Erlang - 快速指南
Erlang - Overview
Erlang是一种函数式编程语言,它也有一个运行时环境。 它的构建方式使其集成了对并发,分发和容错的支持。 Erlang最初开发用于爱立信的几个大型电信系统。
Erlang的第一个版本是由Joe Armstrong,Robert Virding和Mike Williams在1986年开发的。它最初是爱立信的专有语言。 它后来在1998年作为开源语言发布.Erlang和OTP,Erlang中的中间件和库的集合,现在由爱立信的OTP产品部门支持和维护,并被广泛称为Erlang/OTP 。
为何选择Erlang?
如果您有以下要求,Erlang应该用于开发您的应用程序 -
应用程序需要处理大量并发活动。
它应该可以通过计算机网络轻松分发。
应该有一个工具可以使应用程序容错软件和硬件错误。
应用程序应该是可扩展的。 这意味着它应该能够跨越多个服务器,几乎没有变化。
它应该易于升级和重新配置,而无需停止并重新启动应用程序本身。
应用程序应在特定严格的时间范围内响应用户。
Erlang的官方网站是https://www.erlang.org/ 。
Erlang - Environment
现在,在开始使用Erlang之前,您需要确保在系统上运行Erlang的全功能版本。 本节将介绍如何在Windows机器上安装Erlang及其后续配置以开始使用Erlang。
在继续安装之前,请确保满足以下系统要求。
System Requirements
| 记忆 | 2 GB RAM(推荐) |
|---|---|
| 磁盘空间 | 没有最低要求。 优选地,具有足够的存储空间来存储将使用Erlang创建的应用程序。 |
| 操作系统版本 | Erlang可以安装在Windows,Ubuntu/Debian,Mac OS X上。 |
正在下载Erlang
要下载Erlang,必须访问以下网址 - www.erlang.org/downloads 。
此页面具有各种下载以及在Linux和Mac平台上下载和安装该语言所需的步骤。
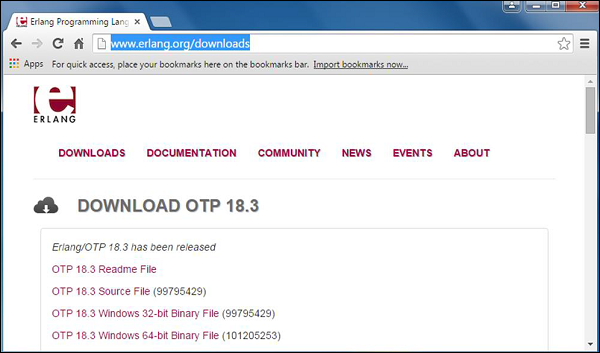
单击“OTP 18.3 Windows 32位二进制文件”开始下载Erlang Windows安装文件。
Erlang安装
以下步骤详细说明了如何在Windows上安装Erlang -
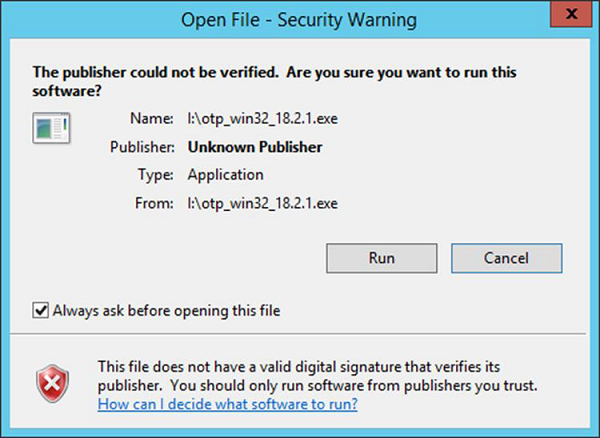
Step 1 - 启动前面部分中下载的安装程序。 安装程序启动后,单击“运行”。
Step 2 - 在以下屏幕上单击“下一步”以接受将要安装的默认组件。
Step 3 - 接受默认安装路径,然后单击“下一步”。
Step 4 - 接受将创建的默认“开始”菜单项,然后单击“下一步”。
Step 5 - 安装完成后,单击“关闭”以完成安装。
Erlang配置
安装完成后,需要执行以下配置以确保Erlang开始在系统上运行。
| OS | output |
|---|---|
| Windows | 附加字符串; C:\Program Files(x86)\ erl7.2.1\bin或C:\Program Files\erl7.2.1\bin到系统变量PATH的末尾。 |
如果现在打开命令提示符并键入erl ,则应该能够获取erl命令提示符。
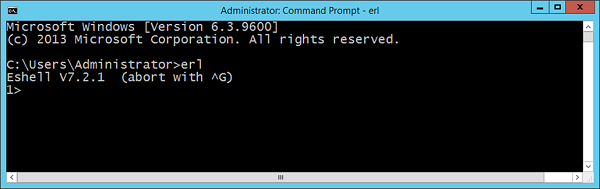
恭喜,您现在已经在笔记本电脑上成功配置了erl。
在流行的IDE上安装插件
Erlang作为一种编程语言也可以在流行的IDE中使用,例如Eclipse and IntelliJ 。 让我们看一下如何在这些IDE中获取所需的插件,以便您在使用Erlang时有更多选择。
在Eclipse中安装
Step 1 - 打开Eclipse并单击“菜单”项,“ Help → Install New Software 。
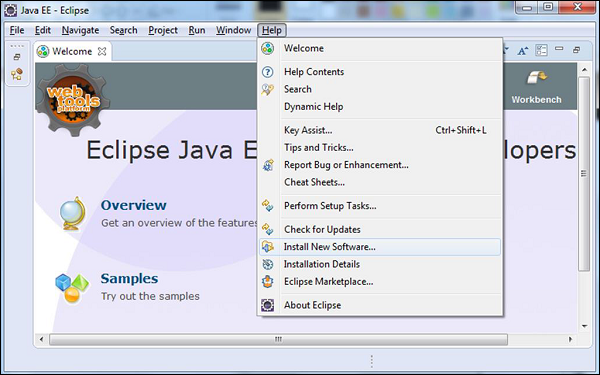
Step 2 - 输入Work with链接为https://download.erlide.org/update
然后单击添加。
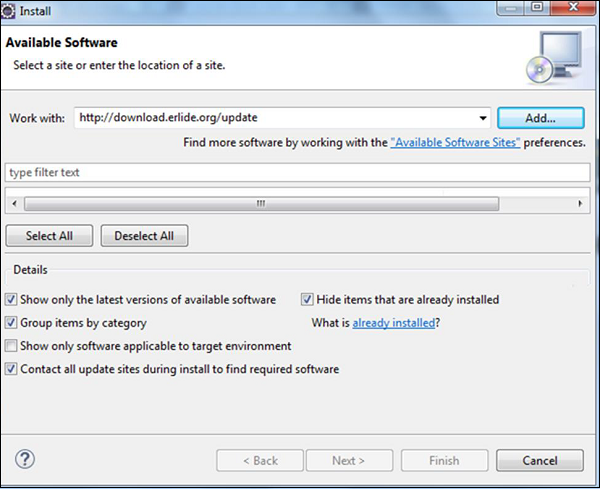
Step 3 - 然后会提示您输入插件的名称,输入名称为Erlide 。 单击确定。
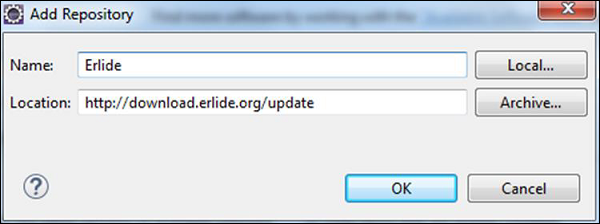
Step 4 - Eclipse将扫描提供的链接并获取所需的插件。 检查插件,然后单击“下一步”。
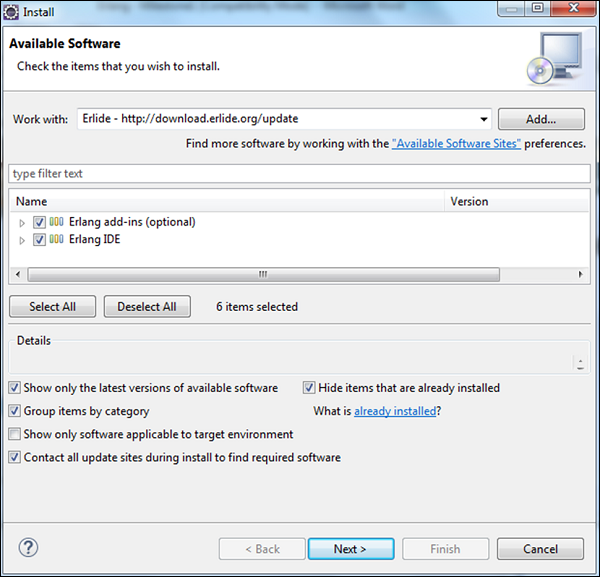
Step 5 - 在下一个对话框中,Eclipse将显示将要安装的所有组件。 点击下一步。
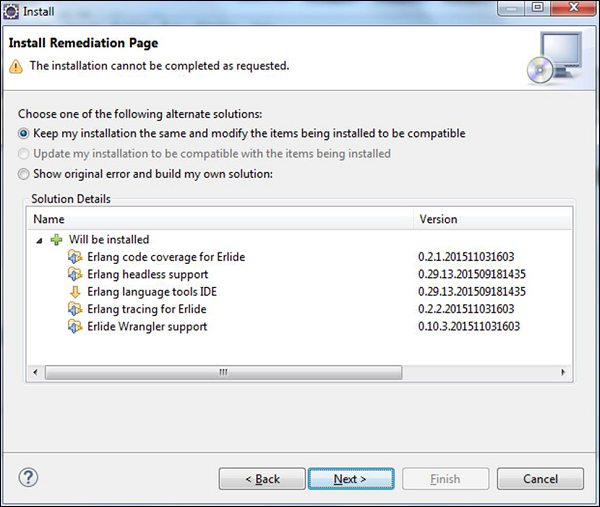
Step 6 - 在下一个对话框中,Eclipse将要求查看正在安装的组件。 点击下一步。
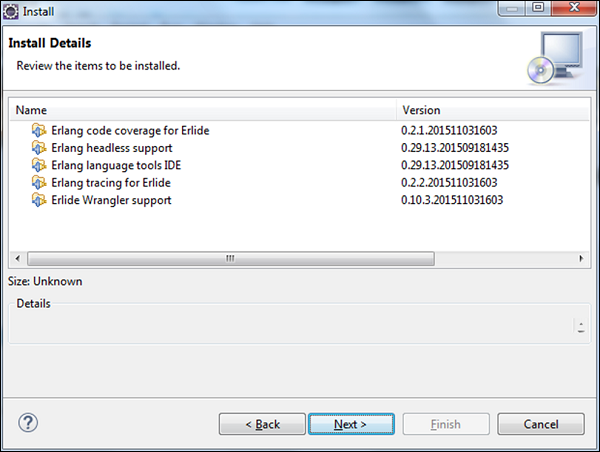
Step 7 - 在下一个对话框中,您只需接受许可协议。 最后,单击“完成”按钮。
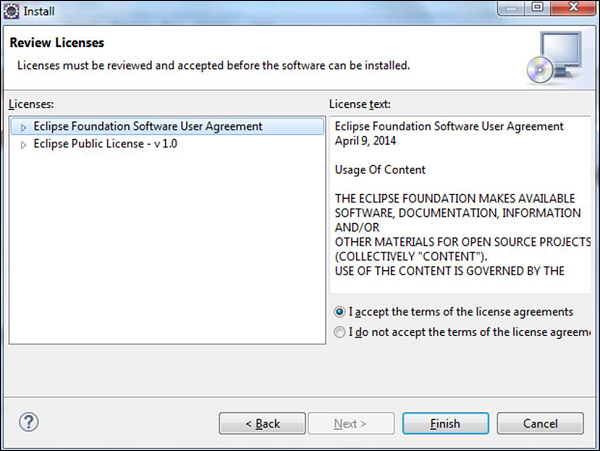
然后安装将开始,一旦完成,它将提示您重新启动Eclipse。
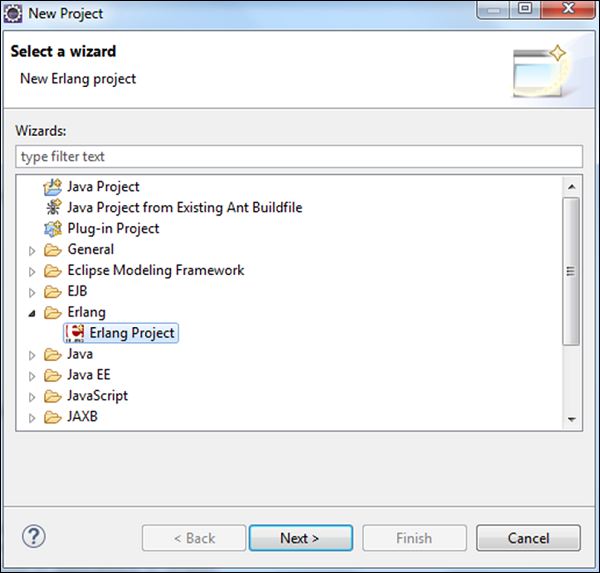
重新启动Eclipse后,当您创建项目时,您也可以将Erlang视为一个选项。
在IntelliJ中安装
请按照后续步骤在计算机中安装IntelliJ。
Step 1 - 打开IntelliJ,然后单击配置→插件。
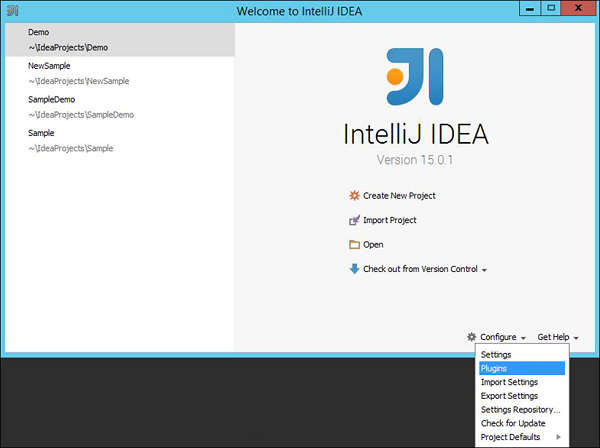
Step 2 - 在搜索框中输入Erlang。 您将在屏幕的右侧获得Erlang插件。 单击“安装”按钮。
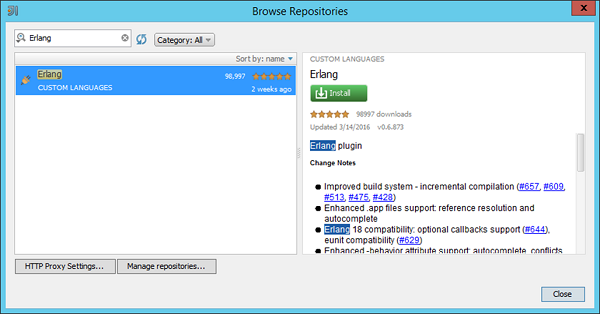
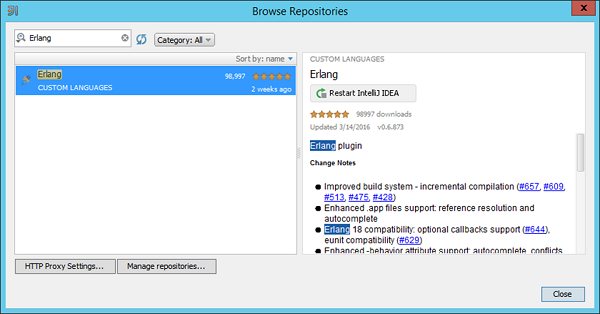
Step 3 - 安装Erlang插件后,系统将提示您重新启动IDE。
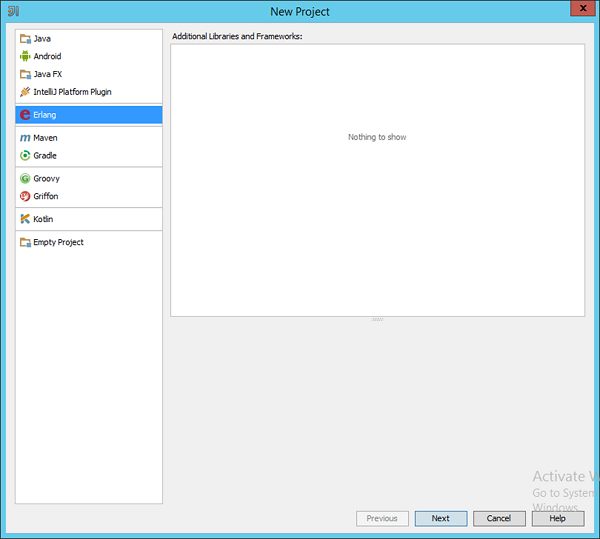
重新启动IDE并尝试创建新项目时,您将看到创建Erlang项目的选项。
Erlang - Basic Syntax
为了理解Erlang的基本语法,让我们首先看一个简单的Hello World程序。
例子 (Example)
% hello world program
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("Hello, world!\n").
