Elixir - 快速指南
Elixir - Overview
Elixir是一种动态的功能语言,旨在构建可扩展和可维护的应用程序。 它利用Erlang VM,以运行低延迟,分布式和容错系统而闻名,同时也成功用于Web开发和嵌入式软件领域。
Elixir是一种基于Erlang和Erlang VM构建的功能性动态语言。 Erlang是一种语言,最初由爱立信于1986年编写,旨在帮助解决分发,容错和并发等电话问题。 由JoséValim编写的Elixir扩展了Erlang并为Erlang VM提供了更友好的语法。 它在保持与Erlang相同级别的性能的同时实现了这一点。
Elixir的特点
现在让我们讨论一下Elixir的一些重要特征 -
Scalability - 所有Elixir代码都在轻量级进程内运行,这些进程是隔离的,并通过消息交换信息。
Fault Tolerance - Elixir提供的主管描述了当出现问题时如何重新启动系统的部分,返回到保证工作的已知初始状态。 这可确保您的应用程序/平台永不停机。
Functional Programming - 函数式编程提升了一种编码风格,可以帮助开发人员编写简短,快速和可维护的代码。
Build tools - Elixir附带一套开发工具。 Mix是一个这样的工具,可以轻松创建项目,管理任务,运行测试等。它还有自己的包管理器 - Hex。
Erlang Compatibility - Elixir在Erlang VM上运行,使开发人员可以完全访问Erlang的生态系统。
Elixir - Environment
要运行Elixir,您需要在系统上本地设置它。
要安装Elixir,首先需要Erlang。 在某些平台上,Elixir软件包附带了Erlang。
安装Elixir
现在让我们了解Elixir在不同操作系统中的安装。
Windows安装程序
要在Windows上安装Elixir,请从https://repo.hex.pm/elixirwebsetup.exe下载安装程序,然后单击“ Next继续执行所有步骤。 您将在本地系统上拥有它。
如果您在安装时遇到任何问题,可以查看this page以获取更多信息。
Mac设置
如果您安装了Homebrew,请确保它是最新版本。 要进行更新,请使用以下命令 -
brew update
现在,使用下面给出的命令安装Elixir -
brew install elixir
Ubuntu/Debian Setup
在Ubuntu/Debian设置中安装Elixir的步骤如下 -
添加Erlang Solutions回购 -
wget https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb && sudo
dpkg -i erlang-solutions_1.0_all.deb
sudo apt-get update
安装Erlang/OTP平台及其所有应用程序 -
sudo apt-get install esl-erlang
安装Elixir -
sudo apt-get install elixir
其他Linux发行版
如果您有任何其他Linux发行版,请访问this page以在本地系统上设置elixir。
测试安装程序
要测试系统上的Elixir设置,请打开终端并在其中输入iex。 它将打开交互式elixir shell,如下所示 -
Erlang/OTP 19 [erts-8.0] [source-6dc93c1] [64-bit]
[smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.3.1) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>
Elixir现已成功安装在您的系统上。
Elixir - Basic Syntax
我们将从习惯性的“Hello World”计划开始。
要启动Elixir交互式shell,请输入以下命令。
iex
shell启动后,使用IO.puts函数将字符串“放”到控制台输出上。 在Elixir shell中输入以下内容 -
IO.puts "Hello world"
在本教程中,我们将使用Elixir脚本模式,我们将Elixir代码保存在扩展名为.ex的文件中。 现在让我们将上面的代码保存在test.ex文件中。 在接下来的步骤中,我们将使用elixirc执行它 -
IO.puts "Hello world"
现在让我们尝试按以下方式运行上述程序 -
$elixirc test.ex
上述程序产生以下结果 -
Hello World
这里我们调用一个函数IO.puts来为我们的控制台生成一个字符串作为输出。 这个函数也可以像我们在C,C ++,Java等中那样调用,在函数名后面的括号中提供参数 -
IO.puts("Hello world")
注释 (Comments)
单行注释以“#”符号开头。 没有多行注释,但您可以堆叠多个注释。 例如 -
#This is a comment in Elixir
线路结尾
没有必要的行结尾,如';' 在Elixir。 但是,我们可以使用';'在同一行中包含多个语句。 例如,
IO.puts("Hello"); IO.puts("World!")
上述程序产生以下结果 -
Hello
World!
标识符 (Identifiers)
变量,函数名称等标识符用于标识变量,函数等。在Elixir中,您可以将标识符命名为小写字母,后面是数字,下划线和大写字母。 这种命名约定通常称为snake_case。 例如,以下是Elixir中的一些有效标识符 -
var1 variable_2 one_M0r3_variable
请注意,变量也可以使用前导下划线命名。 必须将不应使用的值分配给_或以下划线开头的变量 -
_some_random_value = 42
此外,elixir依赖于下划线来使函数专用于模块。 如果在模块中使用前导下划线命名函数,并导入该模块,则不会导入此函数。
在Elixir中有许多与函数命名相关的复杂性,我们将在接下来的章节中讨论。
保留字 (Reserved Words)
以下单词是保留的,不能用作变量,模块或函数名称。
after and catch do inbits inlist nil else end
not or false fn in rescue true when xor
__MODULE__ __FILE__ __DIR__ __ENV__ __CALLER__
Elixir - Data Types
要使用任何语言,您需要了解该语言支持的基本数据类型。 在本章中,我们将讨论elixir语言支持的7种基本数据类型:整数,浮点数,布尔值,原子,字符串,列表和元组。
数值类型
与任何其他编程语言一样,Elixir支持整数和浮点数。 如果打开elixir shell并输入任何整数或float作为输入,它将返回其值。 例如,
42
运行上述程序时,会产生以下结果 -
42
您还可以在八进制,十六进制和二进制基数中定义数字。
Octal
要在八进制基数中定义数字,请在其前面加上“0o”。 例如,八进制中的0o52相当于十进制中的42。
十六进制(Hexadecimal)
要以十进制基数定义数字,请在其前面加上“0x”。 例如,十六进制中的0xF1相当于十进制中的241。
Binary
要在二进制基数中定义数字,请在其前面加上“0b”。 例如,二进制中的0b1101相当于十进制中的13。
Elixir支持64位双精度浮点数。 它们也可以使用取幂方式定义。 例如,10145230000可写为1.014523e10
Atoms
原子是常量,其名称是它们的值。 可以使用color(:)符号创建它们。 例如,
:hello
Booleans
Elixir支持false作为布尔人。 这两个值实际上都附加到atoms:true和:false。
Strings
Elixir中的字符串插入双引号之间,它们以UTF-8编码。 它们可以跨越多行并包含插值。 要定义字符串,只需在双引号中输入 -
"Hello world"
要定义多行字符串,我们使用类似于带有三重双引号的python的语法 -
"""
Hello
World!
"""
我们将在字符串章节中深入学习字符串,二进制文件和字符串列表(类似于字符串)。
Binaries
二进制是用<>中包含的字节序列。 例如,
<< 65, 68, 75>>
<<65, 255, 289::size(15)>>
Lists
Elixir使用方括号指定值列表。 值可以是任何类型。 例如,
[1, "Hello", :an_atom, true]
列表带有内置函数,用于名为hd和tl的列表的头部和尾部,它们分别返回列表的头部和尾部。 有时,当您创建列表时,它将返回一个字符列表。 这是因为当elixir看到可打印的ASCII字符列表时,它会将其打印为字符列表。 请注意,字符串和字符列表不相等。 我们将在后面的章节中进一步讨论列表。
Tuples
Elixir使用大括号来定义元组。 像列表一样,元组可以保存任何值。
{ 1, "Hello", :an_atom, true
这里出现一个问题, - 当它们以相同的方式工作时,为什么同时提供lists和tuples ? 他们有不同的实现。
列表实际上存储为链表,因此列表中的插入,删除速度非常快。
另一方面,元组存储在连续的内存块中,这使得访问速度更快,但在插入和删除时增加了额外的成本。
Elixir - Variables
变量为我们提供了程序可以操作的命名存储。 Elixir中的每个变量都有一个特定的类型,它决定了变量内存的大小和布局; 可存储在该内存中的值范围; 以及可以应用于变量的操作集。
变量的类型
Elixir支持以下基本类型的变量。
Integer
这些用于整数。 它们在32位架构上的大小为32位,在64位架构上的大小为64位。 整数总是用长生不老药签名。 如果一个整数开始大小超过其限制,那么elixir会在一个Big Integer中对它进行转换,它占用的内存范围为3到n个单词,无论哪个都适合内存。
Floats
浮点数在灵药中的精度为64位。 它们在记忆方面也像整数。 定义浮点数时,可以使用指数表示法。
Boolean
它们可以占用2个值,无论是真还是假。
Strings
字符串在elixir中以utf-8编码。 它们有一个字符串模块,为程序员提供了很多操作字符串的功能。
Anonymous Functions/Lambdas
这些函数可以定义并分配给变量,然后可以用来调用此函数。
Collections
Elixir有很多种类的收集类型。 其中一些是列表,元组,地图,二进制等。这些将在后续章节中讨论。
变量声明 (Variable Declaration)
变量声明告诉解释器为变量创建存储的位置和数量。 Elixir不允许我们声明变量。 必须声明变量并同时为其分配值。 例如,要创建名为life的变量并为其赋值42,我们执行以下操作 -
life = 42
这会将变量life bind到值42.如果我们想要将此变量重新赋值为新值,我们可以使用与上面相同的语法来完成此操作,即
life = "Hello world"
变量命名
命名变量遵循Elixir中的snake_case约定,即所有变量必须以小写字母开头,后跟0或更多字母(大写和小写),最后是可选的'?' 要么 '!'。
变量名也可以使用前导下划线启动,但必须仅在忽略变量时使用,即该变量不会再次使用但需要分配给某些变量。
打印变量
在交互式shell中,如果只输入变量名称,将打印变量。 例如,如果您创建一个变量 -
life = 42
在shell中输入'life',你会得到输出 -
42
但是如果要将变量输出到控制台(当从文件运行外部脚本时),则需要提供变量作为IO.puts函数的输入 -
life = 42
IO.puts life
OR
life = 42
IO.puts(life)
这将为您提供以下输出 -
42
Elixir - Operators
运算符是一个符号,告诉编译器执行特定的数学或逻辑操作。 elixir提供了很多运算符。 它们分为以下几类 -
- 算术运算符
- 比较运算符
- 布尔运算符
- 其他运算符
算术运算符 (Arithmetic Operators)
下表显示了Elixir语言支持的所有算术运算符。 假设变量A保持10,变量B保持20,则 -
| 操作者 | 描述 | 例 |
|---|---|---|
| + | Adds 2 numbers. | A + B将给出30 |
