package com.iowiki.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
Searcher.java
此类用于读取对原始数据所做的索引,并使用Lucene库搜索数据。
package com.iowiki.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory
= FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query)
throws IOException, ParseException {
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public TopDocs search(Query query,Sort sort)
throws IOException, ParseException {
return indexSearcher.search(query,
LuceneConstants.MAX_SEARCH,sort);
}
public void setDefaultFieldSortScoring(boolean doTrackScores,
boolean doMaxScores) {
indexSearcher.setDefaultFieldSortScoring(
doTrackScores,doMaxScores);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
该类用于测试Lucene库的搜索功能。
package com.iowiki.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.sortUsingRelevance("cord3.txt");
tester.sortUsingIndex("cord3.txt");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void sortUsingRelevance(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.RELEVANCE);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
private void sortUsingIndex(String searchQuery)
throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
//create a term to search file name
Term term = new Term(LuceneConstants.FILE_NAME, searchQuery);
//create the term query object
Query query = new FuzzyQuery(term);
searcher.setDefaultFieldSortScoring(true, false);
//do the search
TopDocs hits = searcher.search(query,Sort.INDEXORDER);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) + "ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.print("Score: "+ scoreDoc.score + " ");
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
数据和索引目录创建
我们使用了来自record1.txt的10个文本文件到包含学生姓名和其他详细信息的record10.txt,并将它们放在目录E:\Lucene\Data. 测试数据 。 索引目录路径应创建为E:\Lucene\Index。 在Lucene - Indexing Process一章中运行索引程序后,您可以看到在该文件夹中创建的索引文件列表。
运行程序 (Running the Program)
完成源,原始数据,数据目录,索引目录和索引的创建后,您可以编译并运行程序。 为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用Eclipse IDE中提供的“运行”选项或使用Ctrl + F11编译并运行LuceneTester应用程序。 如果您的应用程序成功运行,它将在Eclipse IDE的控制台中打印以下消息 -
10 documents found. Time :31ms
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
10 documents found. Time :0ms
Score: 0.790779 File: E:\Lucene\Data\record1.txt
Score: 0.2635932 File: E:\Lucene\Data\record10.txt
Score: 0.790779 File: E:\Lucene\Data\record2.txt
Score: 1.3179655 File: E:\Lucene\Data\record3.txt
Score: 0.790779 File: E:\Lucene\Data\record4.txt
Score: 0.790779 File: E:\Lucene\Data\record5.txt
Score: 0.790779 File: E:\Lucene\Data\record6.txt
Score: 0.790779 File: E:\Lucene\Data\record7.txt
Score: 0.790779 File: E:\Lucene\Data\record8.txt
Score: 0.790779 File: E:\Lucene\Data\record9.txt