关于上述计划需要注意以下事项 -
%符号用于向程序添加注释。
模块语句就像添加任何编程语言中的命名空间一样。 所以在这里,我们提到这段代码将成为一个名为helloworld的模块的一部分。
使用导出函数,以便可以使用程序中定义的任何函数。 我们定义了一个名为start的函数,为了使用start函数,我们必须使用export语句。 /0表示我们的函数'start'接受0参数。
我们最终定义了启动功能。 这里我们使用另一个名为io模块,它在Erlang中具有所有必需的输入输出函数。 我们使用fwrite函数将“Hello World”输出到控制台。
上述计划的输出将是 -
输出 (Output)
Hello, world!
声明的一般形式
在Erlang中,您已经看到Erlang语言中使用了不同的符号。 让我们看看我们从简单的Hello World程序中看到的内容 -
连字符号(–)通常与模块,导入和导出语句一起使用。 连字符符号用于相应地赋予每个语句含义。 所以来自Hello world程序的示例显示在以下程序中 -
-module(helloworld).
-export([start/0]).
每个语句都用点(.)符号分隔。 Erlang中的每个语句都需要以此分隔符结束。 来自Hello world程序的示例如以下程序所示 -
io:fwrite("Hello, world!\n").
斜杠(/)符号与函数一起使用,以定义函数接受的参数数量。
-export([start/0]).
单元 (Modules)
在Erlang中,所有代码都分为模块。 模块由一系列属性和函数声明组成。 它就像其他编程语言中的命名空间概念一样,用于逻辑地分隔不同的代码单元。
定义一个模块
使用模块标识符定义模块。 一般语法和示例如下。
语法 (Syntax)
-module(ModuleName)
ModuleName需要与文件名减去扩展名.erl 。 否则代码加载将无法按预期工作。
例子 (Example)
-module(helloworld)
这些模块将在随后的章节中详细介绍,这只是为了让您基本了解如何定义模块。
在Erlang中导入语句
在Erlang中,如果想要使用现有Erlang模块的功能,可以使用import语句。 import语句的一般形式在以下程序中描述 -
例子 (Example)
-import (modulename, [functionname/parameter]).
Where,
Modulename - 这是需要导入的模块的名称。
functionname/parameter - 需要导入的模块中的函数。
让我们改变编写hello world程序的方式来使用import语句。 示例将如以下程序所示。
例子 (Example)
% hello world program
-module(helloworld).
-import(io,[fwrite/1]).
-export([start/0]).
start() ->
fwrite("Hello, world!\n").
在上面的代码中,我们使用import关键字导入库'io',特别是fwrite函数。 所以现在每当我们调用fwrite函数时,我们都不必在任何地方提到io模块名称。
Erlang中的关键字
关键字是Erlang中的保留字,不应用于任何其他目的,而不是用于其目的。 以下是Erlang中的关键字列表。
| after | and | andalso | band |
| begin | bnot | bor | bsl |
| bsr | bxor | case | catch |
| cond | div | end | fun |
| if | let | not | of |
| or | orelse | receive | rem |
| try | when | xor |
Erlang中的评论
注释用于记录您的代码。 通过在行中的任何位置使用%符号来标识单行注释。 以下是同样的例子 -
例子 (Example)
% hello world program
-module(helloworld).
% import function used to import the io module
-import(io,[fwrite/1]).
% export function used to ensure the start function can be accessed.
-export([start/0]).
start() ->
fwrite("Hello, world!\n").
Erlang - Shell
Erlang shell用于测试表达式。 因此,在实际测试应用程序本身之前,可以非常轻松地在shell中进行测试。
以下示例展示了如何在shell中使用加法表达式。 这里需要注意的是表达式需要以点(。)分隔符结束。
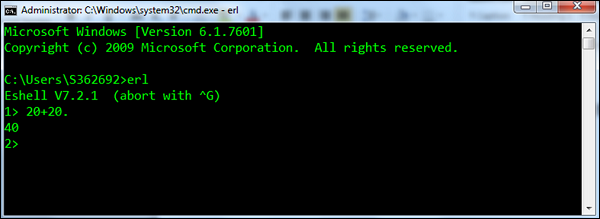
执行命令后,shell会打印另一个提示符,这次是命令编号2(因为每次输入新命令时命令编号都会增加)。
以下函数是Erlang shell中最常用的函数。
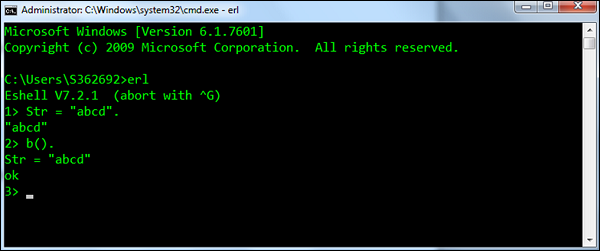
b() - 打印当前变量绑定。
Syntax - b()。
For example - 以下是如何使用该函数的示例。 首先定义一个名为Str的变量,其值为abcd 。 然后b()用于显示所有绑定变量。
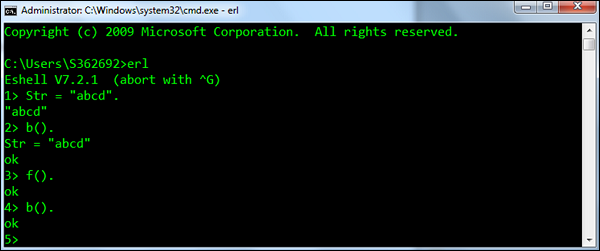
f() - 删除所有当前变量绑定。
Syntax - f()。
For example - 以下是如何使用该函数的示例。 首先定义一个名为Str的变量,其值为abcd。 然后使用f()来删除Str变量绑定。 然后调用b()以确保已成功删除绑定。
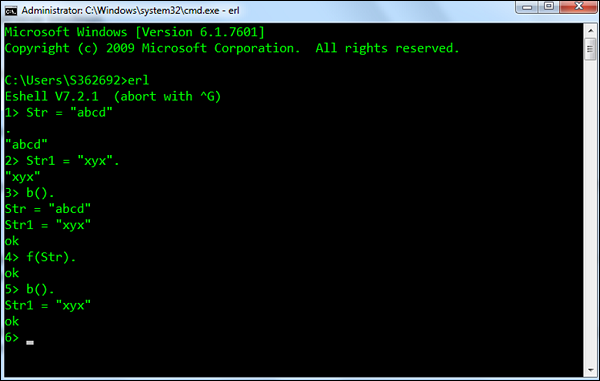
f(x) - 删除特定变量的绑定。
Syntax - f(x)。 其中,x - 是需要删除绑定的变量。
For example - 以下是如何使用该函数的示例。 首先定义一个名为Str和Str1的变量。 然后使用f(Str)来移除Str变量绑定。 然后调用b()以确保已成功删除绑定。
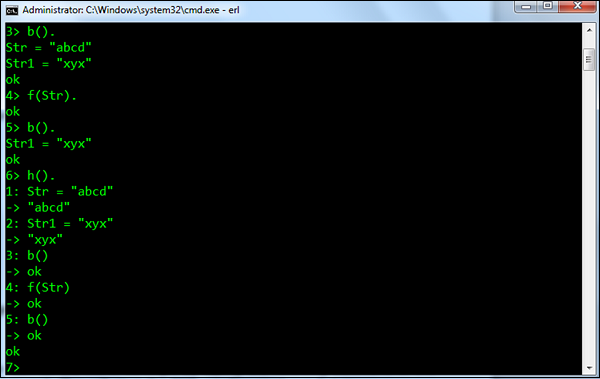
h() - 打印shell中执行的所有命令的历史列表。
Syntax - h()。
For example - h()命令的一个示例,它打印在shell中执行的命令的历史记录,如以下屏幕截图所示。
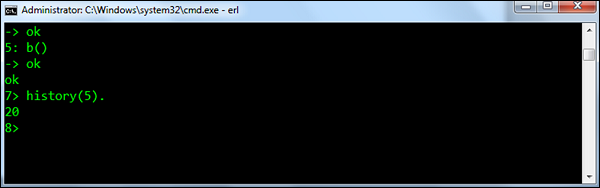
history(N) - 将要保留在历史记录列表中的先前命令的数量设置为N.返回前一个数字。 默认数量为20。
Syntax - 历史(N)。 其中,N - 是命令历史列表需要限制的编号。
For example - 历史(N)命令的示例显示在以下屏幕截图中。
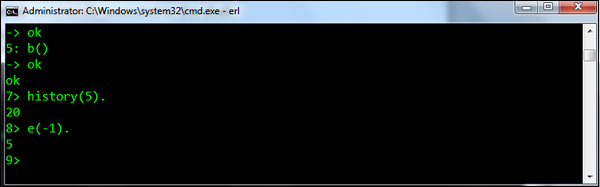
e(N) - 如果N为正,则重复命令N. 如果是否定的,则重复第 N 个先前命令(即,e(-1)重复前一个命令)。
Syntax - e(N)。 其中,N - 是列表中第 N 个位置的命令。
For example - e(N)命令的示例如下所示。 由于我们已经执行了e(-1)命令,它将执行前一个命令(历史记录(5))。
Erlang - Data Types
在任何编程语言中,您都需要使用多个变量来存储各种类型的信息。 变量只是用于存储值的保留内存位置。 这意味着当您创建变量时,您在内存中保留一些空间以存储与该变量关联的值。
您可能希望存储各种数据类型的信息,如字符串,字符,宽字符,整数,浮点,布尔值等。根据变量的数据类型,操作系统分配内存并决定可以在保留中存储的内容记忆。
(类型)
Erlang提供各种内置数据类型。 以下是Erlang中定义的数据类型列表 -
Number - 在Erlang中,有两种类型的数字文字,它们是整数和浮点数。
Atom - 原子是文字,是名称的常量。 如果原子不是以小写字母开头,或者如果它包含除字母数字字符,下划线(_)或@之外的其他字符,则用单引号(')括起来。
Boolean - Erlang中的布尔数据类型是两个保留的原子:true和false。
Bit String - 位串用于存储未键入内存的区域。
Tuple - 元组是具有固定数量项的复合数据类型。 元组中的每个Term都被称为元素。 元素的数量被认为是元组的大小。
Map - 映射是具有可变数量的键 - 值关联的复合数据类型。 映射中的每个键值关联称为关联对。 该对的键和值部分称为元素。 关联对的数量被称为地图的大小。
List - 列表是具有可变数量的术语的复合数据类型。 列表中的每个术语称为元素。 元素的数量被称为列表的长度。
Note - 您会惊讶地发现在上面的列表中的任何位置都看不到String类型。 那是因为Erlang中没有专门定义的字符串数据类型。 但是我们将在后续章节中看到如何使用字符串。
以下是如何使用每种数据类型的示例。 同样,每个数据类型将在随后的章节中详细讨论。 这只是为了让您熟悉上述数据类型的简要说明。
Number
以下程序显示了如何使用数字数据类型的示例。 该程序显示添加2个整数。
Example
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[1+1]).
上述计划的输出将是 -
Output
2
Atom
原子应以小写字母开头,可以包含小写和大写字符,数字,下划线(_)和“at”符号(@) 。 我们也可以用单引号括起原子。
以下程序显示了如何使用原子数据类型的示例。 在这个程序中,我们创建了一个名为atom1的原子。
Example
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite(atom1).