| - | 从第一个减去第二个数字。 | A-B will give -10 |
| * | 将两个数相乘。 | A * B将给出200 |
| / | 将第一个数字除以第二个数字。 这会将数字转换为浮点数并给出浮点结果 | A/B将给出0.5。 |
| div | 此函数用于获取除法的商。 | div(10,20) will give 0 |
| rem | 此函数用于获取除法的余数。 | rem(A,B)将给出10 |
比较运算符 (Comparison Operators)
Elixir中的比较运算符与大多数其他语言中提供的运算符相同。 下表总结了Elixir中的比较运算符。 假设变量A保持10,变量B保持20,则 -
| 操作者 | 描述 | 例 |
|---|---|---|
| == | 检查左边的值是否等于右边的值(如果它们不是同一类型,则键入强制转换值)。 | A == B将给出错误 |
| != | 检查左边的值是否等于右边的值。 | A!= B将给出真实 |
| === | 检查左边的值类型是否等于右边的值类型,如果是,则检查值是否相同。 | A === B会给出错误 |
| !== | 与上面相同,但检查不平等而不是相等。 | A!== B将给出真实 |
| > | 检查左操作数的值是否大于右操作数的值; 如果是,则条件成立。 | A> B将给出错误 |
| < | 检查左操作数的值是否小于右操作数的值; 如果是,则条件成立。 | A < B 为 true |
| >= | 检查左操作数的值是否大于或等于右操作数的值; 如果是,则条件成立。 | A> = B将给出错误 |
| <= | 检查左操作数的值是否小于或等于右操作数的值; 如果是,则条件成立。 | A <= B将给出真实 |
逻辑运算符
Elixir提供了6个逻辑运算符:和,或者,不是,&&,|| 和! 前三个, and or not严格的布尔运算符,这意味着它们期望它们的第一个参数是布尔值。 非布尔参数将引发错误。 而接下来的三个, &&, || and ! &&, || and ! 是非严格的,不要求我们将第一个值严格地作为布尔值。 它们的工作方式与严格的同行相同。 假设变量A成立,变量B成立20,则 -
| 操作者 | 描述 | 例 |
|---|---|---|
| and | 检查提供的两个值是否真实,如果是,则返回第二个变量的值。 (逻辑和)。 | A和B将给20 |
| or | 检查提供的值是否真实。 返回真正的值。 否则返回false。 (逻辑或)。 | A或B将给出真实 |
| not | 一元运算符,它反转给定输入的值。 | 不是A会给出错误 |
| && | 非严格and 。 与第一个参数相同但不期望它是布尔值。 | B && A将给20 |
| || | 非严格or 。 与第一个参数相同or不期望第一个参数是布尔值。 | B || A会给出真实的 |
| ! | 非严格not 。 同样的工作原理,但不要指望参数是布尔值。 | !A will give false |
NOTE − and , or , &&和|| || 是短路运算符。 这意味着如果和的第一个参数为false,那么它将不会进一步检查第二个参数。 如果第一个参数or为真,那么它将不会检查第二个参数。 例如,
false and raise("An error")
#This won't raise an error as raise function wont get executed because of short
#circuiting nature of and operator
按位运算符 (Bitwise Operators)
按位运算符处理位并执行逐位操作。 Elixir提供按位模块作为Bitwise包的一部分,因此为了使用这些模块,您需要use按位模块。 要使用它,请在shell中输入以下命令 -
use Bitwise
对于以下示例,假设A为5,B为6:
| 操作者 | 描述 | 例 |
|---|---|---|
| &&& | 如果两个操作数中都存在Bitwise和运算符,则会将其复制到结果中。 | A &&& B将给出4 |
| ||| | 如果在任一操作数中存在,则按位或运算符将一个位复制到结果。 | A ||| B会给7 |
| >>> | 按位右移运算符将第一个操作数位向右移动第二个操作数中指定的数字。 | A >>> B将给出0 |
| <<< | 按位左移位运算符将第一个操作数位向左移动第二个操作数中指定的数字。 | A <<< B将给出320 |
| ^^^ | 只有在两个操作数上它们不同时,按位XOR运算符才会将某个位复制到结果中。 | A ^^^ B将给出3 |
| ~~~ | 一元按位不反转给定数字上的位。 | ~~~ A会给-6 |
其它运算符
除了上述运算符之外,Elixir还提供了一系列其他运算符,如Concatenation Operator, Match Operator, Pin Operator, Pipe Operator, String Match Operator, Code Point Operator, Capture Operator, Ternary Operator ,使其成为一种非常强大的语言。
Elixir - Pattern Matching
模式匹配是Elixir从Erlang继承的技术。 这是一种非常强大的技术,它允许我们从复杂的数据结构中提取更简单的子结构,如列表,元组,映射等。
比赛有2个主要部分, left和right 。 右侧是任何类型的数据结构。 左侧尝试匹配右侧的数据结构,并将左侧的任何变量绑定到右侧的相应子结构。 如果未找到匹配项,则运算符会引发错误。
最简单的匹配是左侧的单个变量和右侧的任何数据结构。 This variable will match anything 。 例如,
x = 12
x = "Hello"
IO.puts(x)
您可以将变量放在结构中,以便捕获子结构。 例如,
[var_1, _unused_var, var_2] = [{"First variable"}, 25, "Second variable" ]
IO.puts(var_1)
IO.puts(var_2)
这将在var_1存储值{"First variable"} ,在var_2中var_2 "Second variable" 。 还有一个特殊的_变量(或以'_'为前缀的变量),其工作方式与其他变量完全相同,但告诉elixir, "Make sure something is here, but I don't care exactly what it is." 。 在前面的例子中, _unused_var就是这样一个变量。
我们可以使用这种技术匹配更复杂的模式。 example如果要打开并在列表中的元组中获取数字,该列表本身位于列表中,则可以使用以下命令 -
[_, [_, {a}]] = ["Random string", [:an_atom, {24}]]
IO.puts(a)
这将绑定到24.其他值被忽略,因为我们使用'_'。
在模式匹配中,如果我们在right使用变量,则使用其值。 如果要使用左侧变量的值,则需要使用pin运算符。
例如,如果您的变量“a”的值为25,并且您希望将其与另一个值为25的变量“b”匹配,那么您需要输入 -
a = 25
b = 25
^a = b
最后一行匹配a的当前值,而不是将其赋值给b的值。 如果我们有一组不匹配的左侧和右侧,匹配运算符会引发错误。 例如,如果我们尝试将元组与列表或大小为2的列表与大小为3的列表进行匹配,则会显示错误。
Elixir - Decision Making
决策结构要求程序员指定程序要评估或测试的一个或多个条件,以及在条件被确定为true要执行的语句,以及可选的,如果条件要执行的其他语句被认定是false 。
以下是大多数编程语言中发现的典型决策结构的一般性 -
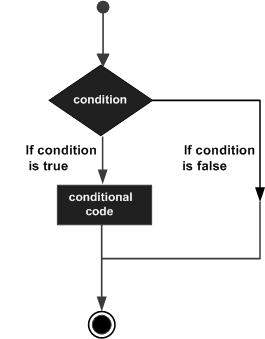
Elixir提供if/else条件结构,就像许多其他编程语言一样。 它还有一个cond语句,它调用它找到的第一个真值。 Case是另一个控制流语句,它使用模式匹配来控制程序的流程。 让我们深入了解它们。
Elixir提供以下类型的决策声明。 单击以下链接以检查其详细信息。
| Sr.No. | 声明和说明 |
|---|---|
| 1 | if 语句 if语句由一个布尔表达式后跟do ,一个或多个可执行语句以及最后一个end关键字组成。 if语句中的代码仅在布尔条件求值为true时执行。 |
| 2 | if..else statement if语句后面可以跟一个可选的else语句(在do..end块中),该语句在布尔表达式为false时执行。 |
| 3 | unless statement 除非语句与if语句具有相同的主体。 unless语句中的代码仅在指定的条件为false时执行。 |
| 4 | unless..else statement unless..else语句与if..else语句具有相同的主体。 unless语句中的代码仅在指定的条件为false时执行。 |
| 5 | cond 在我们想要基于几个条件执行代码的地方使用cond语句。 它有点像if ... else if ... .else构造在其他几种编程语言中。 |
| 6 | case Case语句可以被视为命令式语言中switch语句的替代。 Case采用变量/文字并使用不同的情况对其应用模式匹配。 如果任何情况匹配,Elixir将执行与该案例相关的代码并退出case语句。 |
Elixir - Strings
Elixir中的字符串插入双引号之间,它们以UTF-8编码。 与C和C ++不同,默认字符串是ASCII编码的,只有256个不同的字符,UTF-8由66536 code points 。 这意味着UTF-8编码由许多不同的可能字符组成。 由于字符串使用utf-8,我们也可以使用符号:ö,ł等。
创建一个字符串
要创建字符串变量,只需将字符串赋值给变量 -
str = "Hello world"
要将其打印到控制台,只需调用IO.puts函数并将其传递给变量str -
str = str = "Hello world"
IO.puts(str)
上述程序产生以下结果 -
Hello World
空字符串
您可以使用字符串文字""创建一个空字符串。 例如,
a = ""
if String.length(a) === 0 do
IO.puts("a is an empty string")
end
上述程序生成以下结果。
a is an empty string
字符串插值
字符串插值是一种通过在字符串文字中包含它们的值,从常量,变量,文字和表达式的混合构造新的String值的方法。 Elixir支持字符串插值,在字符串中使用变量,在编写字符串时,用花括号括起来,并在花括号前加上“#”符号。
例如,
x = "Apocalypse"
y = "X-men #{x}"
IO.puts(y)
这将取x的值并将其替换为y。 上面的代码将生成以下结果 -
X-men Apocalypse
字符串连接
我们已经在前面的章节中看到过使用String连接。 '<>'运算符用于连接Elixir中的字符串。 要连接2个字符串,
x = "Dark"
y = "Knight"
z = x <> " " <> y
IO.puts(z)
上面的代码生成以下结果 -
Dark Knight
字符串长度
为了获得字符串的长度,我们使用String.length函数。 将字符串作为参数传递,它将显示其大小。 例如,
IO.puts(String.length("Hello"))
在程序上运行时,会产生以下结果 -
5
反转字符串
要反转字符串,请将其传递给String.reverse函数。 例如,
IO.puts(String.reverse("Elixir"))
上述程序产生以下结果 -
rixilE
字符串比较
要比较2个字符串,我们可以使用==或===运算符。 例如,
var_1 = "Hello world"
var_2 = "Hello Elixir"
if var_1 === var_2 do
IO.puts("#{var_1} and #{var_2} are the same")
else
IO.puts("#{var_1} and #{var_2} are not the same")
end
上述程序产生以下结果 -
Hello world and Hello elixir are not the same.