上述计划的输出将是 -
Output
atom1
Boolean
以下程序中显示了如何使用布尔数据类型的示例。 此示例对2个整数进行比较,并将结果布尔值打印到控制台。
Example
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite(2 =< 3).
上述计划的输出将是 -
Output
true
位串
以下程序中显示了如何使用位串数据类型的示例。 该程序定义了一个由2位组成的位串。 binary_to_list是Erlang中定义的内置函数,可用于将位字符串转换为列表。
Example
-module(helloworld).
-export([start/0]).
start() ->
Bin1 = <<10,20>>,
X = binary_to_list(Bin1),
io:fwrite("~w",[X]).
上述计划的输出将是 -
Output
[10,20]
Tuple
以下程序中显示了如何使用元组数据类型的示例。
这里我们定义一个有3个术语的Tuple P tuple_size是Erlang中定义的内置函数,可用于确定元组的大小。
Example
-module(helloworld).
-export([start/0]).
start() ->
P = {john,24,{june,25}} ,
io:fwrite("~w",[tuple_size(P)]).
上述计划的输出将是 -
Output
3
地图
以下程序中显示了如何使用Map数据类型的示例。
这里我们定义一个有两个映射的Map M1 。 map_size是Erlang中定义的内置函数,可用于确定地图的大小。
Example
-module(helloworld).
-export([start/0]).
start() ->
M1 = #{name=>john,age=>25},
io:fwrite("~w",[map_size(M1)]).
上述计划的输出将是 -
Output
2
List
以下程序中显示了如何使用List数据类型的示例。
这里我们定义一个包含3个项目的List L 长度是Erlang中定义的内置函数,可用于确定列表的大小。
Example
-module(helloworld).
-export([start/0]).
start() ->
L = [10,20,30] ,
io:fwrite("~w",[length(L)]).
上述计划的输出将是 -
Output
3
Erlang - Variables
在Erlang中,所有变量都与'='语句绑定。 所有变量都需要以大写字符开头。 在其他编程语言中,'='符号用于赋值,但不用于Erlang。 如上所述,变量是使用'='语句定义的。
在Erlang中需要注意的一件事是变量是不可变的,这意味着为了使变量的值发生变化,需要将其销毁并重新创建。
Erlang中的以下基本变量在最后一章中进行了解释 -
Numbers - 用于表示整数或浮点数。 一个例子是10。
Boolean - 这表示一个布尔值,可以是true或false。
Bit String - 位串用于存储未键入内存的区域。 一个例子是“”40,50“”。
Tuple - 元组是具有固定数量项的复合数据类型。 一个例子是{40,50}。
Map - 映射是具有可变数量的键 - 值关联的复合数据类型。 映射中的每个键值关联称为关联对。 一个例子是{type =“person,age =”25}。
List - 列表是具有可变数量的术语的复合数据类型。 一个例子是[40,40]。
变量声明
定义变量的一般语法如下 -
语法 (Syntax)
var-name = var-value
Where,
var-name - 这是变量的名称。
var-value - 这是绑定到变量的值。
以下是变量声明的示例 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
X = 40,
Y = 50,
Result = X + Y,
io:fwrite("~w",[Result]).
在上面的例子中,我们有2个变量,一个是X,它绑定到值40,下一个是Y,它绑定到50的值。另一个名为Result的变量绑定到X和Y的加法。
上述计划的输出将是 -
输出 (Output)
90
命名变量 (Naming Variables)
如上所述,变量名必须以大写字母开头。 让我们举一个以小写形式声明的变量的例子。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
X = 40,
Y = 50,
result = X + Y,
io:fwrite("~w",[Result]).
如果您尝试编译上述程序,您将收到以下编译时错误。
输出 (Output)
helloworld.erl:8: variable 'Result' is unbound
其次,所有变量只能分配一次。 让我们举一个不止一次分配变量的例子。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
X = 40,
Y = 50,
X = 60,
io:fwrite("~w",[X]).
如果您尝试编译上述程序,您将收到以下编译时错误。
输出 (Output)
helloworld.erl:6: Warning: variable 'Y' is unused
helloworld.erl:7: Warning: no clause will ever match
helloworld.erl:7: Warning: the guard for this clause evaluates to 'false'
打印变量
在本节中,我们将讨论如何使用打印变量的各种功能。
使用io:fwrite函数
你会看到所有上述程序中使用的这个(io:fwrite)。 fwrite函数是'io'模块或Erlang的一部分,它可用于输出程序中变量的值。
以下示例显示了一些可以与fwrite语句一起使用的参数。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
X = 40.00,
Y = 50.00,
io:fwrite("~f~n",[X]),
io:fwrite("~e",[Y]).
上述计划的输出将是 -
输出 (Output)
40.000000
5.00000e+1
关于上述程序,应注意以下几点。
~ - 此字符表示需要对输出执行某些格式化。
~f - 参数是一个浮点数,写为[ - ] ddd.ddd,其中精度是小数点后的位数。 默认精度为6,不能小于1。
~n - 这是println到新行。
~e - 参数是一个浮点数,写为[ - ] d.ddde + -ddd,其中precision是写入的位数。 默认精度为6,不能小于2。
Erlang - Operators
运算符是一个符号,告诉编译器执行特定的数学或逻辑操作。
Erlang有以下类型的运算符 -
- 算术运算符
- 关系运算符
- 逻辑运算符
- 按位运算符
算术运算符 (Arithmetic Operators)
Erlang语言支持普通的算术运算符作为任何语言。 以下是Erlang中可用的算术运算符。
| 操作者 | 描述 | 例 |
|---|---|---|
| + | 增加了两个操作数 | 1 + 2将给出3 |
| − | 从第一个减去第二个操作数 | 1 - 2将给-1 |
| * | 两个操作数的乘法 | 2 * 2将给4 |
| / | 由分母划分的分子 | 2/2会给1 |
| rem | 将第一个数除以第二个数的余数 | 3 rem 2将给出1 |
| div | div组件将执行除法并返回整数组件。 | 3 div 2将给出1 |
关系运算符 (Relational Operators)
关系运算符允许比较对象。 以下是Erlang中可用的关系运算符。
| 操作者 | 描述 | 例 |
|---|---|---|
| == | 测试两个对象之间的相等性 | 2 = 2将给出真实 |
| /= | 测试两个对象之间的差异 | 3/= 2将给出真实 |
| < | 检查左对象是否小于右操作数。 | 2 <3将给出真实 |
| =< | 检查左对象是否小于或等于右操作数。 | 2 = <3将给出真实 |
| > | 检查左对象是否大于右操作数。 | 3> 2将给出真实 |
| >= | 检查左对象是否大于或等于右操作数。 | 3> = 2将给出真实 |
逻辑运算符 (Logical Operators)
这些逻辑运算符用于计算布尔表达式。 以下是Erlang中可用的逻辑运算符。
| 操作者 | 描述 | 例 |
|---|---|---|
| or | 这是逻辑“或”运算符 | 真或假会成真 |
| and | 这是逻辑“和”运算符 | 真与假会给出错误 |
| not | 这是逻辑“非”运算符 | 不是假的会给出真实的 |
| xor | 这是逻辑上独有的“xor”运算符 | 真正的xor假将给出真实 |
按位运算符 (Bitwise Operators)
Erlang提供了四个按位运算符。 以下是Erlang中可用的按位运算符。
| Sr.No. | 操作符和说明 |
|---|---|
| 1 | band 这是按位“和”运算符 |
| 2 | bor 这是按位“或”运算符 |
| 3 | bxor 这是按位“xor”或Exclusive或运算符 |
| 4 | bnot 这是按位否定运算符 |
以下是展示这些运算符的真值表 -
| p | q | p&q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
运算符优先级 (Operator Precedence)
下表按优先级降序及其关联性顺序显示了Erlang运算符的运算符优先级。 运算符优先级和关联性用于确定未加括号的表达式中的评估顺序。
| 运算符 | 关联性 |
|---|---|
| : | |
| # | |
| bnot,not | |
| /,*,div,rem,band,and | Left Associative |
| +,-,bor,bxor,or,xor | Left Associative |
| ==,/=,=<,<,>=,> |
Erlang - Loops
Erlang是一种函数式编程语言,需要记住的是所有函数式编程语言,它们不提供任何循环结构。 相反,函数式编程依赖于一种称为递归的概念。
声明实施
由于Erlang中没有直接的while语句,因此必须使用Erlang中提供的递归技术来执行while语句实现。
我们将尝试按照其他编程语言中所遵循的while循环的相同实现。 以下是将遵循的一般流程。
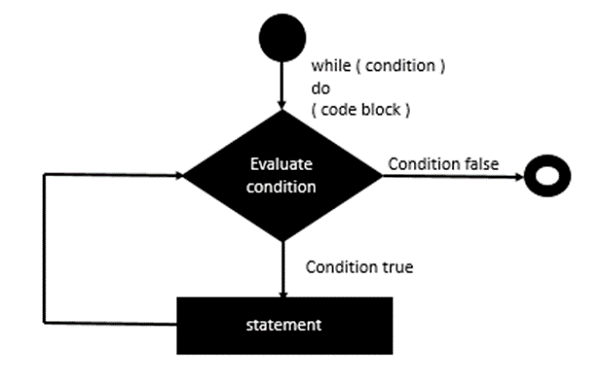
让我们看一下如何使用递归在Erlang中实现while循环的示例。
例子 (Example)
-module(helloworld).
-export([while/1,while/2, start/0]).
while(L) -> while(L,0).
while([], Acc) -> Acc;
while([_|T], Acc) ->
io:fwrite("~w~n",[Acc]),
while(T,Acc+1).
start() ->
X = [1,2,3,4],
while(X).
关于上述计划需要注意以下要点 -
定义一个名为while的递归函数,它将模拟while循环的实现。
将变量X中定义的值列表输入到while函数中作为示例。
while函数获取每个列表值并将中间值存储在变量“Acc”中。
然后对列表中的每个值递归调用while循环。
上述代码的输出将是 -
输出 (Output)
0
1
2
3
for 语句
由于Erlang中没有直接for语句,因此必须使用Erlang中提供的递归技术来执行for语句实现。
我们将尝试遵循与其他编程语言中所遵循的for循环相同的实现。 以下是应该遵守的一般流程。
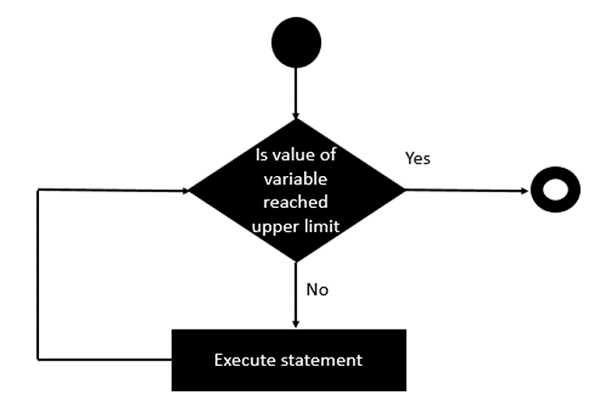
让我们看一下如何使用递归在Erlang中实现for循环的示例。
例子 (Example)
-module(helloworld).
-export([for/2,start/0]).
for(0,_) ->
[];
for(N,Term) when N > 0 ->
io:fwrite("Hello~n"),
[Term|for(N-1,Term)].
start() ->
for(5,1).
关于上述计划需要注意以下要点 -
我们正在定义一个递归函数,它将模拟for loop的实现。
我们在'for'函数中使用了一个保护,以确保N或限制的值是正值。
我们递归调用for函数,通过在每次递归时减少N的值。
上述代码的输出将是 -
输出 (Output)
Hello
Hello
Hello
Hello
Hello
Erlang - Decision Making
决策结构要求程序员应指定程序要评估或测试的一个或多个条件,以及在条件被确定为true要执行的语句,以及可选的其他语句,如果条件被确定为false 。
以下是大多数编程语言中常见决策结构的一般形式 -
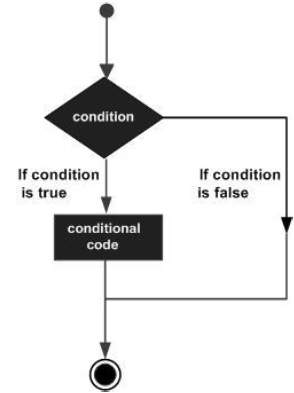
Erlang编程语言提供以下类型的决策制定语句。
| Sr.No. | 声明和说明 |
|---|---|
| 1 | if statement由一个布尔表达式后跟一个或多个语句组成。 |
| 2 | if表达式还允许一次评估多个表达式。 |
| 3 | 您可以在另一个if或else if语句中使用if或else if语句。 |
| 4 | 它可以用于根据case语句的输出执行表达式。 |
Erlang - 函数
Erlang被称为函数式编程语言,因此你会期望看到很多函数在Erlang中如何工作。 本章介绍了Erlang中的所有功能。
定义一个函数 (Defining a Function)
函数声明的语法如下 -
语法 (Syntax)
FunctionName(Pattern1… PatternN) ->
Body;
Where,
FunctionName - 函数名称是一个原子。
Pattern1… PatternN - 每个参数都是一个模式。 参数的数量N是函数的arity。 函数由模块名称,函数名称和arity唯一定义。 也就是说,具有相同名称和相同模块但具有不同arities的两个函数是两个不同的函数。
正文 - 子句主体由一系列用逗号(,)分隔的表达式组成:
以下程序是使用函数的简单示例 -
例子 (Example)
-module(helloworld).
-export([add/2,start/0]).
add(X,Y) ->
Z = X+Y,
io:fwrite("~w~n",[Z]).
start() ->
add(5,6).
关于上述计划应注意以下几点 -
我们定义了两个函数,一个叫做add ,它有2个参数,另一个是start函数。
这两个函数都是使用导出函数定义的。 如果我们不这样做,我们将无法使用该功能。
一个函数可以在另一个函数中调用。 这里我们从start函数调用add函数。
上述计划的输出将是 -
输出 (Output)
11
匿名函数
匿名函数是一个函数,它没有与之关联的名称。 Erlang具有定义匿名函数的功能。 以下程序是匿名函数的示例。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
Fn = fun() ->
io:fwrite("Anonymous Function") end,
Fn().