字符串匹配
我们已经看到了使用=〜字符串匹配运算符。 要检查字符串是否与正则表达式匹配,我们还可以使用字符串匹配运算符或String.match? 功能。 例如,
IO.puts(String.match?("foo", ~r/foo/))
IO.puts(String.match?("bar", ~r/foo/))
上述程序产生以下结果 -
true
false
使用=〜运算符也可以实现同样的目的。 例如,
IO.puts("foo" =~ ~r/foo/)
上述程序产生以下结果 -
true
字符串函数 (String Functions)
Elixir支持大量与字符串相关的函数,下面列出了一些最常用的函数。
| Sr.No. | 功能及其目的 |
|---|---|
| 1 | at(string, position) 返回给定utf8字符串位置的字形。 如果position大于字符串长度,则返回nil |
| 2 | capitalize(string) 将给定字符串中的第一个字符转换为大写,将余数转换为小写 |
| 3 | contains?(string, contents) 检查字符串是否包含任何给定内容 |
| 4 | downcase(string) 将给定字符串中的所有字符转换为小写 |
| 5 | ends_with?(string, suffixes) 如果string以给定的任何后缀结束,则返回true |
| 6 | first(string) 从utf8字符串返回第一个字形,如果字符串为空则返回nil |
| 7 | last(string) 返回utf8字符串中的最后一个字形,如果字符串为空则返回nil |
| 8 | replace(subject, pattern, replacement, options \\ []) 返回通过替换主题中的pattern的出现而创建的新字符串 |
| 9 | slice(string, start, len) 返回从偏移量start开始的子字符串,长度为len |
| 10 | split(string) 在每个Unicode空白事件中将字符串分为子字符串,忽略前导和尾随空格。 空白组被视为单个事件。 在不破坏的空白处不会出现划分 |
| 11 | upcase(string) 将给定字符串中的所有字符转换为大写 |
Binaries
二进制只是一个字节序列。 二进制文件使用《《 》》定义。 例如:
<< 0, 1, 2, 3 >>
当然,这些字节可以以任何方式组织,即使在不使它们成为有效字符串的序列中也是如此。 例如,
<< 239, 191, 191 >>
字符串也是二进制文件。 字符串连接运算符《》实际上是二进制连接运算符:
IO.puts(<< 0, 1 >> <> << 2, 3 >>)
上面的代码生成以下结果 -
<< 0, 1, 2, 3 >>
注意ł字符。 由于这是utf-8编码,因此该字符表示占用2个字节。
由于二进制中表示的每个数字都是一个字节,当此值从255上升时,它将被截断。 为了防止这种情况,我们使用size修饰符来指定我们想要该数字的位数。 例如 -
IO.puts(<< 256 >>) # truncated, it'll print << 0 >>
IO.puts(<< 256 :: size(16) >>) #Takes 16 bits/2 bytes, will print << 1, 0 >>
上述程序将产生以下结果 -
<< 0 >>
<< 1, 0 >>
我们也可以使用utf8修饰符,如果一个字符是代码点,那么它将在输出中产生; 否则字节 -
IO.puts(<< 256 :: utf8 >>)上述程序产生以下结果 -
Ā
我们还有一个名为is_binary的函数,用于检查给定变量是否为二进制。 请注意,只有存储为8位倍数的变量才是二进制文件。
Bitstrings
如果我们使用size修饰符定义二进制文件并将其传递给不是8的倍数的值,我们最终会得到一个位串而不是二进制。 例如,
bs = << 1 :: size(1) >>
IO.puts(bs)
IO.puts(is_binary(bs))
IO.puts(is_bitstring(bs))
上述程序产生以下结果 -
<< 1::size(1) >>
false
true
这意味着变量bs不是二进制,而是位串。 我们还可以说二进制是一个位串,其中位数可以被8整除。模式匹配以相同的方式处理二进制和位串。
Elixir - Char lists
char列表只不过是一个字符列表。 考虑以下程序来理解相同的内容。
IO.puts('Hello')
IO.puts(is_list('Hello'))
上述程序产生以下结果 -
Hello
true
char列表不包含字节,而是包含单引号之间字符的代码点。 So while the double-quotes represent a string (ie a binary), singlequotes represent a char list (ie a list) 。 请注意,如果任何字符超出ASCII范围,IEx将仅生成代码点作为输出。
Char列表主要在与Erlang接口时使用,特别是不接受二进制作为参数的旧库。 您可以使用to_string(char_list)和to_char_list(string)函数将char列表转换为字符串并返回
IO.puts(is_list(to_char_list("hełło")))
IO.puts(is_binary(to_string ('hełło')))
上述程序产生以下结果 -
true
true
NOTE - 函数to_string和to_char_list是多态的,即它们可以采用多种类型的输入,如原子,整数,并分别将它们转换为字符串和字符列表。
Elixir - Lists and Tuples
(Linked) Lists
链表是一个异构的元素列表,它们存储在内存中的不同位置,并通过使用引用来跟踪。 链表是特别用于函数式编程的数据结构。
Elixir使用方括号指定值列表。 值可以是任何类型 -
[1, 2, true, 3]
当Elixir看到可打印的ASCII数字列表时,Elixir会将其打印为字符列表(字面上的字符列表)。 每当您在IEx中看到一个值并且您不确定它是什么时,您可以使用i函数来检索有关它的信息。
IO.puts([104, 101, 108, 108, 111])
列表中的上述字符均可打印。 运行上述程序时,会产生以下结果 -
hello
您还可以使用单引号以相反的方式定义列表 -
IO.puts(is_list('Hello'))
运行上述程序时,会产生以下结果 -
true
请记住,单引号和双引号表示在Elixir中不相同,因为它们由不同类型表示。
列表的长度
要查找列表的长度,我们使用长度函数,如下面的程序 -
IO.puts(length([1, 2, :true, "str"]))
上述程序产生以下结果 -
4
连接和减法
可以使用++和--运算符连接和减去两个列表。 请考虑以下示例以了解这些功能。
IO.puts([1, 2, 3] ++ [4, 5, 6])
IO.puts([1, true, 2, false, 3, true] -- [true, false])
这将在第一种情况下为您提供连接的字符串,在第二种情况下为您提供减去的字符串。 上述程序产生以下结果 -
[1, 2, 3, 4, 5, 6]
[1, 2, 3, true]
列表的头部和尾部
head是列表的第一个元素,tail是列表的其余部分。 可以使用函数hd和tl检索它们。 让我们为变量分配一个列表并检索它的头部和尾部。
list = [1, 2, 3]
IO.puts(hd(list))
IO.puts(tl(list))
这将给我们列表的头部和尾部作为输出。 上述程序产生以下结果 -
1
[2, 3]
Note - 获取空列表的头部或尾部是一个错误。
Other List Functions
Elixir标准库提供了许多处理列表的功能。 我们将在这里看看其中一些。 你可以看看这里的其余部分。
| S.no. | 功能名称和描述 |
|---|---|
| 1 | delete(list, item) 从列表中删除给定的项目。 返回没有项目的列表。 如果项目在列表中出现多次,则仅删除第一个匹配项。 |
| 2 | delete_at(list, index) 通过删除指定索引处的值来生成新列表。 负指数表示从列表末尾的偏移量。 如果index超出范围,则返回原始列表。 |
| 3 | first(list) 返回列表中的第一个元素,如果list为空,则返回nil。 |
| 4 | flatten(list) 展平给定的嵌套列表列表。 |
| 5 | insert_at(list, index, value) 返回在指定索引处插入值的列表。 请注意,索引的上限为列表长度。 负指数表示从列表末尾的偏移量。 |
| 6 | last(list) 返回列表中的最后一个元素,如果list为空,则返回nil。 |
Tuples
元组也是在其中存储许多其他结构的数据结构。 与列表不同,它们将元素存储在连续的内存块中。 这意味着每个索引访问一个元组元素或获取元组大小是一个快速操作。 索引从零开始。
Elixir使用大括号来定义元组。 像列表一样,元组可以保留任何值 -
{:ok, "hello"}
元组的长度
要获取元组的长度,请使用tuple_size函数,如以下程序中所示 -
IO.puts(tuple_size({:ok, "hello"}))
上述程序产生以下结果 -
2
附加值
要将值附加到元组,请使用Tuple.append函数 -
tuple = {:ok, "Hello"}
Tuple.append(tuple, :world)
这将创建并返回一个新元组:{:ok,“Hello”,:world}
插入一个值
要在给定位置插入值,我们可以使用Tuple.insert_at函数或put_elem函数。 考虑以下示例来理解相同的 -
tuple = {:bar, :baz}
new_tuple_1 = Tuple.insert_at(tuple, 0, :foo)
new_tuple_2 = put_elem(tuple, 1, :foobar)
请注意, put_elem和insert_at返回了put_elem组。 存储在元组变量中的原始元组未被修改,因为Elixir数据类型是不可变的。 通过不可变,Elixir代码更容易推理,因为如果特定代码正在改变您的数据结构,您永远不必担心。
元组与列表
列表和元组之间有什么区别?
列表作为链表存储在内存中,这意味着列表中的每个元素都保持其值并指向以下元素,直到到达列表末尾。 我们将每对值和指针称为cons单元格。 这意味着访问列表的长度是一个线性操作:我们需要遍历整个列表以确定其大小。 只要我们预先添加元素,更新列表就很快。
另一方面,元组连续存储在存储器中。 这意味着获取元组大小或按索引访问元素很快。 但是,更新或向元组添加元素是昂贵的,因为它需要在内存中复制整个元组。
Elixir - Keyword lists
到目前为止,我们还没有讨论任何关联数据结构,即可以将特定值(或多个值)与密钥相关联的数据结构。 不同的语言使用不同的名称来调用这些功能,如字典,散列,关联数组等。
在Elixir中,我们有两个主要的关联数据结构:关键字列表和映射。 在本章中,我们将重点关注关键字列表。
在许多函数式编程语言中,通常使用2项元组的列表作为关联数据结构的表示。 在Elixir中,当我们有一个元组列表并且元组的第一项(即键)是一个原子时,我们将其称为关键字列表。 考虑以下示例来理解相同的 -
list = [{:a, 1}, {:b, 2}]
Elixir支持用于定义此类列表的特殊语法。 我们可以将冒号放在每个原子的末尾,完全摆脱元组。 例如,
list_1 = [{:a, 1}, {:b, 2}]
list_2 = [a: 1, b: 2]
IO.puts(list_1 == list_2)
上述程序将产生以下结果 -
true
这两个都代表关键字列表。 由于关键字列表也是列表,我们可以使用我们在列表上使用的所有操作。
要检索与关键字列表中的原子关联的值,请将原子传递给列表名称后的[] -
list = [a: 1, b: 2]
IO.puts(list[:a])
上述程序产生以下结果 -
1
关键字列表有三个特点 -
- Keys must be atoms.
- 根据开发人员的指定订购密钥。
- 钥匙可以多次出现。
为了操纵关键字列表,Elixir提供List 。 但请记住,关键字列表只是列表,因此它们提供与列表相同的线性性能特征。 列表越长,查找密钥,计算项目数量等所需的时间越长,等等。 因此,Elixir中的关键字列表主要用作选项。 如果您需要存储许多项目或保证具有最大单值的一键关联,则应使用地图。
访问密钥
要访问与给定键关联的值,我们使用Keyword.get函数。 它返回与给定键关联的第一个值。 要获取所有值,我们使用Keyword.get_values函数。 例如 -
kl = [a: 1, a: 2, b: 3]
IO.puts(Keyword.get(kl, :a))
IO.puts(Keyword.get_values(kl))
上述程序将产生以下结果 -
1
[1, 2]
插入一个键
要添加新值,请使用Keyword.put_new 。 如果密钥已存在,则其值保持不变 -
kl = [a: 1, a: 2, b: 3]
kl_new = Keyword.put_new(kl, :c, 5)
IO.puts(Keyword.get(kl_new, :c))
运行上述程序时,它会生成一个带有附加键c的新关键字列表,并生成以下结果 -
5
删除密钥
如果要删除密钥的所有条目,请使用Keyword.delete; 要仅删除密钥的第一个条目,请使用Keyword.delete_first 。
kl = [a: 1, a: 2, b: 3, c: 0]
kl = Keyword.delete_first(kl, :b)
kl = Keyword.delete(kl, :a)
IO.puts(Keyword.get(kl, :a))
IO.puts(Keyword.get(kl, :b))
IO.puts(Keyword.get(kl, :c))
这将删除列表中的第一个b和列表中的所有a 。 运行上述程序时,将生成以下结果 -
0
Elixir - Maps
关键字列表是一种通过键来处理存储在列表中的内容的便捷方式,但在下面,Elixir仍在遍历列表。 如果您对该列表有其他计划需要遍历所有计划,那么这可能是合适的,但如果您计划使用密钥作为数据的唯一方法,则可能是不必要的开销。
这是地图来救你的地方。 每当您需要键值存储时,映射就是Elixir中的“转到”数据结构。
创建地图
使用%{}语法创建地图 -
map = %{:a => 1, 2 => :b}
与关键字列表相比,我们已经看到两个不同之处 -
- 地图允许任何值作为键。
- 地图的密钥不遵循任何订购。
访问密钥
为了访问与键相关联的值,Maps使用与关键字列表相同的语法 -
map = %{:a => 1, 2 => :b}
IO.puts(map[:a])
IO.puts(map[2])
运行上述程序时,会生成以下结果 -
1
b
插入一个键
要在地图中插入一个键,我们使用Dict.put_new函数,该函数将map,new key和new value作为参数 -
map = %{:a => 1, 2 => :b}
new_map = Dict.put_new(map, :new_val, "value")
IO.puts(new_map[:new_val])
这将在新地图中插入键值对:new_val - "value" 。 运行上述程序时,会生成以下结果 -
"value"
更新价值
要更新地图中已存在的值,您可以使用以下语法 -
map = %{:a => 1, 2 => :b}
new_map = %{ map | a: 25}
IO.puts(new_map[:a])
运行上述程序时,会生成以下结果 -
25
模式匹配
与关键字列表相比,地图对于模式匹配非常有用。 在模式中使用地图时,它将始终与给定值的子集匹配 -
%{:a => a} = %{:a => 1, 2 => :b}
IO.puts(a)
这将与1匹配。 因此,它将生成输出为1 。
如上所示,只要模式中的键存在于给定的映射中,映射就会匹配。 因此,空地图匹配所有地图。
访问,匹配和添加地图密钥时可以使用变量 -
n = 1
map = %{n => :one}
%{^n => :one} = %{1 => :one, 2 => :two, 3 => :three}
Map模块为Keyword The Map module提供了一个非常类似的API,它具有操作地图的便利功能。 您可以使用Map.get, Map.delete等函数来操作地图。
使用Atom键映射
地图附带一些有趣的属性。 当地图中的所有键都是原子时,您可以使用关键字语法以方便 -
map = %{:a => 1, 2 => :b}
IO.puts(map.a)
地图的另一个有趣的特性是它们提供了自己的语法来更新和访问原子键 -
map = %{:a => 1, 2 => :b}
IO.puts(map.a)
请注意,要以这种方式访问原子键,它应该存在或程序将无法工作。
Elixir - Modules
在Elixir中,我们将多个功能组合到模块中。 我们在前面的章节中已经使用了不同的模块,例如String模块,Bitwise模块,Tuple模块等。
为了在Elixir中创建我们自己的模块,我们使用defmodule宏。 我们使用def宏来定义该模块中的函数 -
defmodule Math do
def sum(a, b) do
a + b
end
end
在以下部分中,我们的示例将变得更长,并且在shell中键入它们可能会很棘手。 我们需要学习如何编译Elixir代码以及如何运行Elixir脚本。
Compilation
将模块写入文件总是很方便,因此可以编译和重用它们。 我们假设我们有一个名为math.ex的文件,其中包含以下内容 -
defmodule Math do
def sum(a, b) do
a + b
end
end
我们可以使用命令elixirc编译文件:
$ elixirc math.ex
这将生成一个名为Elixir.Math.beam的文件, Elixir.Math.beam包含已定义模块的字节码。 如果我们再次启动iex ,我们的模块定义将可用(假设iex在字节码文件所在的同一目录中启动)。 例如,
IO.puts(Math.sum(1, 2))
上述程序将产生以下结果 -
3
脚本模式
除了Elixir文件扩展名.ex ,Elixir还支持.exs文件以进行脚本编写。 Elixir以完全相同的方式处理两个文件,唯一的区别在于目标。 .ex文件用于编译,而.exs文件用于scripting 。 执行时,两个扩展都会编译并将其模块加载到内存中,尽管只有.ex文件以.beam文件的格式将其字节码写入磁盘。
例如,如果我们想在同一个文件中运行Math.sum ,我们可以按照以下方式使用.exs -
Math.exs
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(1, 2))
我们可以使用Elixir命令运行它 -
$ elixir math.exs
该文件将在内存中编译并执行,结果打印“3”。 不会创建字节码文件。
模块嵌套
模块可以嵌套在Elixir中。 该语言的这一特性有助于我们以更好的方式组织我们的代码。 要创建嵌套模块,我们使用以下语法 -
defmodule Foo do
#Foo module code here
defmodule Bar do
#Bar module code here
end
end
上面给出的例子将定义两个模块: Foo和Foo.Bar 。 第二个可以在Foo作为Bar访问,只要它们在相同的词法范围内。 如果稍后将Bar模块移到Foo模块定义之外,则必须使用其全名(Foo.Bar)引用它,或者必须使用别名章节中讨论的别名指令设置别名。
Note - 在Elixir中,没有必要定义Foo模块以定义Foo.Bar模块,因为该语言将所有模块名称转换为原子。 您可以定义任意模块,而无需在链中定义任何模块。 例如,您可以定义Foo.Bar.Baz而无需定义Foo或Foo.Bar 。
Elixir - Aliases
为了便于软件重用,Elixir提供了三个指令 - alias, require和import 。 它还提供了一个名为use的宏,总结如下 -
# Alias the module so it can be called as Bar instead of Foo.Bar
alias Foo.Bar, as: Bar
# Ensure the module is compiled and available (usually for macros)
require Foo
# Import functions from Foo so they can be called without the `Foo.` prefix
import Foo
# Invokes the custom code defined in Foo as an extension point
use Foo
现在让我们详细了解每个指令。
alias
alias指令允许您为任何给定的模块名称设置别名。 例如,如果要为String模块提供别名'Str' ,则只需编写 -
alias String, as: Str
IO.puts(Str.length("Hello"))
上述程序产生以下结果 -
5
String模块的别名为Str 。 现在,当我们使用Str文字调用任何函数时,它实际上引用了String模块。 当我们使用非常长的模块名称并希望在当前范围中替换那些较短的模块名称时,这非常有用。
NOTE - 别名MUST以大写字母开头。
别名仅在它们被调用的lexical scope内有效。例如,如果文件中有2个模块并在其中一个模块中创建别名,则该别名将无法在第二个模块中访问。
如果您将内置模块的名称(如String或Tuple)作为其他模块的别名,则要访问内置模块,您需要在其中添加"Elixir." 。 例如,
alias List, as: String
#Now when we use String we are actually using List.
#To use the string module:
IO.puts(Elixir.String.length("Hello"))
运行上述程序时,会生成以下结果 -
5
require
Elixir提供宏作为元编程的机制(编写生成代码的代码)。
宏是在编译时执行和扩展的代码块。 这意味着,为了使用宏,我们需要保证在编译期间其模块和实现可用。 这是通过require指令完成的。
Integer.is_odd(3)
运行上述程序时,将生成以下结果 -
** (CompileError) iex:1: you must require Integer before invoking the macro Integer.is_odd/1
在Elixir中, Integer.is_odd被定义为macro 。 该宏可用作防护。 这意味着,为了调用Integer.is_odd ,我们需要Integer模块。
使用require Integer函数并运行程序,如下所示。
require Integer
Integer.is_odd(3)
这次程序将运行并生成输出为: true 。
通常,在使用之前不需要模块,除非我们想要使用该模块中可用的宏。 尝试调用未加载的宏将引发错误。 请注意,与alias指令一样, require is also lexically scoped 。 我们将在后面的章节中详细讨论宏。
import
我们使用import指令轻松访问其他模块中的函数或宏,而不使用完全限定名称。 例如,如果我们想多次使用List模块中的duplicate函数,我们可以简单地导入它。
import List, only: [duplicate: 2]
在这种情况下,我们只从List导入函数duplicate(带参数列表长度2)。 虽然:only是可选的,但建议使用它,以避免在命名空间内导入给定模块的所有功能。 :除了函数列表之外,还可以作为选项提供,以便导入模块中的所有内容。
import指令还支持:macros和:only给出的:functions :only 。 例如,要导入所有宏,用户可以写 -
import Integer, only: :macros
请注意,导入也是Lexically scoped ,就像require和alias指令一样。 另请注意, 'import'ing a module also 'require's it 。
use
尽管不是指令,但use是一个与require紧密相关的宏,允许您在当前上下文中使用模块。 开发人员经常使用use宏将外部功能引入当前的词法范围,通常是模块。 让我们通过一个例子来理解use指令 -
defmodule Example do
use Feature, option: :value
end
使用是一个宏,将上述内容转换为 -
defmodule Example do
require Feature
Feature.__using__(option: :value)
end
use Module首先需要模块,然后在Module上调用__using__宏。 Elixir具有出色的元编程功能,它具有在编译时生成代码的宏。 在上面的实例中调用了_ _using__宏,并将代码注入到我们的本地上下文中。 本地上下文是编译时调用use macro的地方。
Elixir - 函数
函数是组合在一起执行特定任务的一组语句。 编程中的函数主要类似于Math中的函数。 您为函数提供一些输入,它们根据提供的输入生成输出。
Elixir有两种类型的功能 -
匿名功能
使用fn..end construct定义的fn..end construct是匿名函数。 这些函数有时也称为lambda。 通过将它们分配给变量名来使用它们。
命名功能
使用def keyword定义的函数是命名函数。 这些是Elixir中提供的本机功能。
匿名函数
顾名思义,匿名函数没有名称。 这些经常被传递给其他功能。 要在Elixir中定义匿名函数,我们需要fn和end关键字。 在这些中,我们可以定义由-》分隔的任意数量的参数和函数体。 例如,
sum = fn (a, b) -> a + b end
IO.puts(sum.(1, 5))
运行上面的程序运行时,会产生以下结果 -
6
请注意,这些函数不像命名函数那样被调用。 我们有' . '在函数名和它的参数之间。
使用捕获运算符
我们还可以使用捕获运算符定义这些函数。 这是一种更简单的创建函数的方法。 我们现在将使用捕获运算符定义上面的sum函数,
sum = &(&1 + &2)
IO.puts(sum.(1, 2))
运行上述程序时,会生成以下结果 -
3
在简写版本中,我们的参数未命名,但我们可以使用&1,&2和&3等等。
模式匹配功能 (Pattern Matching Functions)
模式匹配不仅限于变量和数据结构。 我们可以使用模式匹配来使我们的函数具有多态性。 例如,我们将声明一个可以接受1或2个输入(在元组内)并将它们打印到控制台的函数,
handle_result = fn
{var1} -> IO.puts("#{var1} found in a tuple!")