关于上述例子需要注意以下几点 -
匿名函数使用fun()关键字定义。
函数被分配给名为Fn的变量。
函数通过变量名称调用。
上述计划的输出将是 -
输出 (Output)
Anonymous Function
具有多个参数的函数
可以使用零个或多个参数定义Erlang函数。 函数重载也是可能的,其中您可以多次定义具有相同名称的函数,只要它们具有不同数量的参数即可。
在以下示例中,函数demo使用每个函数定义的多个参数进行定义。
例子 (Example)
-module(helloworld).
-export([add/2,add/3,start/0]).
add(X,Y) ->
Z = X+Y,
io:fwrite("~w~n",[Z]).
add(X,Y,Z) ->
A = X+Y+Z,
io:fwrite("~w~n",[A]).
start() ->
add(5,6),
add(5,6,6).
在上面的程序中,我们定义了两次add函数。 但是第一个add函数的定义包含两个参数,第二个参数包含三个参数。
上述计划的输出将是 -
输出 (Output)
11
17
具有保护序列的功能
Erlang中的函数也具有保护序列的能力。 这些只是表达式,只有当评估为true时才会导致函数运行。
具有保护序列的函数的语法显示在以下程序中。
语法 (Syntax)
FunctionName(Pattern1… PatternN) [when GuardSeq1]->
Body;
Where,
FunctionName - 函数名称是一个原子。
Pattern1… PatternN - 每个参数都是一个模式。 参数的数量N是函数的arity。 函数由模块名称,函数名称和arity唯一定义。 也就是说,具有相同名称和相同模块但具有不同arities的两个函数是两个不同的函数。
正文 - 子句主体由一系列表达式组成,这些表达式用逗号(,)分隔。
GuardSeq1 - 这是在调用函数时得到的表达式。
以下程序是使用具有保护序列的函数的简单示例。
例子 (Example)
-module(helloworld).
-export([add/1,start/0]).
add(X) when X>3 ->
io:fwrite("~w~n",[X]).
start() ->
add(4).
上述计划的输出是 -
输出 (Output)
4
如果add函数被称为add(3) ,程序将导致错误。
Erlang - Modules
模块是在单个文件中以单个名称重新组合的一组函数。 此外,Erlang中的所有函数都必须在模块中定义。
算术,逻辑和布尔运算符等大多数基本功能已经可用,因为在运行程序时会加载默认模块。 您将使用的模块中定义的每个其他函数都需要使用Module:Function (Arguments)形式调用。
定义模块
使用模块,您可以声明两种内容:函数和属性。 属性是描述模块本身的元数据,例如其名称,应该对外部世界可见的函数,代码的作者等。 这种元数据很有用,因为它为编译器提供了如何完成其工作的提示,同时也因为它允许人们从编译的代码中检索有用的信息而无需查阅源代码。
函数声明的语法如下 -
语法 (Syntax)
-module(modulename)
其中, modulename是模块的名称。 这必须是模块中代码的第一行。
以下程序显示了一个名为helloworld的模块示例。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("Hello World").
上述计划的输出是 -
输出 (Output)
Hello World
模块属性
模块属性定义模块的某个属性。 模块属性由标记和值组成。
属性的一般语法是 -
语法 (Syntax)
-Tag(Value)
以下程序显示了如何使用该属性的示例 -
例子 (Example)
-module(helloworld).
-author("TutorialPoint").
-version("1.0").
-export([start/0]).
start() ->
io:fwrite("Hello World").
上述程序定义了2个名为author和version的自定义属性,分别包含程序作者和程序版本号。
上述计划的输出是 -
输出 (Output)
Hello World
Pre-built Attributes
Erlang有一些预先构建的属性,可以附加到模块。 我们来看看它们。
Export
exports属性将获取要导出以供其他模块使用的函数和arity列表。 它将定义模块接口。 我们之前的所有例子都已经看到了这一点。
语法 (Syntax)
export([FunctionName1/FunctionArity1,.,FunctionNameN/FunctionArityN])
Where,
FunctionName - 这是程序中函数的名称。
FunctionArity - 这是与函数关联的参数数量。
例子 (Example)
-module(helloworld).
-author("TutorialPoint").
-version("1.0").
-export([start/0]).
start() ->
io:fwrite("Hello World").
上述计划的输出将是 -
输出 (Output)
Hello World
Import
import属性用于从另一个模块导入函数以将其用作本地函数。
语法 (Syntax)
-import (modulename , [functionname/parameter]).
Where,
Modulename - 这是需要导入的模块的名称。
functionname/parameter - 需要导入的模块中的函数。
例子 (Example)
-module(helloworld).
-import(io,[fwrite/1]).
-export([start/0]).
start() ->
fwrite("Hello, world!\n").
在上面的代码中,我们使用import关键字导入库'io',特别是fwrite函数。 所以,现在每当我们调用fwrite函数时,我们都不必在任何地方提到io模块名称。
上述计划的输出将是 -
输出 (Output)
Hello, world!
Erlang - Recursion
递归是Erlang的重要组成部分。 首先让我们看看如何通过实现阶乘程序来实现简单的递归。
例子 (Example)
-module(helloworld).
-export([fac/1,start/0]).
fac(N) when N == 0 -> 1;
fac(N) when N > 0 -> N*fac(N-1).
start() ->
X = fac(4),
io:fwrite("~w",[X]).
关于上述计划需要注意以下事项 -
我们首先定义一个名为fac(N)的函数。
我们可以通过递归调用fac(N)来定义递归函数。
上述计划的输出是 -
输出 (Output)
24
递归的实用方法
在本节中,我们将详细了解不同类型的递归及其在Erlang中的用法。
长度递归
通过一个用于确定列表长度的简单示例,可以看到更实用的递归方法。 列表可以有多个值,例如[1,2,3,4]。 让我们使用递归来看看我们如何获得列表的长度。
Example
-module(helloworld).
-export([len/1,start/0]).
len([]) -> 0;
len([_|T]) -> 1 + len(T).
start() ->
X = [1,2,3,4],
Y = len(X),
io:fwrite("~w",[Y]).
关于上述计划需要注意以下事项 -
如果列表为空,则第一个函数len([])用于特殊情况条件。
与一个或多个元素的列表匹配的[H|T]模式,作为长度为1的列表将被定义为[X|[]] ,长度为2的列表将被定义为[X|[Y|[]]] 。 请注意,第二个元素本身就是一个列表。 这意味着我们只需要计算第一个,并且函数可以在第二个元素上调用自身。 给定列表中的每个值计为长度1。
上述计划的输出将是 -
Output
4
尾递归
要了解尾递归的工作原理,让我们理解上一节中的以下代码是如何工作的。
Syntax
len([]) -> 0;
len([_|T]) -> 1 + len(T).
1 + len(Rest)的答案需要找到len(Rest)的答案。 然后函数len(Rest)本身需要找到另一个函数调用的结果。 添加将被堆叠,直到找到最后一个,然后才会计算最终结果。
尾递归旨在通过在它们发生时减少它们来消除这种堆叠操作。
为了实现这一点,我们需要在函数中保存一个额外的临时变量作为参数。 上述临时变量有时称为累加器,并作为存储计算结果的地方,以限制我们的调用增长。
让我们看一下尾递归的例子 -
Example
-module(helloworld).
-export([tail_len/1,tail_len/2,start/0]).
tail_len(L) -> tail_len(L,0).
tail_len([], Acc) -> Acc;
tail_len([_|T], Acc) -> tail_len(T,Acc+1).
start() ->
X = [1,2,3,4],
Y = tail_len(X),
io:fwrite("~w",[Y]).
上述计划的输出是 -
Output
4
Duplicate
我们来看一个递归的例子。 这一次让我们编写一个函数,它以整数作为第一个参数,然后将任何其他术语作为第二个参数。 然后,它将创建一个由整数指定的术语副本的列表。
让我们看一下这个例子的样子 -
-module(helloworld).
-export([duplicate/2,start/0]).
duplicate(0,_) ->
[];
duplicate(N,Term) when N > 0 ->
io:fwrite("~w,~n",[Term]),
[Term|duplicate(N-1,Term)].
start() ->
duplicate(5,1).
上述计划的输出将是 -
输出 (Output)
1,
1,
1,
1,
1,
列出逆转
在Erlang中没有可以使用递归的界限。 现在让我们快速看看如何使用递归来反转列表的元素。 以下程序可用于实现此目的。
例子 (Example)
-module(helloworld).
-export([tail_reverse/2,start/0]).
tail_reverse(L) -> tail_reverse(L,[]).
tail_reverse([],Acc) -> Acc;
tail_reverse([H|T],Acc) -> tail_reverse(T, [H|Acc]).
start() ->
X = [1,2,3,4],
Y = tail_reverse(X),
io:fwrite("~w",[Y]).
上述计划的输出将是 -
输出 (Output)
[4,3,2,1]
关于上述计划需要注意以下事项 -
我们再次使用临时变量的概念将List的每个元素存储在一个名为Acc的变量中。
然后我们递归调用tail_reverse ,但这一次,我们确保最后一个元素首先放在新列表中。
然后我们递归地为列表中的每个元素调用tail_reverse。
Erlang - Numbers
在Erlang中有两种类型的数字文字,它们是整数和浮点数。 以下是一些示例,显示了如何在Erlang中使用整数和浮点数。
Integer - 以下程序显示了数字数据类型如何用作整数的示例。 该程序显示添加2个整数。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[1+1]).
上述计划的输出如下 -
输出 (Output)
2
Float - 以下程序显示了数字数据类型如何用作float的示例。 该程序显示添加2个整数。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[1.1+1.2]).
上述计划的输出如下 -
输出 (Output)
2.3
显示浮点数和指数数
使用fwrite方法将值输出到控制台时,可以使用格式化参数,这些参数可用于将数字输出为浮点数或指数数。 让我们来看看我们如何实现这一目标。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~f~n",[1.1+1.2]),
io:fwrite("~e~n",[1.1+1.2]).
上述计划的输出如下 -
输出 (Output)
2.300000
2.30000e+0
关于上述计划,需要注意以下关键事项 -
当指定了~f选项时,它表示该参数是一个浮点数,写为[-]ddd.ddd ,其中precision是小数点后的位数。 默认精度为6。
当指定~e选项时,它表示参数是一个浮点数,写为[-]d.ddde+-ddd ,其中precision是写入的位数。 默认精度为6。
数字的数学函数
Erlang中提供了以下数学函数用于数字。 请注意,Erlang的所有数学函数都存在于数学库中。 因此,以下所有示例都将使用import语句导入数学库中的所有方法。
| Sr.No. | 数学函数和描述 |
|---|---|
| 1 | 此方法返回指定值的正弦值。 |
| 2 | 此方法返回指定值的余弦值。 |
| 3 | 此方法返回指定值的正切值。 |
| 4 | 该方法返回指定值的反正弦值。 |
| 5 | 该方法返回指定值的反余弦值。 |
| 6 | 该方法返回指定值的反正切值。 |
| 7 | exp
该方法返回指定值的指数。 |
| 8 | 该方法返回指定值的对数。 |
| 9 | 该方法返回指定数字的绝对值。 |
| 10 | 该方法将数字转换为浮点值。 |
| 11 | 该方法检查数字是否为浮点值。 |
| 12 | 该方法检查数字是否为整数值。 |
Erlang - Strings
通过将字符串文本括在引号中,在Erlang中构造字符串文字。 Erlang中的字符串需要使用双引号构建,例如“Hello World”。
以下是在Erlang中使用字符串的示例 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
Str1 = "This is a string",
io:fwrite("~p~n",[Str1]).
上面的示例创建了一个名为Str1的字符串变量。 字符串“This is a string”被分配给变量并相应地显示。
上述计划的输出将是 -
输出 (Output)
“This is a string”
接下来,我们将讨论operations available for Strings的各种operations available for Strings 。 请注意,对于字符串操作,您还需要包含字符串库。
| Sr.No | 字符串方法和描述 |
|---|---|
| 1 | 该方法返回特定字符串的长度。 |
| 2 | 该方法返回一个布尔值,表示一个字符串是否等于另一个字符串。 |
| 3 | 该方法连接2个字符串并返回连接的字符串。 |
| 4 | 该方法返回字符串中字符的索引位置。 |
| 5 | 该方法返回字符串中子字符串的索引位置。 |
| 6 | 该方法根据起始位置和起始位置的字符数从原始字符串返回子字符串。 |
| 7 | 该方法根据起始位置和起始位置的字符数从原始字符串返回子字符串。 |
留下尾随字符
该方法根据字符数从字符串的左侧返回子字符串。 但是如果数字大于字符串的长度,则可以选择包含尾随字符。
语法 (Syntax)
left(str1,number,$character)
参数 (Parameters)
str1 - 这是需要从中提取子字符串的字符串。
Number - 这是子字符串中需要出现的字符数。
$Character - 要包含为尾随字符的字符。
返回值 (Return Value)
根据字符串的左侧和数字返回原始字符串中的子字符串。
例如 (For example)
-module(helloworld).
-import(string,[left/3]).
-export([start/0]).
start() ->
Str1 = "hello",
Str2 = left(Str1,10,$.),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
"hello....."
right
该方法根据字符数返回字符串右侧的子字符串。
语法 (Syntax)
right(str1,number)
参数 (Parameters)
str1 - 这是需要从中提取子字符串的字符串。
Number - 这是子字符串中需要出现的字符数。
返回值 (Return Value)
根据字符串的右侧和数字返回原始字符串中的子字符串。
例如 (For example)
-module(helloworld).
-import(string,[right/2]).
-export([start/0]).
start() ->
Str1 = "hello World",
Str2 = right(Str1,2),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
“ld”
正确的尾随字符
该方法根据字符数返回字符串右侧的子字符串。 但是如果数字大于字符串的长度,则可以选择包含尾随字符。
语法 (Syntax)
right(str1,number,$character)
参数 (Parameters)
str1 - 这是需要从中提取子字符串的字符串。
Number - 这是子字符串中需要出现的字符数。
$Character - 要包含为尾随字符的字符。
返回值 (Return Value)
根据字符串的右侧和数字返回原始字符串中的子字符串。
例如 (For example)
-module(helloworld).