{var_2, var_3} -> IO.puts("#{var_2} and #{var_3} found!")
end
handle_result.({"Hey people"})
handle_result.({"Hello", "World"})
运行上述程序时,会产生以下结果 -
Hey people found in a tuple!
Hello and World found!
Named 函数
我们可以使用名称定义函数,以便稍后我们可以轻松地引用它们。 命名函数使用def关键字在模块中定义。 命名函数始终在模块中定义。 要调用命名函数,我们需要使用它们的模块名称来引用它们。
以下是命名函数的语法 -
def function_name(argument_1, argument_2) do
#code to be executed when function is called
end
现在让我们在Math模块中定义命名函数sum。
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(5, 6))
在程序上运行时,会产生以下结果 -
11
对于单线函数,有一个简写符号来定义这些函数,使用do: . 例如 -
defmodule Math do
def sum(a, b), do: a + b
end
IO.puts(Math.sum(5, 6))
在程序上运行时,会产生以下结果 -
11
私有函数 (Private Functions)
Elixir使我们能够定义可以从定义它们的模块中访问的私有函数。 要定义私有函数,请使用defp而不是def 。 例如,
defmodule Greeter do
def hello(name), do: phrase <> name
defp phrase, do: "Hello "
end
Greeter.hello("world")
运行上述程序时,会产生以下结果 -
Hello world
但是如果我们只是尝试使用Greeter.phrase()函数显式调用短语函数,则会引发错误。
默认参数
如果我们想要一个参数的默认值,我们使用argument \\ value语法 -
defmodule Greeter do
def hello(name, country \\ "en") do
phrase(country) <> name
end
defp phrase("en"), do: "Hello, "
defp phrase("es"), do: "Hola, "
end
Greeter.hello("Ayush", "en")
Greeter.hello("Ayush")
Greeter.hello("Ayush", "es")
运行上述程序时,会产生以下结果 -
Hello, Ayush
Hello, Ayush
Hola, Ayush
Elixir - Recursion
递归是一种方法,其中问题的解决方案取决于对同一问题的较小实例的解决方案。 大多数计算机编程语言通过允许函数在程序文本中调用自身来支持递归。
理想情况下,递归函数具有结束条件。 此结束条件(也称为基本情况)会停止重新输入函数并向堆栈添加函数调用。 这是递归函数调用停止的地方。 让我们考虑以下示例来进一步理解递归函数。
defmodule Math do
def fact(res, num) do
if num === 1 do
res
else
new_res = res * num
fact(new_res, num-1)
end
end
end
IO.puts(Math.fact(1,5))运行上述程序时,会生成以下结果 -
120
所以在上面的函数Math.fact ,我们计算一个数的阶乘。 请注意,我们在其自身内部调用该函数。 现在让我们了解这是如何工作的。
我们为它提供了1和我们想要计算的阶乘数。 该函数检查数字是否为1,如果为1,则返回res (Ending condition) 。 如果没有,则它创建一个变量new_res并为其分配先前res *当前num的值。 它返回我们的函数调用fact(new_res, num-1)返回的值。 这一直重复,直到我们得到num为1.一旦发生这种情况,我们得到结果。
让我们考虑另一个例子,逐个打印列表的每个元素。 为此,我们将利用列表中的hd和tl函数以及函数中的模式匹配 -
a = ["Hey", 100, 452, :true, "People"]
defmodule ListPrint do
def print([]) do
end
def print([head | tail]) do
IO.puts(head)
print(tail)
end
end
ListPrint.print(a)
当我们有一个空列表(ending condition)时,将调用第一个打印函数。 如果没有,则将调用第二个打印函数,该函数将列表分成2,并将列表的第一个元素指定为head,将列表的剩余部分指定为tail。 然后打印头,我们再次使用列表的其余部分(即tail)调用打印功能。 运行上述程序时,会产生以下结果 -
Hey
100
452
true
People
Elixir - Loops
由于不变性,Elixir中的循环(如在任何函数式编程语言中)与命令式语言的编写方式不同。 例如,在像C这样的命令式语言中,你会写 -
for(i = 0; i < 10; i++) {
printf("%d", array[i]);
}
在上面给出的例子中,我们正在改变数组和变量i 。 Elixir无法进行变异。 相反,函数语言依赖于递归:递归调用函数,直到达到阻止递归操作继续的条件。 此过程中没有数据发生变异。
现在让我们使用递归打印hello n次的简单循环。
defmodule Loop do
def print_multiple_times(msg, n) when n <= 1 do
IO.puts msg
end
def print_multiple_times(msg, n) do
IO.puts msg
print_multiple_times(msg, n - 1)
end
end
Loop.print_multiple_times("Hello", 10)
运行上述程序时,会产生以下结果 -
Hello
Hello
Hello
Hello
Hello
Hello
Hello
Hello
Hello
Hello
我们利用函数的模式匹配技术和递归来成功实现循环。 递归定义很难理解,但将循环转换为递归很容易。
Elixir为我们提供了Enum module 。 此模块用于大多数迭代循环调用,因为使用它们比尝试计算相同的递归定义要容易得多。 我们将在下一章讨论这些内容。 只有当您找不到使用该模块的解决方案时,才应使用您自己的递归定义。 这些函数是尾调用优化的并且非常快。
Elixir - Enumerables
可枚举是可以枚举的对象。 “枚举”是指逐个计算集合/集合/类别的成员(通常按顺序,通常按名称)。
Elixir提供了enumerables和Enum模块的概念来使用它们。 正如名称所述,Enum模块中的函数仅限于枚举数据结构中的值。 可枚举数据结构的示例是列表,元组,映射等.Enum模块为我们提供了100多个处理枚举的函数。 我们将在本章中讨论一些重要的功能。
all?
当我们all使用? 函数,整个集合必须评估为true否则将返回false。 例如,要检查列表中的所有元素是否都是奇数,那么。
res = Enum.all?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end)
IO.puts(res)
运行上述程序时,会产生以下结果 -
false
这是因为并非此列表的所有元素都是奇数。
any?
顾名思义,如果集合的任何元素的计算结果为true,则此函数返回true。 例如 -
res = Enum.any?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end)
IO.puts(res)
运行上述程序时,会产生以下结果 -
true
chunk
此函数将我们的集合划分为作为第二个参数提供的大小的小块。 例如 -
res = Enum.chunk([1, 2, 3, 4, 5, 6], 2)
IO.puts(res)
运行上述程序时,会产生以下结果 -
[[1, 2], [3, 4], [5, 6]]
each
可能有必要迭代一个集合而不产生新值,对于这种情况我们使用each函数 -
Enum.each(["Hello", "Every", "one"], fn(s) -> IO.puts(s) end)
运行上述程序时,会产生以下结果 -
Hello
Every
one
map
要将我们的函数应用于每个项目并生成一个新集合,我们使用map函数。 它是函数式编程中最有用的结构之一,因为它非常富有表现力和简洁性。 让我们考虑一个例子来理解这一点。 我们将存储在列表中的值加倍并将其存储在新的列表中 -
res = Enum.map([2, 5, 3, 6], fn(a) -> a*2 end)
IO.puts(res)
运行上述程序时,会产生以下结果 -
[4, 10, 6, 12]
reduce
reduce函数帮助我们将可枚举减少到单个值。 为此,我们提供一个可选的累加器(在本例中为5)以传递给我们的函数; 如果没有提供累加器,则使用第一个值 -
res = Enum.reduce([1, 2, 3, 4], 5, fn(x, accum) -> x + accum end)
IO.puts(res)
运行上述程序时,会产生以下结果 -
15
累加器是传递给fn的初始值。 从第二次调用开始,前一次调用返回的值将作为accum传递。 我们也可以使用reduce而不用累加器 -
res = Enum.reduce([1, 2, 3, 4], fn(x, accum) -> x + accum end)
IO.puts(res)
运行上述程序时,会产生以下结果 -
10
uniq
uniq函数从我们的集合中删除重复项,并仅返回集合中的元素集。 例如 -
res = Enum.uniq([1, 2, 2, 3, 3, 3, 4, 4, 4, 4])
IO.puts(res)
在程序上运行时,会产生以下结果 -
[1, 2, 3, 4]
急切的评价
Enum模块中的所有功能都非常渴望。 许多函数都期望枚举并返回一个列表。 这意味着当使用Enum执行多个操作时,每个操作都将生成一个中间列表,直到我们到达结果。 让我们考虑以下示例来理解这一点 -
odd? = &(odd? = &(rem(&1, 2) != 0)
res = 1..100_000 |> Enum.map(&(&1 * 3)) |> Enum.filter(odd?) |> Enum.sum
IO.puts(res)
运行上述程序时,会产生以下结果 -
7500000000
上面的例子有一个操作流程。 我们从一个范围开始,然后将范围中的每个元素乘以3.第一个操作现在将创建并返回一个包含100_000个项目的列表。 然后我们保留列表中的所有奇数元素,生成一个新列表,现在有50_000个项目,然后我们对所有条目求和。
上面代码片段中使用的符号是pipe operator :它只是从左侧的表达式获取输出,并将其作为第一个参数传递给右侧的函数调用。 它类似于Unix | 运算符。 其目的是突出由一系列功能转换的数据流。
没有pipe运算符,代码看起来很复杂 -
Enum.sum(Enum.filter(Enum.map(1..100_000, &(&1 * 3)), odd?))