-import(string,[right/3]).
-export([start/0]).
start() ->
Str1 = "hello",
Str2 = right(Str1,10,$.),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
".....hello"
to_lower
该方法以小写形式返回字符串。
语法 (Syntax)
to_lower(str1)
参数 (Parameters)
str1 - 这是需要转换为小写的字符串。
返回值 (Return Value)
以小写形式返回字符串。
例如 (For example)
-module(helloworld).
-import(string,[to_lower/1]).
-export([start/0]).
start() ->
Str1 = "HELLO WORLD",
Str2 = to_lower(Str1),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
"hello world"
to_upper
该方法以大写形式返回字符串。
语法 (Syntax)
to_upper(str1)
参数 (Parameters)
str1 - 这是需要转换为大写的字符串。
Return Value - 以大写形式返回字符串。
例如 (For example)
-module(helloworld).
-import(string,[to_upper/1]).
-export([start/0]).
start() ->
Str1 = "hello world",
Str2 = to_upper(Str1),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
"HELLO WORLD"
sub_string
返回String的子字符串,从Start的位置开始到字符串的结尾,或者包括Stop位置。
语法 (Syntax)
sub_string(str1,start,stop)
参数 (Parameters)
str1 - 这是需要返回子字符串的字符串。
start - 这是子字符串的起始位置
stop - 这是子字符串的停止位置
返回值 (Return Value)
返回String的子字符串,从Start的位置开始到字符串的结尾,或者包括Stop位置。
例如 (For example)
-module(helloworld).
-import(string,[sub_string/3]).
-export([start/0]).
start() ->
Str1 = "hello world",
Str2 = sub_string(Str1,1,5),
io:fwrite("~p~n",[Str2]).
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
"hello"
Erlang - Lists
List是用于存储数据项集合的结构。 在Erlang中,通过将值括在方括号中来创建列表。
以下是在Erlang中创建数字列表的简单示例。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
Lst1 = [1,2,3],
io:fwrite("~w~n",[Lst1]).
以上例子的输出将是 -
输出 (Output)
[1 2 3]
现在让我们讨论various methods available for Lists的various methods available for Lists 。 请注意,需要导入列表库才能使这些方法起作用。
| Sr.No | 方法和描述 |
|---|---|
| 1 | 如果Pred(Elem)为List中的所有元素Elem返回true,则返回true,否则返回false。 |
| 2 | 如果Pred(Elem)为List中的至少一个元素Elem返回true,则返回true。 |
| 3 | 返回一个新列表List3,它由List1的元素后跟List2的元素组成。 |
| 4 | 从列表中删除元素并返回新列表。 |
| 5 | 删除List的最后一个元素。 |
| 6 | 返回包含术语Elem的N个副本的列表 |
| 7 | 返回列表的最后一个元素 |
| 8 | 返回具有最大值的列表元素。 |
| 9 | 检查列表中是否存在元素。 |
| 10 | 返回具有最小值的列表元素。 |
| 11 | 返回合并ListOfLists的所有子列表形成的排序列表。 |
| 12 | 返回List的第N个元素。 |
| 13 | 返回List的第N个尾部。 |
| 14 | 反转元素列表。 |
| 15 | 对元素列表进行排序。 |
| 16 | 返回元素的子列表。 |
| 17 | 返回列表中元素的总和。 |
Erlang - File I/O
在使用I/O时,Erlang提供了许多方法。 它有更简单的类来为文件提供以下功能 -
- 读文件
- 写入文件
- 查看文件是文件还是目录
Erlang中的文件操作方法
让我们来探讨一下Erlang提供的一些文件操作。 出于这些示例的目的,我们假设有一个名为NewFile.txt的文件,其中包含以下文本行
Example1
Example2
Example3
此文件将用于以下示例中的读取和写入操作。
一次读取一行文件的内容
对文件的一般操作是使用文件库中可用的方法执行的。 对于文件的读取,我们需要首先使用open操作,然后使用read操作作为文件库的一部分。 以下是这两种方法的语法。
语法 (Syntax)
- 打开文件 - 打开(文件,模式)
- 读取文件 - 读取(FileHandler,NumberofBytes)
参数 (Parameters)
File - 这是需要打开的文件的位置。
Mode - 这是需要打开文件的模式。
以下是一些可用的模式 -
Read - 打开必须存在的文件以供阅读。
Write - 打开文件进行写入。 如果它不存在,则创建它。 如果文件存在,并且如果write不与read结合,则文件将被截断。
Append - 将打开文件进行写入,如果文件不存在,将创建该文件。 对append打开的文件的每个写操作都将在文件末尾进行。
Exclusive - 如果文件不存在,则会在打开以进行写入时创建该文件。 如果文件存在,open将返回{error,exist}。
FileHandler - 这是文件的句柄。 此句柄是在使用file:open操作时返回的句柄。
NumberofByte - 这是需要从文件中读取的信息的字节数。
返回值 (Return Value)
Open(File,Mode) - 如果操作成功,则返回文件的句柄。
read(FileHandler,NumberofBytes) - 从文件返回请求的读取信息。
例如 (For example)
-module(helloworld).
-export([start/0]).
start() ->
{ok, File} = file:open("Newfile.txt",[read]),
Txt = file:read(File,1024 * 1024),
io:fwrite("~p~n",[Txt]).
Output - 当我们运行上述程序时,我们将得到以下结果。
Example1
现在让我们讨论一些可用于文件操作的其他方法 -
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 可用于允许一次读取文件的所有内容。 |
| 2 | 用于将内容写入文件。 |
| 3 | 用于制作现有文件的副本。 |
| 4 | 此方法用于删除现有文件。 |
| 5 | 此方法用于列出特定目录的内容。 |
| 6 | 此方法用于创建新目录。 |
| 7 | 此方法用于重命名现有文件。 |
| 8 | 此方法用于确定文件的大小。 |
| 9 | 此方法用于确定文件是否确实是文件。 |
| 10 | 此方法用于确定目录是否确实是目录。 |
Erlang - Atoms
原子是文字,是名称的常量。 如果原子不是以小写字母开头,或者如果它包含除字母数字字符,下划线(_)或@之外的其他字符,则用单引号(')括起来。
以下程序是如何在Erlang中使用原子的示例。 该程序分别声明3个原子,atom1,atom_1和'atom 1'。 所以你可以看到原子声明的不同方式。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite(atom1),
io:fwrite("~n"),
io:fwrite(atom_1),
io:fwrite("~n"),
io:fwrite('atom 1'),
io:fwrite("~n").
上述计划的产出如下 -
输出 (Output)
atom1
atom_1
atom 1
让我们看一下Erlang中可用于处理原子的一些方法。
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 该方法用于确定术语是否确实是原子。 |
| 2 | 此方法用于将原子转换为列表。 |
| 3 | 此方法用于将列表项转换为atom。 |
| 4 | 此方法用于将原子转换为二进制值。 |
| 5 | 此方法用于将二进制值转换为原子值。 |
Erlang - Maps
映射是具有可变数量的键 - 值关联的复合数据类型。 映射中的每个键值关联称为关联对。 该对的键和值部分称为元素。 关联对的数量被称为地图的大小。
以下程序中显示了如何使用Map数据类型的示例。
这里我们定义一个有两个映射的Map M1。 map_size是Erlang中定义的内置函数,可用于确定地图的大小。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
M1 = #{name=>john,age=>25},
io:fwrite("~w",[map_size(M1)]).
上述程序的输出如下。
输出 (Output)
2
可用于地图的一些其他方法如下。
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 此方法用于从列表生成映射。 |
| 2 | 此方法用于查找地图中是否存在特定键。 |
| 3 | 此方法用于获取地图中特定键的值。 |
| 4 | 此方法用于确定特定键是否被定义为映射中的键。 |
| 5 | 此方法用于从地图返回所有键。 |
| 6 | 此方法用于合并2个地图。 |
| 7 | 此方法用于向地图添加键值对。 |
| 8 | 此方法用于返回地图中的所有值。 |
| 9 | 此方法用于从地图中删除键值。 |
Erlang - Tuples
元组是具有固定数量项的复合数据类型。 元组中的每个术语称为元素。 元素的数量据说是元组的大小。
以下程序中显示了如何使用元组数据类型的示例。
这里我们定义一个有3个术语的Tuple P tuple_size是Erlang中定义的内置函数,可用于确定元组的大小。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
P = {john,24,{june,25}} ,
io:fwrite("~w",[tuple_size(P)]).
上述程序的输出如下。
输出 (Output)
3
让我们看看一些可用于元组的操作。
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 此方法用于确定提供的术语确实是一个元组。 |
| 2 | 此方法是将列表转换为元组。 |
| 3 | 此方法将元组转换为列表。 |
Erlang - Records
Erlang有额外的工具来创建记录。 这些记录由字段组成。 例如,您可以定义一个包含2个字段的个人记录,一个是id,另一个是name字段。 在Erlang中,您可以创建此记录的各种实例,以定义具有各种名称和ID的多个人。
让我们探讨如何使用记录。
创建记录
使用记录标识符创建记录。 在此记录标识符中,您指定构成记录的各个字段。 一般语法和示例如下。
语法 (Syntax)
record(recordname , {Field1,Field2 ..Fieldn})
参数 (Parameters)
recordname - 这是给记录的名称。
Field1,Field2 ..Fieldn - 这些是构成记录的各个字段的列表。
返回值 (Return Value)
没有
例如 (For example)
-module(helloworld).
-export([start/0]).
-record(person, {name = "", id}).
start() ->
P = #person{name="John",id = 1}.
上面的示例显示了包含2个字段的记录的定义,一个是id,另一个是名称。 此外,记录按以下方式构建 -
语法 (Syntax)
#recordname {fieldName1 = value1, fieldName2 = value2 .. fieldNameN = valueN}
在定义记录实例时,将值分配给相应字段的位置。
访问记录的值
要访问特定记录的字段和值,应使用以下语法。
语法 (Syntax)
#recordname.Fieldname
参数 (Parameters)
recordname - 这是给记录的名称。
Fieldname - 这是需要访问的字段的名称。
返回值 (Return Value)
分配给该字段的值。
例如 (For example)
-module(helloworld).
-export([start/0]).
-record(person, {name = "", id}).
start() ->
P = #person{name = "John",id = 1},
io:fwrite("~p~n",[P#person.id]),
io:fwrite("~p~n",[P#person.name]).
输出 (Output)
上述程序的输出如下。
1
“John”
更新记录的值
通过将值更改为特定字段然后将记录分配给新变量名来完成记录值的更新。 一般语法和示例如下。
语法 (Syntax)
#recordname.Fieldname = newvalue
参数 (Parameters)
recordname - 这是给记录的名称。
Fieldname - 这是需要访问的字段的名称。
newvalue - 这是需要分配给字段的新值。
返回值 (Return Value)
具有分配给字段的新值的新记录。
例如 (For example)
-module(helloworld).
-export([start/0]).
-record(person, {name = "", id}).
start() ->
P = #person{name = "John",id = 1},
P1 = P#person{name = "Dan"},
io:fwrite("~p~n",[P1#person.id]),
io:fwrite("~p~n",[P1#person.name]).
输出 (Output)
上述计划的输出如下 -
1
“Dan”
嵌套记录
Erlang还具有嵌套记录的功能。 以下示例显示如何创建这些嵌套记录。
例如 (For example)
-module(helloworld).
-export([start/0]).
-record(person, {name = "", address}).
-record(employee, {person, id}).
start() ->
P = #employee{person = #person{name = "John",address = "A"},id = 1},
io:fwrite("~p~n",[P#employee.id]).
在上面的例子中,需要注意以下事项 -
我们首先创建一个人的记录,其中包含姓名和地址的字段值。
然后,我们定义一个员工记录,其中该人员为字段,另一个字段为id。
输出 (Output)
上述程序的输出如下。
1
Erlang - Exceptions
任何编程语言都需要异常处理来处理运行时错误,以便可以保持应用程序的正常流程。 异常通常会破坏应用程序的正常流程,这就是我们需要在应用程序中使用异常处理的原因。
通常,当Erlang中发生异常或错误时,将显示以下消息。
{"init terminating in do_boot", {undef,[{helloworld,start,[],[]},
{init,start_it,1,[]},{init,start_em,1,[]}]}}
崩溃转储将被写入 -
erl_crash.dump
init terminating in do_boot ()
在Erlang中,有3种类型的例外 -
Error - 调用erlang:error(Reason)将结束当前进程中的执行,并包含当您捕获它们时使用其参数调用的最后函数的堆栈跟踪。 这些是引发上述运行时错误的异常。
Exists - 退出有两种:“内部”退出和“外部”退出。 通过调用函数exit/1触发内部退出,并使当前进程停止执行。 外部出口使用exit/2调用,并且与Erlang的并发方面中的多个进程有关。
Throw - 抛出是一类异常,用于程序员可以处理的情况。 与出口和错误相比,他们并没有真正承担任何“崩溃过程!” 他们背后的意图,而是他们控制流量。 当您在期望程序员处理它们的同时使用throws时,通常最好在使用它们的模块中记录它们的使用。
try ... catch是一种评估表达式的方法,同时让您处理成功的案例以及遇到的错误。
try catch表达式的一般语法如下。
语法 (Syntax)
<b class="notranslate">try</b> Expression of
SuccessfulPattern1 [Guards] ->
Expression1;
SuccessfulPattern2 [Guards] ->
Expression2
<b class="notranslate">catch</b>
TypeOfError:ExceptionPattern1 ->
Expression3;
TypeOfError:ExceptionPattern2 ->
Expression4
<b class="notranslate">end</b>
在try and of之间的表达被认为是受到保护的。 这意味着将捕获该调用中发生的任何类型的异常。 try ... of and catch之间的模式和表达式的行为方式与case ... of完全相同。
最后,catch部分 - 在这里,您可以通过error,throw或exit替换TypeOfError ,对于我们在本章中看到的每个相应类型。 如果没有提供类型,则假定抛出。
以下是Erlang中的一些错误和错误原因 -
| 错误 | 错误类型 |
|---|---|
| badarg | 不好的论点。 参数是错误的数据类型,或者是否形成错误。 |
| badarith | 算术表达式中的错误参数。 |
| {badmatch,V} | 评估匹配表达式失败。 值V不匹配。 |
| function_clause | 在评估函数调用时,找不到匹配的函数子句。 |
| {case_clause,V} | 在评估案例表达式时,找不到匹配的分支。 值V不匹配。 |
| if_clause | 在评估if表达式时,找不到真正的分支。 |
| {try_clause,V} | 在评估try表达式的section部分时,找不到匹配的分支。 值V不匹配。 |
| undef | 评估函数调用时找不到该函数。 |
| {badfun,F} | 有趣的F有点不对劲 |
| {badarity,F} | 乐趣适用于错误数量的参数。 F描述了乐趣和论点。 |
| timeout_value | receive..after表达式中的超时值被计算为除整数或无穷大之外的值。 |
| noproc | 尝试链接到不存在的进程。 |
以下是如何使用这些异常以及如何完成任务的示例。
第一个函数生成所有可能的异常类型。
然后我们编写一个包装函数来在try ... catch表达式中调用generate_exception 。
例子 (Example)
-module(helloworld).