我们还有许多其他功能,但这里只描述了一些重要的功能。
Elixir - Streams
许多函数都期望枚举并返回一个list 。 这意味着,在使用Enum执行多个操作时,每个操作都将生成一个中间列表,直到我们到达结果。
Streams支持延迟操作,而不是enums的急切操作。 简而言之, streams are lazy, composable enumerables 。 这意味着除非绝对需要,否则Streams不会执行操作。 让我们考虑一个例子来理解这一点 -
odd? = &(rem(&1, 2) != 0)
res = 1..100_000 |> Stream.map(&(&1 * 3)) |> Stream.filter(odd?) |> Enum.sum
IO.puts(res)
运行上述程序时,会产生以下结果 -
7500000000
在上面给出的示例中, 1..100_000 |》 Stream.map(&(&1 * 3))返回数据类型,即实际流,表示1..100_000范围内的地图计算。 它还没有评估这种表示。 流不构建中间列表,而是构建一系列计算,只有在我们将底层流传递给Enum模块时才会调用这些计算。 在处理大型集合(可能是无限集合)时,流非常有用。
流和枚举有许多共同的功能。 Streams主要提供Enum模块提供的相同功能,它在对输入枚举执行计算后生成Lists作为其返回值。 其中一些列在下表中 -
| Sr.No. | 功能及其描述 |
|---|---|
| 1 | chunk(enum, n, step, leftover \\ nil) 流可枚举的块,每个包含n个项目,其中每个新块将步骤元素启动到可枚举中。 |
| 2 | concat(enumerables) 创建一个枚举可枚举中每个可枚举的流。 |
| 3 | each(enum, fun) 为每个项执行给定的函数。 |
| 4 | filter(enum, fun) 创建一个根据枚举的给定函数过滤元素的流。 |
| 5 | map(enum, fun) 创建将在枚举上应用给定函数的流。 |
| 6 | drop(enum, n) 懒惰地从可枚举中删除下n个项目。 |
Elixir - Structs
结构是在地图之上构建的扩展,提供编译时检查和默认值。
定义结构
要定义结构,请使用defstruct构造:
defmodule User do
defstruct name: "John", age: 27
end
与defstruct一起使用的关键字列表定义了struct将包含哪些字段及其默认值。 结构取其定义的模块的名称。在上面给出的示例中,我们定义了一个名为User的结构。 我们现在可以使用类似于用于创建地图的语法来创建用户结构 -
new_john = %User{})
ayush = %User{name: "Ayush", age: 20}
megan = %User{name: "Megan"})
上面的代码将生成三个具有值的不同结构 -
%User{age: 27, name: "John"}
%User{age: 20, name: "Ayush"}
%User{age: 27, name: "Megan"}
Structs提供编译时保证,只允许通过defstruct定义的字段(以及所有字段)存在于结构中。 因此,一旦在模块中创建了结构,就无法定义自己的字段。
访问和更新结构
当我们讨论地图时,我们展示了如何访问和更新地图的字段。 相同的技术(和相同的语法)也适用于结构。 例如,如果我们想要更新我们在前面的示例中创建的用户,那么 -
defmodule User do
defstruct name: "John", age: 27
end
john = %User{}
#john right now is: %User{age: 27, name: "John"}
#To access name and age of John,
IO.puts(john.name)
IO.puts(john.age)
运行上述程序时,会产生以下结果 -
John
27
要更新结构中的值,我们将再次使用我们在map章节中使用的相同过程,
meg = %{john | name: "Meg"}
结构也可以用于模式匹配,既可以匹配特定键的值,也可以确保匹配值是与匹配值相同类型的结构。
Elixir - Protocols
协议是在Elixir中实现多态性的机制。 任何数据类型都可以调度协议,只要它实现协议即可。
让我们考虑使用协议的示例。 我们在前面的章节中使用了一个名为to_string的函数来将其他类型转换为字符串类型。 这实际上是一个协议。 它根据给出的输入动作而不会产生错误。 这似乎我们正在讨论模式匹配函数,但随着我们进一步发展,结果却不同。
请考虑以下示例以进一步了解协议机制。
让我们创建一个协议,显示给定输入是否为空。 我们将此协议称为blank? 。
定义协议
我们可以通过以下方式在Elixir中定义协议 -
defprotocol Blank do
def blank?(data)
end
如您所见,我们不需要为函数定义主体。 如果您熟悉其他编程语言中的接口,您可以将协议视为基本相同的东西。
所以这个协议说任何实现它的东西都必须是empty? 功能,虽然由实现者决定功能如何响应。 通过定义协议,让我们了解如何添加几个实现。
实施议定书
由于我们已经定义了一个协议,我们现在需要告诉它如何处理它可能获得的不同输入。 让我们以我们之前采取的例子为基础。 我们将为列表,映射和字符串实现空白协议。 这将显示我们传递的内容是否为空白。
#Defining the protocol
defprotocol Blank do
def blank?(data)
end
#Implementing the protocol for lists
defimpl Blank, for: List do
def blank?([]), do: true
def blank?(_), do: false
end
#Implementing the protocol for strings
defimpl Blank, for: BitString do
def blank?(""), do: true
def blank?(_), do: false
end
#Implementing the protocol for maps
defimpl Blank, for: Map do
def blank?(map), do: map_size(map) == 0
end
IO.puts(Blank.blank? [])
IO.puts(Blank.blank? [:true, "Hello"])
IO.puts(Blank.blank? "")
IO.puts(Blank.blank? "Hi")
您可以根据需要为多种或多种类型实现协议,无论对协议的使用有何意义。 这是一个非常基本的协议用例。 运行上述程序时,会产生以下结果 -
true
false
true
false
Note - 如果将此用于除定义协议之外的任何类型,则会产生错误。
Elixir - File IO
文件IO是任何编程语言不可或缺的一部分,因为它允许语言与文件系统上的文件进行交互。 在本章中,我们将讨论两个模块 - 路径和文件。
路径模块
path模块是一个非常小的模块,可以被视为文件系统操作的辅助模块。 File模块中的大多数函数都将path作为参数。 最常见的是,这些路径将是常规二进制文件。 Path模块提供了处理此类路径的工具。 由于Path模块透明地处理不同的操作系统,因此首选使用Path模块中的函数而不是仅操作二进制文件。 可以看出,Elixir会在执行文件操作时自动将斜杠(/)转换为Windows上的反斜杠(\)。
让我们考虑以下示例来进一步了解Path模块 -
IO.puts(Path.join("foo", "bar"))
运行上述程序时,会产生以下结果 -
foo/bar
路径模块提供了许多方法。 您可以在here查看不同的方法。 如果要执行许多文件操作操作,则经常使用这些方法。
文件模块
文件模块包含允许我们将文件作为IO设备打开的功能。 默认情况下,文件以二进制模式打开,这要求开发人员使用IO模块中的特定IO.binread和IO.binwrite函数。 让我们创建一个名为newfile的文件并向其写入一些数据。
{:ok, file} = File.read("newfile", [:write])
# Pattern matching to store returned stream
IO.binwrite(file, "This will be written to the file")
如果您打开我们刚写入的文件,内容将以下列方式显示 -
This will be written to the file
现在让我们了解如何使用文件模块。
打开文件
要打开文件,我们可以使用以下两个功能中的任何一个 -
{:ok, file} = File.open("newfile")
file = File.open!("newfile")
现在让我们理解File.open函数和File.open!()函数之间的区别。
File.open函数始终返回一个元组。 如果文件成功打开,它会将元组中的第一个值返回为:ok ,第二个值是io_device类型的文字。 如果导致错误,它将返回具有第一个值的元组:error和第二个值作为原因。
另一方面,如果文件成功打开, File.open!()函数将返回io_device ,否则会引发错误。 注意:这是我们将要讨论的所有文件模块函数中遵循的模式。
我们还可以指定要打开此文件的模式。 要以只读和utf-8编码模式打开文件,我们使用以下代码 -
file = File.open!("newfile", [:read, :utf8])
写入文件
我们有两种方法可以写入文件。 让我们看一下使用File模块中的write函数的第一个。
File.write("newfile", "Hello")
但是,如果要对同一文件进行多次写入,则不应使用此方法。 每次调用此函数时,都会打开文件描述符,并生成一个新进程以写入该文件。 如果您在循环中进行多次写入,请通过File.open打开该文件,并使用IO模块中的方法写入该文件。 让我们考虑一个例子来理解相同的 -
#Open the file in read, write and utf8 modes.
file = File.open!("newfile_2", [:read, :utf8, :write])
#Write to this "io_device" using standard IO functions
IO.puts(file, "Random text")
您可以使用其他IO模块方法(如IO.write和IO.binwrite写入以io_device打开的文件。
从文件中读取
我们有两种方法可以从文件中读取。 让我们看一下使用File模块中的read函数的第一个。
IO.puts(File.read("newfile"))
运行此代码时,您应该获得一个元组,第一个元素为:ok ,第二个元素作为newfile的内容
我们也可以使用File.read! 函数只是获取返回给我们的文件的内容。
关闭打开的文件
每当使用File.open函数打开文件时,在使用完文件后,应使用File.close函数关闭它 -
File.close(file)
Elixir - Processes
在Elixir中,所有代码都在进程内运行。 进程彼此隔离,彼此并发运行并通过消息传递进行通信。 Elixir的流程不应与操作系统流程混淆。 Elixir中的进程在内存和CPU方面非常轻量级(与许多其他编程语言中的线程不同)。 因此,同时运行数十甚至数十万个进程并不罕见。
在本章中,我们将了解产生新进程的基本结构,以及在不同进程之间发送和接收消息。
产卵功能
创建新进程的最简单方法是使用spawn函数。 spawn接受将在新进程中运行的函数。 例如 -
pid = spawn(fn -> 2 * 2 end)
Process.alive?(pid)
运行上述程序时,会产生以下结果 -
false
spawn函数的返回值是PID。 这是进程的唯一标识符,因此如果您运行PID上方的代码,它将是不同的。 正如您在此示例中所看到的,当我们检查它是否存活时,该过程已经死亡。 这是因为一旦完成运行给定函数,进程就会退出。
如前所述,所有Elixir代码都在进程内运行。 如果您运行自我功能,您将看到当前会话的PID -
pid = self
Process.alive?(pid)
运行上述程序时,会产生以下结果 -
true
消息传递
我们可以通过发送向进程发送消息,并通过接收接收它们。 让我们将消息传递给当前进程并在其上接收它。
send(self(), {:hello, "Hi people"})
receive do
{:hello, msg} -> IO.puts(msg)
{:another_case, msg} -> IO.puts("This one won't match!")
end
运行上述程序时,会产生以下结果 -
Hi people
我们使用send函数向当前进程发送了一条消息,并将其传递给了self of PID。 然后我们使用receive函数处理传入的消息。
将消息发送到进程时,该消息将存储在process mailbox 。 接收块通过当前进程邮箱搜索与任何给定模式匹配的消息。 接收块支持警卫和许多子句,例如case。
如果邮箱中没有与任何模式匹配的消息,则当前进程将等待,直到匹配的消息到达。 也可以指定超时。 例如,
receive do
{:hello, msg} -> msg
after
1_000 -> "nothing after 1s"
end
运行上述程序时,会产生以下结果 -
nothing after 1s
NOTE - 当您希望邮件在邮箱中时,可以给出超时0。
Links
Elixir中最常见的产卵形式实际上是通过spawn_link函数。 在查看spawn_link的示例之前,让我们了解一个进程失败时会发生什么。
spawn fn -> raise "oops" end
运行上述程序时,会产生以下错误 -
[error] Process #PID<0.58.00> raised an exception
** (RuntimeError) oops
:erlang.apply/2
它记录了一个错误,但产生过程仍在运行。 这是因为流程是孤立的。 如果我们希望一个进程中的失败传播到另一个进程,我们需要链接它们。 这可以使用spawn_link函数完成。 让我们考虑一个例子来理解相同的 -
spawn_link fn -> raise "oops" end
运行上述程序时,会产生以下错误 -
** (EXIT from #PID<0.41.0>) an exception was raised:
** (RuntimeError) oops
:erlang.apply/2
如果你在iex shell中运行它,那么shell会处理这个错误并且不会退出。 但是如果你先运行一个脚本文件,然后使用elixir 《file-name》.exs ,那么父进程也会因为这个失败而被关闭。
在构建容错系统时,进程和链接起着重要作用。 在Elixir应用程序中,我们经常将我们的流程链接到主管,主管将检测流程何时死亡并在其位置启动新流程。 这是唯一可行的,因为进程是隔离的,默认情况下不共享任何内容。 由于流程是孤立的,因此流程中的故障不会崩溃或破坏另一个流程的状态。 而其他语言将要求我们捕获/处理异常; 在Elixir,我们实际上很好地让流程失败,因为我们希望主管能够正确地重启我们的系统。
State
例如,如果要构建一个需要状态的应用程序来保持应用程序配置,或者需要解析文件并将其保存在内存中,那么您将在何处存储它? Elixir的流程功能在执行此类操作时可以派上用场。
我们可以编写无限循环,维护状态,发送和接收消息的进程。 作为一个例子,让我们编写一个模块来启动新进程,这些进程在名为kv.exs的文件中用作键值存储。
defmodule KV do
def start_link do
Task.start_link(fn -> loop(%{}) end)
end
defp loop(map) do
receive do
{:get, key, caller} ->
send caller, Map.get(map, key)
loop(map)
{:put, key, value} ->
loop(Map.put(map, key, value))
end
end
end
请注意, start_link函数启动一个运行loop函数的新进程,从空映射开始。 然后loop函数等待消息并对每条消息执行适当的操作。 在a :get消息的情况下,它将消息发送回调用者并再次调用循环,以等待新消息。 虽然:put消息实际上使用新版本的地图调用loop ,但存储了给定的键和值。
现在让我们运行以下内容 -
iex kv.exs
现在你应该进入你的iex shell。 要测试我们的模块,请尝试以下方法 -
{:ok, pid} = KV.start_link
# pid now has the pid of our new process that is being
# used to get and store key value pairs
# Send a KV pair :hello, "Hello" to the process
send pid, {:put, :hello, "Hello"}
# Ask for the key :hello
send pid, {:get, :hello, self()}
# Print all the received messages on the current process.
flush()
运行上述程序时,会产生以下结果 -
"Hello"
Elixir - Sigils
在本章中,我们将探讨sigils,即语言提供的用于处理文本表示的机制。 Sigils以波浪号(〜)字符开头,后跟一个字母(标识符号),然后是分隔符; 可选地,可以在最终分隔符之后添加修饰符。
Regex
Elixir中的正则表达是符号。 我们已经在String章节中看到了它们的用法。 让我们再举一个例子来看看我们如何在Elixir中使用正则表达式。
# A regular expression that matches strings which contain "foo" or
# "bar":
regex = ~r/foo|bar/
IO.puts("foo" =~ regex)
IO.puts("baz" =~ regex)
运行上述程序时,会产生以下结果 -
true
false
Sigils支持8种不同的分隔符 -
~r/hello/
~r|hello|
~r"hello"
~r'hello'
~r(hello)
~r[hello]
~r{hello}
~r<hello>
支持不同分隔符背后的原因是不同的分隔符可能更适合不同的符号。 例如,对正则表达式使用括号可能是一个令人困惑的选择,因为它们可能与正则表达式中的括号混合在一起。 但是,括号可以方便其他符号,我们将在下一节中看到。
Elixir支持Perl兼容的正则表达式,也支持修饰符。 您可以here阅读有关正则表达式使用的更多信息。
字符串,字符列表和Word列表
除了正则表达式,Elixir还有3个内置的印记。 让我们来看看这些印记。
Strings
~s sigil用于生成字符串,如双引号。 例如,当一个字符串包含双引号和单引号时,~s sigil很有用 -
new_string = ~s(this is a string with "double" quotes, not 'single' ones)
IO.puts(new_string)
这个印记产生字符串。 运行上述程序时,会产生以下结果 -
"this is a string with \"double\" quotes, not 'single' ones"
字符列表
~c sigil用于生成字符列表 -
new_char_list = ~c(this is a char list containing 'single quotes')
IO.puts(new_char_list)
运行上述程序时,会产生以下结果 -
this is a char list containing 'single quotes'
单词列表
~w sigil用于生成单词列表(单词只是常规字符串)。 在w w sigil中,单词由空格分隔。
new_word_list = ~w(foo bar bat)
IO.puts(new_word_list)
运行上述程序时,会产生以下结果 -
foobarbat
~w sigil还接受c, s和修饰符(分别用于char列表,字符串和原子),它们指定结果列表元素的数据类型 -
new_atom_list = ~w(foo bar bat)a
IO.puts(new_atom_list)
运行上述程序时,会产生以下结果 -
[:foo, :bar, :bat]
Sigils中的插值和逃逸
除了小写符号之外,Elixir还支持大写符号来处理转义字符和插值。 虽然~s和~S都将返回字符串,但前者允许转义码和插值,而后者则不允许。 让我们考虑一个例子来理解这一点 -
~s(String with escape codes \x26 #{"inter" <> "polation"})
# "String with escape codes & interpolation"
~S(String without escape codes \x26 without #{interpolation})
# "String without escape codes \\x26 without \#{interpolation}"
自定义印记
我们可以轻松创建自己的自定义标记。 在这个例子中,我们将创建一个sigil来将字符串转换为大写。
defmodule CustomSigil do
def sigil_u(string, []), do: String.upcase(string)
end
import CustomSigil
IO.puts(~u/tutorials point/)
当我们运行上面的代码时,它会产生以下结果 -
TUTORIALS POINT
首先我们定义一个名为CustomSigil的模块,在该模块中,我们创建了一个名为sigil_u的函数。 由于现有的印记空间中没有现存的印记,我们将使用它。 _u表示我们希望使用u作为波浪号后面的字符。 函数定义必须带两个参数,一个输入和一个列表。
Elixir - Comprehensions
列表推导是用于循环Elixir中的可枚举的语法糖。 在本章中,我们将使用理解进行迭代和生成。
Basics
当我们在enumerables章节中查看Enum模块时,我们遇到了map函数。
Enum.map(1..3, &(&1 * 2))
在这个例子中,我们将传递一个函数作为第二个参数。 范围中的每个项目都将传递给函数,然后将返回包含新值的新列表。
映射,过滤和转换是Elixir中非常常见的操作,因此实现与前一个示例相同的结果的方法略有不同 -
for n <- 1..3, do: n * 2
当我们运行上面的代码时,它会产生以下结果 -
[2, 4, 6]
第二个例子是一个理解,正如你可能看到的,如果你使用Enum.map函数,它只是你可以实现的语法糖。 但是,在性能方面使用对Enum模块的函数的理解没有任何实际好处。
理解不仅限于列表,而是可以与所有可用的枚举一起使用。
Filter
您可以将过滤器视为一种理解的保护。 当筛选的值返回false或nil它将从最终列表中排除。 让我们循环一个范围,只担心偶数。 我们将使用Integer模块中的is_even函数来检查值是否为偶数。
import Integer
IO.puts(for x <- 1..10, is_even(x), do: x)
运行上面的代码时,它会产生以下结果 -
[2, 4, 6, 8, 10]
我们也可以在相同的理解中使用多个过滤器。 在用逗号分隔的is_even过滤器后添加所需的另一个过滤器。
:进入期权
在上面的示例中,返回的所有理解都列出了结果。 但是,通过将:into选项传递给理解,可以将理解的结果插入到不同的数据结构中。
例如,一个bitstring生成器可以与:into选项一起使用,以便轻松删除字符串中的所有空格 -
IO.puts(for <<c <- " hello world ">>, c != ?\s, into: "", do: <<c>>)
运行上面的代码时,它会产生以下结果 -
helloworld
上面的代码使用c != ?\s过滤器从字符串中删除所有空格,然后使用:into选项,它将所有返回的字符放在一个字符串中。
Elixir - Typespecs
Elixir是一种动态类型语言,因此Elixir中的所有类型都是由运行时推断的。 尽管如此,Elixir还带有typespecs,这是一种用于declaring custom data types and declaring typed function signatures (specifications) 。
Function Specifications(specs)
默认情况下,Elixir提供了一些基本类型,例如integer或pid,以及复杂类型:例如, round函数将float转换为其最接近的整数,将一个数字作为参数(整数或浮点数)和返回一个整数。 在相关documentation ,圆形类型签名写为 -
round(number) :: integer
上面的描述暗示左边的函数作为参数在括号中指定,并返回::,即Integer右边的内容。 函数规范使用@spec指令编写,放在函数定义之前。 圆函数可写为 -
@spec round(number) :: integer
def round(number), do: # Function implementation
...
Typespecs也支持复杂类型,例如,如果要返回整数列表,则可以使用[Integer]
自定义类型
虽然Elixir提供了许多有用的内置类型,但在适当的时候定义自定义类型很方便。 这可以通过@type指令定义模块来完成。 让我们考虑一个例子来理解相同的 -
defmodule FunnyCalculator do
@type number_with_joke :: {number, String.t}
@spec add(number, number) :: number_with_joke
def add(x, y), do: {x + y, "You need a calculator to do that?"}
@spec multiply(number, number) :: number_with_joke
def multiply(x, y), do: {x * y, "It is like addition on steroids."}
end
{result, comment} = FunnyCalculator.add(10, 20)
IO.puts(result)
IO.puts(comment)
运行上述程序时,会产生以下结果 -
30
You need a calculator to do that?