-compile(export_all).
generate_exception(1) -> a;
generate_exception(2) -> throw(a);
generate_exception(3) -> exit(a);
generate_exception(4) -> {'EXIT', a};
generate_exception(5) -> erlang:error(a).
demo1() ->
[catcher(I) || I <- [1,2,3,4,5]].
catcher(N) ->
try generate_exception(N) of
Val -> {N, normal, Val}
catch
throw:X -> {N, caught, thrown, X};
exit:X -> {N, caught, exited, X};
error:X -> {N, caught, error, X}
end.
demo2() ->
[{I, (catch generate_exception(I))} || I <- [1,2,3,4,5]].
demo3() ->
try generate_exception(5)
catch
error:X ->
{X, erlang:get_stacktrace()}
end.
lookup(N) ->
case(N) of
1 -> {'EXIT', a};
2 -> exit(a)
end.
如果我们将程序作为helloworld运行:demo()。 ,我们将获得以下输出 -
输出 (Output)
[{1,normal,a},
{2,caught,thrown,a},
{3,caught,exited,a},
{4,normal,{'EXIT',a}},
{5,caught,error,a}]
Erlang - Macros
宏通常用于内联代码替换。 在Erlang中,宏通过以下语句定义。
- -define(Constant, Replacement).
- -define(Func(Var1, Var2,.., Var), Replacement).
以下是使用第一种语法的宏示例 -
例子 (Example)
-module(helloworld).
-export([start/0]).
-define(a,1).
start() ->
io:fwrite("~w",[?a]).
从上面的程序中你可以看到使用'?'扩展宏 符号。 常量由宏中定义的值替换。
上述计划的输出将是 -
输出 (Output)
1
使用函数类的宏的示例如下 -
例子 (Example)
-module(helloworld).
-export([start/0]).
-define(macro1(X,Y),{X+Y}).
start() ->
io:fwrite("~w",[?macro1(1,2)]).
上述计划的输出将是 -
输出 (Output)
{3}
以下附加语句可用于宏 -
undef(Macro) - 取消定义宏; 在此之后你无法调用宏。
ifdef(Macro) - 仅在定义了宏时才评估以下行。
ifndef(Macro) - 仅当未定义宏时才评估以下行。
else - 在ifdef或ifndef语句之后允许。 如果条件为false,则评估其他语句。
endif - 标记ifdef或ifndef语句的结尾。
使用上述语句时,应以正确的方式使用它,如以下程序所示。
-ifdef(<FlagName>).
-define(...).
-else.
-define(...).
-endif.
Erlang - Header Files
头文件就像包含任何其他编程语言的文件一样。 将模块拆分为不同的文件然后将这些头文件访问到单独的程序中非常有用。 要查看正在运行的头文件,让我们看看我们之前的一个记录示例。
让我们首先创建一个名为user.hrl的文件并添加以下代码 -
-record(person, {name = "", id}).
现在在我们的主程序文件中,让我们添加以下代码 -
例子 (Example)
-module(helloworld).
-export([start/0]).
-include("user.hrl").
start() ->
P = #person{name = "John",id = 1},
io:fwrite("~p~n",[P#person.id]),
io:fwrite("~p~n",[P#person.name]).
从上面的程序中可以看出,我们实际上只包含user.hrl文件,该文件会自动在其中插入–record代码。
如果执行上述程序,您将获得以下输出。
输出 (Output)
1
“John”
您也可以使用宏执行相同的操作,您可以在头文件中定义宏并在主文件中引用它。 让我们看看这个例子 -
让我们首先创建一个名为user.hrl的文件并添加以下代码 -
-define(macro1(X,Y),{X+Y}).
现在在我们的主程序文件中,让我们添加以下代码 -
例子 (Example)
-module(helloworld).
-export([start/0]).
-include("user.hrl").
start() ->
io:fwrite("~w",[?macro1(1,2)]).
如果执行上述程序,您将获得以下输出 -
输出 (Output)
{3}
Erlang - Preprocessors
在编译Erlang模块之前,它由Erlang预处理器自动处理。 预处理器扩展可能在源文件中的任何宏,并插入任何必要的包含文件。
通常,您不需要查看预处理器的输出,但在特殊情况下(例如,在调试有故障的宏时),您可能希望保存预处理器的输出。 要查看预处理模块的结果, some_module.erl给出OS shell命令。
erlc -P some_module.erl
例如,假设我们有以下代码文件 -
例子 (Example)
-module(helloworld).
-export([start/0]).
-include("user.hrl").
start() ->
io:fwrite("~w",[?macro1(1,2)]).
如果我们从命令行执行以下命令 -
erlc –P helloworld.erl
将生成一个名为helloworld.P的文件。 如果您打开此文件,您将找到以下内容,这是预处理器将编译的内容。
-file("helloworld.erl", 1). -module(helloworld).
-export([start/0]).
-file("user.hrl", 1).
-file("helloworld.erl", 3).
start() ->
io:fwrite("~w", [{1 + 2}]).
Erlang - Pattern Matching
模式看起来与术语相同 - 它们可以是简单的文字,如原子和数字,复合像元组和列表,或两者的混合。 它们还可以包含变量,这些变量是以大写字母或下划线开头的字母数字字符串。 当您不关心要匹配的值时,将使用一个特殊的“匿名变量”_(下划线),并且不会使用它。
如果模式与匹配的术语具有相同的“形状”,并且遇到的原子相同,则匹配模式。 例如,以下匹配成功 -
- B = 1。
- 2 = 2。
- {ok,C} = {ok,40}。
- [H | T] = [1,2,3,4]。
请注意,在第四个示例中,管道(|)表示列表的头部和尾部,如术语中所述。 另请注意,左侧应与右侧匹配,这是图案的正常情况。
以下模式匹配示例将失败。
- 1 = 2。
- {ok,A} = {失败,“不知道问题”}。
- [H | T] = []。
在模式匹配运算符的情况下,失败会生成错误并且进程退出。 错误中包含了如何捕获和处理它的方法。 模式用于选择将执行函数的哪个子句。
Erlang - Guards
防护是我们可以用来增加模式匹配能力的结构。 使用警卫,我们可以对模式中的变量执行简单的测试和比较。
guard语句的一般语法如下 -
function(parameter) when condition ->
Where,
Function(parameter) - 这是保护条件中使用的函数声明。
Parameter - 通常保护条件基于参数。
Condition - 应该评估的条件,以查看是否应该执行该函数。
指定保护条件时,必须使用when语句。
让我们看一下如何使用防护装置的快速示例 -
例子 (Example)
-module(helloworld).
-export([display/1,start/0]).
display(N) when N > 10 ->
io:fwrite("greater then 10");
display(N) when N < 10 -> io:fwrite("Less
than 10").
start() ->
display(11).
关于上面的例子需要注意以下事项 -
显示功能与防护装置一起定义。 第一个显示声明具有参数N大于10的保护。因此,如果参数大于10,则将调用该函数。
显示功能再次定义,但这次使用小于10的保护。这样,您可以多次定义相同的功能,每个功能都有一个单独的保护条件。
上述计划的输出如下 -
输出 (Output)
greater than 10
保护条件也可用于if else和case语句。 让我们看看我们如何对这些陈述进行守卫操作。
“if”声明的警卫
防护也可以用于if语句,以便执行的一系列语句基于保护条件。 让我们看看我们如何实现这一目标。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
N = 9,
if
N > 10 ->
io:fwrite("N is greater than 10");
true ->
io:fwrite("N is less than 10")
end.
关于上面的例子需要注意以下事项 -
guard函数与if语句一起使用。 如果guard函数的计算结果为true,则显示语句“N大于10”。
如果保护功能评估为假,则显示语句“N小于10”。
上述计划的输出如下 -
输出 (Output)
N is less than 10
“案件”陈述的警卫
防护也可用于案例陈述,以便执行的一系列陈述基于保护条件。 让我们看看我们如何实现这一目标。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
A = 9,
case A of {A} when A>10 ->
io:fwrite("The value of A is greater than 10"); _ ->
io:fwrite("The value of A is less than 10")
end.
关于上面的例子需要注意以下事项 -
guard函数与case语句一起使用。 如果guard函数的计算结果为true,则显示“A的值大于10”的语句。
如果保护功能评估为其他任何内容,则显示“A的值小于10”的语句。
上述计划的输出如下 -
输出 (Output)
The value of A is less than 10
多重防护条件
还可以为功能指定多个保护条件。 具有多个保护条件的guard语句的一般语法如下 -
function(parameter) when condition1 , condition1 , .. conditionN ->
Where,
Function(parameter) - 这是使用保护条件的函数声明。
Parameter - 通常保护条件基于参数。
condition1, condition1, .. conditionN - 这些是应用于函数的多重保护条件。
指定保护条件时,必须使用when语句。
让我们看一下如何使用多个防护装置的快速示例 -
例子 (Example)
-module(helloworld).
-export([display/1,start/0]).
display(N) when N > 10 , is_integer(N) ->
io:fwrite("greater then 10");
display(N) when N < 10 ->
io:fwrite("Less than 10").
start() ->
display(11).
关于上述例子,需要注意以下几点 -
您会注意到,对于第一个显示函数声明,除了N> 10的条件外,还指定了is_integer的条件。 因此,只有当N的值是一个整数且大于10时,才会执行该函数。
上述计划的输出如下 -
输出 (Output)
Greater than 10
Erlang - BIFS
BIF是Erlang内置的函数。 他们通常会执行无法在Erlang中编程的任务。 例如,无法将列表转换为元组或查找当前时间和日期。 为了执行这样的操作,我们称之为BIF。
让我们举一个如何使用BIF的例子 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~p~n",[tuple_to_list({1,2,3})]),
io:fwrite("~p~n",[time()]).
关于上面的例子需要注意以下事项 -
在第一个示例中,我们使用名为tuple_to_list的BIF将元组转换为列表。
在第二个BIF函数中,我们使用time function输出系统时间。
上述计划的输出如下 -
输出 (Output)
[1,2,3]
{10,54,56}
让我们看一下Erlang中可用的一些BIF函数。
| Sr.No. | BIF功能和说明 |
|---|---|
| 1 | 此方法返回当前系统日期。 |
| 2 | 此方法返回Bitstring中包含的字节数。 |
| 3 | 该方法返回元组中的第N个元素。 |
| 4 | 此方法返回特定数字的浮点值。 |
| 5 | 该方法将进程字典作为列表返回。 |
| 6 | 此方法用于在流程字典中放置key,value对。 |
| 7 | 该方法用于给出系统中的本地日期和时间。 |
| 8 | 返回一个列表,其中包含有关Erlang仿真器动态分配的内存的信息。 |
| 9 | 此方法返回元组{MegaSecs,Secs,MicroSecs},这是自1970年1月1日格林尼治标准时间00:00起经过的时间。 |
| 10 | 返回本地节点上所有端口的列表 |
| 11 | 返回与本地节点上当前存在的所有进程相对应的进程标识符列表。 |
| 12 | 根据协调世界时(UTC)返回当前日期和时间。 |
Erlang - Binaries
使用称为二进制的数据结构来存储大量原始数据。 二进制文件以比列表或元组更加节省空间的方式存储数据,并且运行时系统针对二进制文件的有效输入和输出进行了优化。
二进制文件以整数或字符串的顺序编写和打印,用小于或大于括号的双精度括起来。
以下是Erlang中二进制文件的示例 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~p~n",[<<5,10,20>>]),
io:fwrite("~p~n",[<<"hello">>]).
当我们运行上述程序时,我们将得到以下结果。
输出 (Output)
<<5,10,20>>
<<"hello">>
让我们看看可用于二进制文件的Erlang函数 -
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 此方法用于将现有列表转换为二进制文件列表。 |
| 2 | 此方法用于根据指定的索引位置拆分二进制列表。 |
| 3 | 此方法用于将术语转换为二进制。 |
| 4 | 此方法用于检查位串是否确实是二进制值。 |
| 5 | 此方法用于提取二进制字符串的一部分 |
| 6 | 此方法用于将二进制值转换为浮点值。 |
| 7 | 此方法用于将二进制值转换为整数值。 |
| 8 | 此方法用于将二进制值转换为列表。 |
| 9 | 此方法用于将二进制值转换为原子。 |
Erlang - Funs
Funs用于在Erlang中定义匿名函数。 匿名函数的一般语法如下 -
语法 (Syntax)
F = fun (Arg1, Arg2, ... ArgN) ->
...
End
哪里
F - 这是分配给匿名函数的变量名。
Arg1, Arg2, ... ArgN - 这些是传递给匿名函数的参数。
以下示例展示了如何使用匿名函数。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
A = fun() -> io:fwrite("Hello") end,
A().
关于上述程序需要注意以下事项。
匿名函数被赋值给变量A.
匿名函数通过变量A()。
当我们运行上述程序时,我们将得到以下结果。
“Hello”
匿名函数的另一个例子如下,但这是使用参数。
-module(helloworld).
-export([start/0]).
start() ->
A = fun(X) ->
io:fwrite("~p~n",[X])
end,
A(5).
当我们运行上述程序时,我们将得到以下结果。
输出 (Output)
5
使用变量
匿名函数能够访问匿名函数范围之外的变量。 让我们看看这个例子 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
B = 6,
A = fun(X) ->
io:fwrite("~p~n",[X]),
io:fwrite("~p~n",[B])
end,
A(5).