NOTE - 通过@type定义的自定义类型将被导出,并在定义它们的模块之外可用。如果要将自定义类型保持为私有,则可以使用@typep指令而不是@type 。
Elixir - Behaviours
Elixir(和Erlang)中的行为是一种从特定部分(它成为回调模块)中分离和抽象组件的通用部分(它成为行为模块)的方法。 行为提供了一种方法 -
- 定义一组必须由模块实现的功能。
- 确保模块实现该集合中的所有功能。
如果必须,您可以考虑像Java这样的面向对象语言中的接口行为:模块必须实现的一组函数签名。
定义行为
让我们考虑一个示例来创建自己的行为,然后使用此通用行为来创建模块。 我们将定义一种行为,用不同的语言向人们打招呼和再见。
defmodule GreetBehaviour do
@callback say_hello(name :: string) :: nil
@callback say_bye(name :: string) :: nil
end
@callback指令用于列出采用模块需要定义的函数。 它还指定了号码。 参数,类型和返回值。
采用行为
我们已成功定义了一种行为。 现在我们将在多个模块中采用和实现它。 让我们创建两个用英语和西班牙语实现这种行为的模块。
defmodule GreetBehaviour do
@callback say_hello(name :: string) :: nil
@callback say_bye(name :: string) :: nil
end
defmodule EnglishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hello " <> name)
def say_bye(name), do: IO.puts("Goodbye, " <> name)
end
defmodule SpanishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hola " <> name)
def say_bye(name), do: IO.puts("Adios " <> name)
end
EnglishGreet.say_hello("Ayush")
EnglishGreet.say_bye("Ayush")
SpanishGreet.say_hello("Ayush")
SpanishGreet.say_bye("Ayush")
运行上述程序时,会产生以下结果 -
Hello Ayush
Goodbye, Ayush
Hola Ayush
Adios Ayush
正如您已经看到的,我们在模块中使用@behaviour指令的行为。 我们必须定义所有child模块的行为中实现的所有函数。 这可以大致被认为等同于OOP语言中的接口。
Elixir - Errors Handling
Elixir有三种错误机制:错误,抛出和退出。 让我们详细探讨每种机制。
Error
当代码中发生异常事件时,将使用错误(或异常)。 尝试将数字添加到字符串中可以检索样本错误 -
IO.puts(1 + "Hello")
运行上述程序时,会产生以下错误 -
** (ArithmeticError) bad argument in arithmetic expression
:erlang.+(1, "Hello")
这是一个内置错误示例。
提高错误
我们可以使用raise函数raise错误。 让我们考虑一个例子来理解相同的 -
#Runtime Error with just a message
raise "oops" # ** (RuntimeError) oops
通过raise/2传递错误名称和关键字参数列表,可以引发其他错误
#Other error type with a message
raise ArgumentError, message: "invalid argument foo"
您还可以定义自己的错误并提高它们。 考虑以下示例 -
defmodule MyError do
defexception message: "default message"
end
raise MyError # Raises error with default message
raise MyError, message: "custom message" # Raises error with custom message
拯救错误
我们不希望我们的程序突然退出,而是需要仔细处理错误。 为此,我们使用错误处理。 我们使用try/rescue构造来挽救错误。 让我们考虑下面的例子来理解相同的 -
err = try do
raise "oops"
rescue
e in RuntimeError -> e
end
IO.puts(err.message)
运行上述程序时,会产生以下结果 -
oops
我们使用模式匹配处理了救援声明中的错误。 如果我们没有使用任何错误,并且只想将其用于识别目的,我们也可以使用表格 -
err = try do
1 + "Hello"
rescue
RuntimeError -> "You've got a runtime error!"
ArithmeticError -> "You've got a Argument error!"
end
IO.puts(err)
在程序上运行时,会产生以下结果 -
You've got a Argument error!
NOTE - Elixir标准库中的大多数函数都实现了两次,一次返回元组,另一次引发错误。 例如,File.read和File.read! 功能。 如果文件被成功读取,则第一个返回元组,如果遇到错误,则使用此元组给出错误的原因。 如果遇到错误,第二个引发错误。
如果我们使用第一个函数方法,那么我们需要使用case匹配错误的模式并根据它采取行动。 在第二种情况下,我们使用try rescue方法来处理容易出错的代码并相应地处理错误。
Throws
在Elixir中,可以抛出一个值,然后被捕获。 Throw和Catch保留用于无法检索值的情况,除非使用throw和catch。
除了与库连接外,实例在实践中非常罕见。 例如,现在让我们假设Enum模块没有提供任何用于查找值的API,我们需要在数字列表中找到13的第一个倍数 -
val = try do
Enum.each 20..100, fn(x) ->
if rem(x, 13) == 0, do: throw(x)
end
"Got nothing"
catch
x -> "Got #{x}"
end
IO.puts(val)
运行上述程序时,会产生以下结果 -
Got 26
退出 (Exit)
当一个进程死于“自然原因”(例如,未处理的异常)时,它会发送一个退出信号。 过程也可以通过显式发送退出信号而死亡。 让我们考虑以下示例 -
spawn_link fn -> exit(1) end
在上面的示例中,链接进程通过发送值为1的退出信号而死亡。请注意,退出也可以使用try/catch“捕获”。 例如 -
val = try do
exit "I am exiting"
catch
:exit, _ -> "not really"
end
IO.puts(val)
运行上述程序时,会产生以下结果 -
not really
After
有时需要确保在某些可能引发错误的操作之后清理资源。 try/after结构允许您这样做。 例如,我们可以打开一个文件并使用after子句来关闭它 - 即使出现问题。
{:ok, file} = File.open "sample", [:utf8, :write]
try do
IO.write file, "olá"
raise "oops, something went wrong"
after
File.close(file)
end
当我们运行这个程序时,它会给我们一个错误。 但是after语句将确保在任何此类事件时关闭文件描述符。
Elixir - Macros
宏是Elixir最先进和最强大的功能之一。 与任何语言的所有高级功能一样,应谨慎使用宏。 它们使得在编译时执行强大的代码转换成为可能。 我们现在将了解宏是什么以及如何简单地使用它们。
Quote
在我们开始讨论宏之前,让我们先来看看Elixir内部。 Elixir程序可以由其自己的数据结构表示。 Elixir程序的构建块是一个包含三个元素的元组。 例如,函数调用sum(1,2,3)在内部表示为 -
{:sum, [], [1, 2, 3]}
第一个元素是函数名称,第二个元素是包含元数据的关键字列表,第三个是参数列表。 如果您编写以下内容,可以将此作为iex shell中的输出 -
quote do: sum(1, 2, 3)
运算符也表示为这样的元组。 变量也使用这样的三元组来表示,除了最后一个元素是原子而不是列表。 当引用更复杂的表达式时,我们可以看到代码在这样的元组中表示,这些元组通常在类似于树的结构中彼此嵌套。 许多语言将此类表示称为Abstract Syntax Tree (AST) 。 Elixir称这些引用的表达式。
Unquote
现在我们可以检索代码的内部结构,我们如何修改它? 要注入新的代码或值,我们使用unquote 。 当我们取消引用表达式时,它将被评估并注入AST。 让我们考虑一个例子(在iex shell中)来理解这个概念 -
num = 25
quote do: sum(15, num)
quote do: sum(15, unquote(num))
运行上述程序时,会产生以下结果 -
{:sum, [], [15, {:num, [], Elixir}]}
{:sum, [], [15, 25]}
在引用表达式的示例中,它没有自动将num替换为25.如果我们想要修改AST,则需要取消引用此变量。
Macros
所以现在我们熟悉quote和unquote,我们可以使用宏来探索Elixir中的元编程。
在最简单的术语中,宏是特殊函数,用于返回将插入到我们的应用程序代码中的带引号的表达式。 想象一下,宏被引用的表达式替换而不是像函数一样调用。 使用宏,我们拥有扩展Elixir并动态添加代码到应用程序所需的一切
除非作为宏,否则让我们实施。 我们将首先使用defmacro宏定义宏。 请记住,我们的宏需要返回一个带引号的表达式。
defmodule OurMacro do
defmacro unless(expr, do: block) do
quote do
if !unquote(expr), do: unquote(block)
end
end
end
require OurMacro
OurMacro.unless true, do: IO.puts "True Expression"
OurMacro.unless false, do: IO.puts "False expression"
运行上述程序时,会产生以下结果 -
False expression
这里发生的是我们的代码正在被unless宏返回的引用代码所取代。 我们没有引用该表达式来在当前上下文中对其进行求值,并且还没有引用do块来在其上下文中执行它。 这个例子向我们展示了在elixir中使用宏的元编程。
宏可用于更复杂的任务,但应谨慎使用。 这是因为元编程通常被认为是一种不好的做法,只应在必要时使用。
Elixir - Libraries
Elixir提供与Erlang库的出色互操作性。 让我们简要讨论几个库。
二进制模块
内置的Elixir String模块处理UTF-8编码的二进制文件。 当您处理不一定是UTF-8编码的二进制数据时,二进制模块很有用。 让我们考虑一个例子来进一步理解二进制模块 -
# UTF-8
IO.puts(String.to_char_list("Ø"))
# binary
IO.puts(:binary.bin_to_list "Ø")
运行上述程序时,会产生以下结果 -
[216]
[195, 152]
上面的例子显示了差异; String模块返回UTF-8代码点,而:binary处理原始数据字节。
加密模块
加密模块包含散列函数,数字签名,加密等。 此模块不是Erlang标准库的一部分,但包含在Erlang发行版中。 这意味着您必须在项目的应用程序列表中列出:crypto,无论何时使用它。 让我们看一个使用加密模块的例子 -
IO.puts(Base.encode16(:crypto.hash(:sha256, "Elixir")))
运行上述程序时,会产生以下结果 -
3315715A7A3AD57428298676C5AE465DADA38D951BDFAC9348A8A31E9C7401CB
有向图模块
有向图模块包含用于处理由顶点和边构建的有向图的函数。 在构建图形之后,其中的算法将有助于找到例如图形中两个顶点或循环之间的最短路径。 请注意, in :digraph中的函数间接地将图形结构更改为副作用,同时返回添加的顶点或边。
digraph = :digraph.new()
coords = [{0.0, 0.0}, {1.0, 0.0}, {1.0, 1.0}]
[v0, v1, v2] = (for c <- coords, do: :digraph.add_vertex(digraph, c))
:digraph.add_edge(digraph, v0, v1)
:digraph.add_edge(digraph, v1, v2)
for point <- :digraph.get_short_path(digraph, v0, v2) do
{x, y} = point
IO.puts("#{x}, #{y}")
end
运行上述程序时,会产生以下结果 -
0.0, 0.0
1.0, 0.0
1.0, 1.0
数学模块
数学模块包含常见的数学运算,涵盖三角函数,指数函数和对数函数。 让我们考虑以下示例来理解Math模块的工作原理 -
# Value of pi
IO.puts(:math.pi())
# Logarithm
IO.puts(:math.log(7.694785265142018e23))
# Exponentiation
IO.puts(:math.exp(55.0))
#...
运行上述程序时,会产生以下结果 -
3.141592653589793
55.0
7.694785265142018e23
队列模块
队列是一种有效实现(双端)FIFO(先进先出)队列的数据结构。 以下示例显示了Queue模块的工作原理 -
q = :queue.new
q = :queue.in("A", q)
q = :queue.in("B", q)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)
运行上述程序时,会产生以下结果 -
A
B