关于上述程序需要注意以下事项。
变量B超出了匿名函数的范围。
匿名函数仍然可以访问全局范围中定义的变量。
当我们运行上述程序时,我们将得到以下结果。
输出 (Output)
5
6
Functions within Functions
高阶函数的另一个最强大的方面是,您可以在函数内定义函数。 让我们看一个如何实现这一目标的例子。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
Adder = fun(X) -> fun(Y) -> io:fwrite("~p~n",[X + Y]) end end,
A = Adder(6),
A(10).
关于上述程序需要注意以下事项。
加法器是一个定义为fun(X)的高阶函数。
Adder函数fun(X)引用另一个函数fun(Y)。
当我们运行上述程序时,我们将得到以下结果。
输出 (Output)
16
Erlang - Processes
Erlang中的并发粒度是一个过程。 进程是与其他进程同时运行并独立于其他进程的活动/任务。 Erlang中的这些进程与大多数人熟悉的进程和线程不同。 Erlang进程是轻量级的,在(内存)与其他进程隔离的情况下运行,并由Erlang的虚拟机(VM)调度。 进程的创建时间非常短,刚生成的进程的内存占用非常小,并且单个Erlang VM可以运行数百万个进程。
在spawn方法的帮助下创建一个进程。 该方法的一般语法如下。
语法 (Syntax)
spawn(Module, Name, Args)
参数 (Parameters)
Module - 这是一个预定义的原子值,必须是?MODULE。
Name - 这是定义进程时要调用的函数的名称。
Args - 这些是需要发送给函数的参数。
返回值 (Return Value)
返回创建的新进程的进程ID。
例如 (For example)
以下程序中显示了spawn方法的示例。
-module(helloworld).
-export([start/0, call/2]).
call(Arg1, Arg2) ->
io:format("~p ~p~n", [Arg1, Arg2]).
start() ->
Pid = spawn(?MODULE, call, ["hello", "process"]),
io:fwrite("~p",[Pid]).
关于上述程序需要注意以下事项。
定义了一个名为call的函数,它将用于创建进程。
spawn方法使用参数hello和process调用call函数。
输出 (Output)
当我们运行上述程序时,我们将得到以下结果。
<0.29.0>"hello" "process"
现在让我们看一下流程可用的其他功能。
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 此方法用于确定进程ID是否存在。 |
| 2 | 这称为is_process_alive(Pid)。 Pid必须引用本地节点上的进程。 |
| 3 | 它将进程ID转换为列表。 |
| 4 | 返回包含所有已注册进程名称的列表。 |
| 5 | 最常用的BIF之一,返回调用进程的pid。 |
| 6 | 这用于在系统中注册进程。 |
| 7 | 它被称为whereis(Name)。 返回使用名称注册的进程的pid。 |
| 8 | 这用于取消注册系统中的进程。 |
Erlang - Email
要使用Erlang发送电子邮件,您需要使用github提供的相同包。 github链接是 - https://github.com/Vagabond/gen_smtp
此链接包含一个smtp utility ,可用于从Erlang应用程序发送电子邮件。 按照步骤,可以从Erlang发送电子邮件
Step 1 - 从github site下载erl files 。 应将这些文件下载到helloworld.erl应用程序所在的目录中。
Step 2 - 使用erlc command编译以下列表中显示的所有smtp related files 。 需要编译以下文件。
- smtp_util
- gen_smtp_client
- gen_smtp_server
- gen_smtp_server_session
- binstr
- gen_smtp_application
- socket
Step 3 - 可以编写以下代码以使用smtp发送电子邮件。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
gen_smtp_client:send({"sender@gmail.com", ["receiver@gmail.com"], "Subject: testing"},
[{relay, "smtp.gmail.com"}, {ssl, true}, {username, "sender@gmail.com"},
{password, "senderpassword"}]).
关于上述程序需要注意以下事项
上面的smtp功能与谷歌提供的smtp服务器一起使用。
由于我们希望使用安全smtp发送,因此我们将ssl参数指定为true。
您需要将中继指定为smtp.gmail.com 。
您需要提及有权发送电子邮件的用户名和密码。
配置完所有上述设置并执行程序后,接收器将成功接收电子邮件。
Erlang - Databases
Erlang能够连接到传统的数据库,如SQL Server和Oracle。 Erlang有一个inbuilt odbc library ,可用于处理数据库。
数据库连接 (Database Connection)
在我们的示例中,我们将使用Microsoft SQL Server。 在连接到Microsoft SQL Server数据库之前,请确保选中以下指针。
您已经创建了一个数据库TESTDB。
您已在TESTDB中创建了一个表EMPLOYEE。
此表包含FIRST_NAME,LAST_NAME,AGE,SEX和INCOME字段。
用户ID“testuser”和密码“test123”设置为访问TESTDB。
确保已创建名为usersqlserver的ODBC DSN,该DSN将创建与数据库的ODBC连接
建立连接
要建立与数据库的连接,可以使用以下代码示例。
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver;UID = testuser;PWD = test123", []),
io:fwrite("~p",[Ref]).
上述计划的输出如下 -
Output
<0.33.0>
关于上述程序需要注意以下事项。
odbc库的start方法用于指示数据库操作的开始。
connect方法需要DSN,用户名和密码才能连接。
创建数据库表
连接到数据库后的下一步是在数据库中创建表。 以下示例说明如何使用Erlang在数据库中创建表。
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123, []),
odbc:sql_query(Ref, "CREATE TABLE EMPLOYEE (FIRSTNAME char varying(20),
LASTNAME char varying(20), AGE integer, SEX char(1), INCOME integer)")
如果现在检查数据库,您将看到将创建一个名为EMPLOYEE的表。
将记录插入数据库
当您想要将记录创建到数据库表中时,它是必需的。
以下示例将在employee表中插入记录。 如果表已成功更新,则记录和语句将返回更新记录的值和已更新的记录数。
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123", []),
io:fwrite("~p",[odbc:sql_query(Ref,
"INSERT INTO EMPLOYEE VALUES('Mac', 'Mohan', 20, 'M', 2000)")]).
上述计划的输出将是 -
Output
{updated,1}
从数据库中获取记录
Erlang还具有从数据库中获取记录的功能。 这是通过sql_query method完成的。
以下程序中显示了一个示例 -
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123", []),
io:fwrite("~p",[odbc:sql_query(Ref, "SELECT * FROM EMPLOYEE") ]).
上述计划的输出如下 -
Output
{selected,["FIRSTNAME","LASTNAME","AGE","SEX","INCOME"],
[{"Mac","Mohan",20,"M",2000}]}
因此,您可以看到上一部分中的insert命令有效,而select命令返回了正确的数据。
基于参数从数据库中获取记录
Erlang还具有根据某些过滤条件从数据库中获取记录的功能。
一个例子如下 -
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN=usersqlserver; UID=testuser;PWD=test123", []),
io:fwrite("~p",[ odbc:param_query(Ref, "SELECT * FROM EMPLOYEE WHERE SEX=?",
[{{sql_char, 1}, ["M"]}])]).
上述计划的输出将是 -
Output
{selected,["FIRSTNAME","LASTNAME","AGE","SEX","INCOME"],
[{"Mac","Mohan",20,"M",2000}]}
从数据库更新记录
Erlang还具有从数据库更新记录的功能。
一个例子如下 -
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123", []),
io:fwrite("~p",[ odbc:sql_query(Ref, "
UPDATE EMPLOYEE SET AGE = 5 WHERE INCOME= 2000")]).
上述计划的输出将是 -
Output
{updated,1}
从数据库中删除记录
Erlang还具有从数据库中删除记录的功能。
一个例子如下 -
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123", []),
io:fwrite("~p",[ odbc:sql_query(Ref, "DELETE EMPLOYEE WHERE INCOME= 2000")]).
上述计划的输出如下 -
Output
{updated,1}
表结构
Erlang还具有描述表结构的能力。
一个例子如下 -
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = testuser;PWD = test123", []),
io:fwrite("~p",[odbc:describe_table(Ref, "EMPLOYEE")]).
上述计划的输出如下 -
Output
{ok,[{"FIRSTNAME",{sql_varchar,20}},
{"LASTNAME",{sql_varchar,20}},
{"AGE",sql_integer},
{"SEX",{sql_char,1}},
{"INCOME",sql_integer}]}
记录计数
Erlang还具有获取表中记录总数的功能。
以下程序显示了相同的示例。
Example
-module(helloworld).
-export([start/0]).
start() ->
odbc:start(),
{ok, Ref} = odbc:connect("DSN = usersqlserver; UID = sa;PWD = demo123", []),
io:fwrite("~p",[odbc:select_count(Ref, "SELECT * FROM EMPLOYEE")]).
上述计划的输出将是 -
{ok,1}
Erlang - Ports
在Erlang中,端口用于不同程序之间的通信。 套接字是一种通信端点,允许计算机使用Internet协议(IP)通过Internet进行通信。
端口使用的协议类型
有两种类型的协议可用于通信。 一个是UDP,另一个是TCP。 UDP允许应用程序相互发送短消息(称为数据报),但不保证这些消息的传递。 它们也可能无序到达。 另一方面,TCP提供可靠的字节流,只要建立连接就按顺序传送。
让我们看一个使用UDP打开端口的简单示例。
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
{ok, Socket} = gen_udp:open(8789),
io:fwrite("~p",[Socket]).
关于上述程序需要注意以下事项
gen_udp包含用于UDP通信的Erlang中的模块。
这里8789是在Erlang打开的端口号。 您需要确保此端口号可用且可以使用。
上述计划的输出是 -
#Port<0.376>
在端口上发送消息
打开端口后,可以在端口上发送消息。 这是通过send方法完成的。 我们来看一下语法和下面的例子。
语法 (Syntax)
send(Socket, Address, Port, Packet)
参数 (Parameters)
Socket - 这是使用gen_udp:open命令创建的套接字。
Address - 这是必须将消息发送到的机器地址。
port - 这是需要发送消息的端口号。
Packet - 这是需要发送的数据包或消息详细信息。
返回值 (Return Values)
如果消息已正确发送,则会返回ok消息。
例如 (For example)
-module(helloworld).
-export([start/0]).
start() ->
{ok, Socket} = gen_udp:open(8789),
io:fwrite("~p",[Socket]),
io:fwrite("~p",[gen_udp:send
(Socket,"localhost",8789,"Hello")]).
输出 (Output)
上述程序的输出如下。
#Port<0.376>ok
在端口上接收消息
打开端口后,也可以在端口上接收消息。 这是通过recv method完成的。 我们来看一下语法和下面的例子。
语法 (Syntax)
recv(Socket, length)
参数 (Parameters)
Socket - 这是使用gen_udp:open命令创建的套接字。
Length - 这是需要接收的消息的长度。
返回值 (Return Values)
如果消息已正确发送,则会返回ok消息。
例如 (For example)
-module(helloworld).
-export([start/0]).
start() ->
{ok, Socket} = gen_udp:open(8789),
io:fwrite("~p",[Socket]),
io:fwrite("~p",[gen_udp:send(Socket,"localhost",8789,"Hello")]),
io:fwrite("~p",[gen_udp:recv(Socket, 20)]).
完整计划
现在显然我们不能在同一个程序中拥有相同的发送和接收消息。 您需要在不同的程序中定义它们。 因此,让我们创建以下代码,该代码创建一个侦听消息的服务器组件和一个发送消息的客户端组件。
例子 (Example)
-module(helloworld).
-export([start/0,client/1]).
start() ->
spawn(fun() -> server(4000) end).
server(Port) ->
{ok, Socket} = gen_udp:open(Port, [binary, {active, false}]),
io:format("server opened socket:~p~n",[Socket]),
loop(Socket).
loop(Socket) ->
inet:setopts(Socket, [{active, once}]),
receive
{udp, Socket, Host, Port, Bin} ->
io:format("server received:~p~n",[Bin]),
gen_udp:send(Socket, Host, Port, Bin),
loop(Socket)
end.
client(N) ->
{ok, Socket} = gen_udp:open(0, [binary]),
io:format("client opened socket=~p~n",[Socket]),
ok = gen_udp:send(Socket, "localhost", 4000, N), Value = receive
{udp, Socket, _, _, Bin} ->
io:format("client received:~p~n",[Bin]) after 2000 ->
0
end,
gen_udp:close(Socket),
Value.
关于上述程序需要注意以下事项。
我们定义了2个函数,第一个是服务器。 这将用于侦听端口4000.第二个是用于将消息“Hello”发送到服务器组件的客户端。
接收循环用于读取定义循环内发送的消息。
输出 (Output)
现在您需要从2个窗口运行该程序。 第一个窗口将用于通过在erl command line window运行以下代码来运行服务器组件。
helloworld:start().
这将在命令行窗口中显示以下输出。
server opened socket:#Port<0.2314>
现在,在第二个erl命令行窗口中,运行以下命令。
Helloworld:client(“<<Hello>>”).
发出此命令时,将在第一个命令行窗口中显示以下输出。
server received:<<"Hello">>
Erlang - Distributed Programming
分布式程序是那些旨在在计算机网络上运行并且只能通过消息传递协调其活动的程序。
我们可能想要编写分布式应用程序的原因有很多。 这里是其中的一些。
Performance - 我们可以通过安排程序的不同部分在不同的机器上并行运行来使程序更快。
Reliability - 我们可以通过将系统结构化以在多台机器上运行来制造容错系统。 如果一台机器出现故障,我们可以继续使用另一台机器
Scalability - 随着我们扩展应用程序,我们迟早会耗尽即使是最强大的机器的功能。 在这个阶段,我们必须添加更多的机器来增加容量。 添加新计算机应该是一项简单的操作,不需要对应用程序体系结构进行大的更改。
分布式Erlang的核心概念是节点。 节点是一个独立的节点。
Erlang系统包含一个完整的虚拟机,它有自己的地址空间和自己的一组进程。
让我们看看用于Distributed Programming的不同methods 。
| Sr.No. | 方法和描述 |
|---|---|
| 1 | 这用于创建新进程并对其进行初始化。 |
| 2 | 这用于确定进程需要运行的节点的值。 |
| 3 | 这用于在节点上创建新进程。 |
| 4 | 如果本地节点处于活动状态并且可以是分布式系统的一部分,则返回true。 |
| 5 | 这用于在节点上创建新的流程链接。 |
Erlang - OTP
OTP代表开放电信平台。 它是一个应用程序操作系统和一组用于构建大规模,容错,分布式应用程序的库和过程。 如果您想使用OTP编写自己的应用程序,那么您将发现非常有用的核心概念是OTP行为。 行为封装了常见的行为模式 - 将其视为由回调模块参数化的应用程序框架。
OTP的强大功能来自于容错,可伸缩性,动态代码升级等属性,可以由行为本身提供。 因此,第一个基本概念是创建一个模仿OTP环境基础的服务器组件,让我们看一下相同的示例。
例子 (Example)
-module(server).
-export([start/2, rpc/2]).
start(Name, Mod) ->
register(Name, spawn(fun() -> loop(Name, Mod, Mod:init()) end)).
rpc(Name, Request) ->
Name ! {self(), Request},
receive
{Name, Response} -> Response
end.
loop(Name, Mod, State) ->
receive
{From, Request} ->
{Response, State1} = Mod:handle(Request, State),
From ! {Name, Response},
loop(Name, Mod, State1)
end.
关于上述计划需要注意以下事项 -
使用寄存器功能在系统中注册的过程。
该过程产生一个处理处理的循环函数。
现在让我们编写一个将使用服务器程序的客户端程序。
例子 (Example)
-module(name_server).
-export([init/0, add/2, whereis/1, handle/2]).
-import(server1, [rpc/2]).
add(Name, Place) -> rpc(name_server, {add, Name, Place}).
whereis(Name) -> rpc(name_server, {whereis, Name}).
init() -> dict:new().
handle({add, Name, Place}, Dict) -> {ok, dict:store(Name, Place, Dict)};
handle({whereis, Name}, Dict) -> {dict:find(Name, Dict), Dict}.
此代码实际执行两个任务。 它充当从服务器框架代码调用的回调模块,同时它包含将由客户端调用的接口例程。 通常的OTP约定是将两个函数组合在同一个模块中。
所以这里是如何运行上述程序 -
在erl ,首先运行以下命令来运行服务器程序。
server(name_server,name_server)
您将获得以下输出 -
输出 (Output)
true
然后,运行以下命令
name_server.add(erlang,”IoWiki”).
您将获得以下输出 -
输出 (Output)
Ok
然后,运行以下命令 -
name_server.whereis(erlang).
您将获得以下输出 -
输出 (Output)
{ok,"IoWiki"}
Erlang - Concurrency
Erlang中的并发编程需要具有以下基本原则或过程。
该清单包括以下原则 -
piD = spawn(Fun)
创建一个评估Fun的新并发进程。 新进程与调用者并行运行。 一个例子如下 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
spawn(fun() -> server("Hello") end).
server(Message) ->
io:fwrite("~p",[Message]).
上述计划的输出是 -
输出 (Output)
“Hello”
Pid! 信息
使用标识符Pid向进程发送消息。 消息发送是异步的。 发件人不会等待,而是继续其正在做的事情。 '!' 被称为发送运算符。
一个例子如下 -
例子 (Example)
-module(helloworld).
-export([start/0]).
start() ->
Pid = spawn(fun() -> server("Hello") end),
Pid ! {hello}.
server(Message) ->
io:fwrite("~p",[Message]).
Receive…end
接收已发送到进程的消息。 它具有以下语法 -
语法 (Syntax)
receive
Pattern1 [when Guard1] ->
Expressions1;
Pattern2 [when Guard2] ->
Expressions2;
...
End
当消息到达进程时,系统会尝试将其与Pattern1(可能的Guard Guard1)进行匹配; 如果成功,则评估Expressions1。 如果第一个模式不匹配,则尝试Pattern2,依此类推。 如果所有模式都不匹配,则保存该消息以供稍后处理,并且该过程等待下一条消息。
以下程序显示了包含所有3个命令的整个过程的示例。
例子 (Example)
-module(helloworld).
-export([loop/0,start/0]).
loop() ->
receive
{rectangle, Width, Ht} ->
io:fwrite("Area of rectangle is ~p~n" ,[Width * Ht]),
loop();
{circle, R} ->
io:fwrite("Area of circle is ~p~n" , [3.14159 * R * R]),
loop();
Other ->
io:fwrite("Unknown"),
loop()
end.
start() ->
Pid = spawn(fun() -> loop() end),
Pid ! {rectangle, 6, 10}.
关于上述计划需要注意以下事项 -
循环函数具有接收端循环。 因此,当发送消息时,它将由接收端循环处理。
产生了一个进入循环函数的新进程。
消息通过Pid发送到生成的进程! 消息命令。
上述计划的输出是 -
输出 (Output)
Area of the Rectangle is 60
最大进程数
在并发中,确定系统允许的最大进程数非常重要。 然后,您应该能够了解有多少进程可以在系统上并发执行。
让我们看一个如何确定可以在系统上执行的最大进程数的示例。
-module(helloworld).
-export([max/1,start/0]).
max(N) ->
Max = erlang:system_info(process_limit),
io:format("Maximum allowed processes:~p~n" ,[Max]),
statistics(runtime),
statistics(wall_clock),
L = for(1, N, fun() -> spawn(fun() -> wait() end) end),
{_, Time1} = statistics(runtime),
{_, Time2} = statistics(wall_clock), lists:foreach(fun(Pid) -> Pid ! die end, L),
U1 = Time1 * 1000/N,
U2 = Time2 * 1000/N,
io:format("Process spawn time=~p (~p) microseconds~n" , [U1, U2]).
wait() ->
receive
die -> void
end.
for(N, N, F) -> [F()];
for(I, N, F) -> [F()|for(I+1, N, F)].
start()->
max(1000),
max(100000).
在任何具有良好处理能力的机器上,上述两个最大功能都将通过。 以下是上述程序的示例输出。
Maximum allowed processes:262144
Process spawn time=47.0 (16.0) microseconds
Maximum allowed processes:262144
Process spawn time=12.81 (10.15) microseconds
收到超时
有时,receive语句可能永远等待永远不会发出的消息。 这可能有很多原因。 例如,我们的程序中可能存在逻辑错误,或者发送消息的进程在发送消息之前可能已崩溃。 为避免此问题,我们可以在receive语句中添加超时。 这将设置进程等待接收消息的最长时间。
以下是指定超时的接收消息的语法
语法 (Syntax)
receive
Pattern1 [when Guard1] ->
Expressions1;
Pattern2 [when Guard2] ->
Expressions2;
...
after Time ->
Expressions
end
最简单的例子是创建一个睡眠功能,如下面的程序所示。
例子 (Example)
-module(helloworld).
-export([sleep/1,start/0]).
sleep(T) ->
receive
after T ->
true
end.
start()->
sleep(1000).
在实际退出之前,上面的代码将睡眠1000 Ms。
选择性接收
Erlang中的每个进程都有一个关联的邮箱。 向进程发送邮件时,邮件将被放入邮箱。 检查此邮箱的唯一时间是程序评估receive语句。
以下是Selective receive语句的一般语法。
语法 (Syntax)
receive
Pattern1 [when Guard1] ->
Expressions1;
Pattern2 [when Guard1] ->
Expressions1;
...
after
Time ->
ExpressionTimeout
end
这就是上述接收语句的工作原理 -
当我们输入receive语句时,我们启动一个计时器(但仅当表达式中存在after section时)。
获取邮箱中的第一条消息,并尝试将其与Pattern1,Pattern2等匹配。 如果匹配成功,则会从邮箱中删除该邮件,并评估该模式后面的表达式。
如果receive语句中没有任何模式与邮箱中的第一条消息匹配,则第一条消息将从邮箱中删除并放入“保存队列”。然后尝试邮箱中的第二条消息。 重复此过程,直到找到匹配的消息,或者直到检查了邮箱中的所有消息。
如果邮箱中没有任何邮件匹配,则该进程将被挂起,并在下次将新邮件放入邮箱时重新安排执行。 请注意,当新消息到达时,保存队列中的消息不会重新匹配; 只有新消息匹配。
一旦匹配了消息,则已经放入保存队列的所有消息将按照它们到达进程的顺序重新输入到邮箱中。 如果设置了计时器,则清除它。
如果在我们等待消息时计时器过去,则计算ExpressionsTimeout表达式,并按照它们到达进程的顺序将任何已保存的消息放回邮箱。
Erlang - Performance
在谈论性能时,需要注意以下几点关于Erlang。
Funs are very fast - Funs在R6B中获得了自己的数据类型,并在R7B中进一步优化。
Using the ++ operator - 需要以正确的方式使用此运算符。 以下示例是执行++操作的错误方法。
例子 (Example)
-module(helloworld).
-export([start/0]).
start()->
fun_reverse([H|T]) ->
fun_reverse(T)++[H];
fun_reverse([]) ->
[].
当++运算符复制其左操作数时,结果将被重复复制,从而导致二次复杂度。
Using Strings - 如果操作不正确,字符串处理可能会很慢。 在Erlang中,您需要更多地考虑字符串的使用方式并选择合适的表示形式。 如果使用正则表达式,请使用STDLIB中的重新模块而不是obsolete regexp module 。
BEAM is a Stack-Based Byte-Code Virtual Machine - BEAM是基于寄存器的虚拟机。 它有1024个虚拟寄存器,用于保存临时值和调用函数时传递参数。 需要在函数调用中存活的变量将保存到堆栈中。 BEAM是一个线程代码解释器。 每条指令都直接指向可执行的C代码,使指令调度非常快。
Erlang - Drivers
有时我们想在Erlang Runtime System中运行一个外语程序。 在这种情况下,程序被编写为动态链接到Erlang运行时系统的共享库。 链接的驱动程序对程序员来说是一个端口程序,并且遵循与端口程序完全相同的协议。
创建驱动程序
创建链接驱动程序是将外语代码与Erlang连接的最有效方法,但它也是最危险的。 链接驱动程序中的任何致命错误都会使Erlang系统崩溃。
以下是Erlang中驱动程序实现的示例 -
例子 (Example)
-module(helloworld).
-export([start/0, stop/0]).
-export([twice/1, sum/2]).
start() ->
start("example1_drv" ).
start(SharedLib) ->
case erl_ddll:load_driver("." , SharedLib) of
ok -> ok;
{error, already_loaded} -> ok;
_ -> exit({error, could_not_load_driver})
end,
spawn(fun() -> init(SharedLib) end).
init(SharedLib) ->
register(example1_lid, self()),
Port = open_port({spawn, SharedLib}, []),
loop(Port).
stop() ->
example1_lid ! stop.
twice(X) -> call_port({twice, X}).
sum(X,Y) -> call_port({sum, X, Y}). call_port(Msg) ->
example1_lid ! {call, self(), Msg}, receive
{example1_lid, Result} ->
Result
end.
LINKED-IN DRIVERS 223
loop(Port) ->
receive
{call, Caller, Msg} ->
Port ! {self(), {command, encode(Msg)}}, receive
{Port, {data, Data}} ->
Caller ! {example1_lid, decode(Data)}
end,
loop(Port);
stop -> Port !
{self(), close},
receive
{Port, closed} ->
exit(normal)
end;
{'EXIT', Port, Reason} ->
io:format("~p ~n" , [Reason]),
exit(port_terminated)
end.
encode({twice, X}) -> [1, X];
encode({sum, X, Y}) -> [2, X, Y]. decode([Int]) -> Int.
请注意,与司机合作非常复杂,在与司机合作时应该小心。
Erlang - Web Programming
在Erlang中, inets library可用于在Erlang中构建Web服务器。 让我们看一下Erlang中用于Web编程的一些函数。 可以实现HTTP服务器,也称为httpd来处理HTTP请求。
服务器实现了许多功能,例如 -
- 安全套接字层(SSL)
- Erlang脚本接口(ESI)
- 通用网关接口(CGI)
- 用户身份验证(使用Mnesia,Dets或纯文本数据库)
- 通用日志文件格式(支持或不支持disk_log(3))
- URL别名
- Action Mappings
- 目录列表
第一项工作是通过命令启动Web库。
inets:start()
下一步是实现inets库的启动功能,以便可以实现Web服务器。
以下是在Erlang中创建Web服务器进程的示例。
例如 (For example)
-module(helloworld).
-export([start/0]).
start() ->
inets:start(),
Pid = inets:start(httpd, [{port, 8081}, {server_name,"httpd_test"},
{server_root,"D://tmp"},{document_root,"D://tmp/htdocs"},
{bind_address, "localhost"}]), io:fwrite("~p",[Pid]).
关于上述计划,需要注意以下几点。
端口号必须是唯一的,不能被任何其他程序使用。 httpd service将在此端口号上启动。
server_root和document_root是必需参数。
输出 (Output)
以下是上述程序的输出。
{ok,<0.42.0>}
要在Erlang中实现Hello world web server ,请执行以下步骤 -
Step 1 - 实现以下代码 -
-module(helloworld).
-export([start/0,service/3]).
start() ->
inets:start(httpd, [
{modules, [
mod_alias,
mod_auth,
mod_esi,
mod_actions,
mod_cgi,
mod_dir,
mod_get,
mod_head,
mod_log,
mod_disk_log
]},
{port,8081},
{server_name,"helloworld"},
{server_root,"D://tmp"},
{document_root,"D://tmp/htdocs"},
{erl_script_alias, {"/erl", [helloworld]}},
{error_log, "error.log"},
{security_log, "security.log"},
{transfer_log, "transfer.log"},
{mime_types,[
{"html","text/html"}, {"css","text/css"}, {"js","application/x-javascript"} ]}
]).
service(SessionID, _Env, _Input) -> mod_esi:deliver(SessionID, [
"Content-Type: text/html\r\n\r\n", "<html><body>Hello, World!</body></html>" ]).
Step 2 - 运行代码如下。 编译上面的文件,然后在erl运行以下命令。
c(helloworld).
您将获得以下输出。
{ok,helloworld}
下一个命令是 -
inets:start().
您将获得以下输出。
ok
下一个命令是 -
helloworld:start().
您将获得以下输出。
{ok,<0.50.0>}
Step 3 - 您现在可以访问url - http://localhost:8081/erl/hello_world:service 。
