AWK - 快速指南
AWK - Overview
AWK是一种解释性编程语言。 它非常强大,专为文本处理而设计。 它的名字来源于其作者的姓氏Alfred Aho, Peter Weinberger, and Brian Kernighan.
GNU/Linux分发的AWK版本由自由软件基金会(FSF)编写和维护; 它通常被称为GNU AWK.
AWK的类型
以下是AWK的变种 -
AWK - 来自AT&T实验室的原创AWK。
NAWK - 来自AT&T实验室的更新和改进的AWK版本。
GAWK - 它是GNU AWK。 所有GNU/Linux发行版都提供GAWK。 它与AWK和NAWK完全兼容。
AWK的典型用途
使用AWK可以完成无数的任务。 下面列出的只是其中的一小部分 -
- 文字处理,
- 生成格式化文本报告,
- 执行算术运算,
- 执行字符串操作等等。
AWK - Environment
本章介绍如何在GNU/Linux系统上设置AWK环境。
使用包管理器安装
通常,AWK在大多数GNU/Linux发行版中默认可用。 您可以使用which命令检查系统上是否存在which命令。 如果您没有AWK,请使用高级软件包工具(APT)软件包管理器在基于Debian的GNU/Linux上安装它,如下所示 -
[jeryy]$ sudo apt-get update
[jeryy]$ sudo apt-get install gawk
同样,要在基于RPM的GNU/Linux上安装AWK,请使用Yellowdog Updator Modifier yum包管理器,如下所示 -
[root]# yum install gawk
安装后,确保可以通过命令行访问AWK。
[jerry]$ which awk
执行上面的代码时,您会得到以下结果 -
/usr/bin/awk
从源代码安装
由于GNU AWK是GNU项目的一部分,因此可以免费下载其源代码。 我们已经看到了如何使用包管理器安装AWK。 现在让我们了解如何从源代码安装AWK。
以下安装适用于任何GNU/Linux软件,以及大多数其他可自由使用的程序。 以下是安装步骤 -
Step 1 - 从真实的地方下载源代码。 命令行实用程序wget用于此目的。
[jerry]$ wget http://ftp.gnu.org/gnu/gawk/gawk-4.1.1.tar.xz
Step 2 - 解压缩并解压缩下载的源代码。
[jerry]$ tar xvf gawk-4.1.1.tar.xz
Step 3 - 切换到目录并运行configure。
[jerry]$ ./configure
Step 4 - 成功完成后, configure生成Makefile。 要编译源代码,请发出make命令。
[jerry]$ make
Step 5 - 您可以运行测试套件以确保构建是干净的。 这是一个可选步骤。
[jerry]$ make check
Step 6 - 最后,安装AWK。 确保您拥有超级用户权限。
[jerry]$ sudo make install
这就对了! 您已成功编译并安装了AWK。 通过执行awk命令验证它,如下所示 -
[jerry]$ which awk
执行此代码时,您将获得以下结果 -
/usr/bin/awk
AWK - Workflow
要成为AWK专家程序员,您需要了解其内部结构。 AWK遵循一个简单的工作流程 - 读取,执行和重复。 下图描绘了AWK的工作流程 -
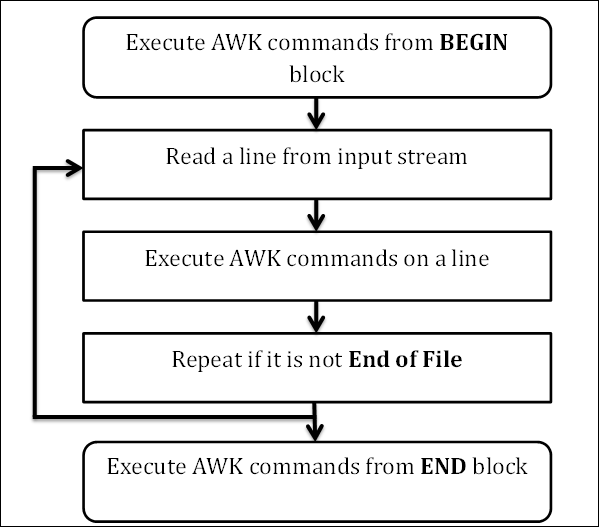
Read
AWK从输入流(文件,管道或标准输入)读取一行并将其存储在内存中。
执行 (Execute)
所有AWK命令都按顺序应用于输入。 默认情况下,AWK在每一行上执行命令。 我们可以通过提供模式来限制它。
Repeat
重复此过程直到文件结束。
计划结构
现在让我们了解AWK的程序结构。
BEGIN块
BEGIN块的语法如下 -
Syntax
BEGIN {awk-commands}
BEGIN块在程序启动时执行。 它只执行一次。 这是初始化变量的好地方。 BEGIN是一个AWK关键字,因此它必须是大写的。 请注意,此块是可选的。
身体块
主体块的语法如下 -
Syntax
/pattern/ {awk-commands}
主体块在每个输入行上应用AWK命令。 默认情况下,AWK在每一行上执行命令。 我们可以通过提供模式来限制它。 请注意,Body块没有关键字。
结束块
END块的语法如下 -
Syntax
END {awk-commands}
END块在程序结束时执行。 END是一个AWK关键字,因此它必须是大写的。 请注意,此块是可选的。
让我们创建一个文件marks.txt ,其中包含序列号,学生姓名,科目名称和获得的分数。
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
现在让我们使用AWK脚本显示带有标题的文件内容。
Example
[jerry]$ awk 'BEGIN{printf "Sr No\tName\tSub\tMarks\n"} {print}' marks.txt
执行此代码时,会产生以下结果 -
Output
Sr No Name Sub Marks
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
在开始时,AWK打印BEGIN块的标题。 然后在body块中,它从文件中读取一行并执行AWK的print命令,该命令只打印标准输出流上的内容。 重复此过程直到文件到达结尾。
AWK - Basic Syntax
AWK易于使用。 我们可以直接从命令行或以包含AWK命令的文本文件的形式提供AWK命令。
AWK Command Line
我们可以在命令行的单引号内指定一个AWK命令,如图所示 -
awk [options] file ...
例子 (Example)
考虑一个带有以下内容的文本文件marks.txt -
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
让我们使用AWK显示文件的完整内容,如下所示 -
Example
[jerry]$ awk '{print}' marks.txt
执行此代码时,您将获得以下结果 -
Output
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
AWK程序文件
我们可以在脚本文件中提供AWK命令,如图所示 -
awk [options] -f file ....
首先,创建一个包含AWK命令的文本文件command.awk ,如下所示 -
{print}
现在我们可以指示AWK从文本文件中读取命令并执行操作。 在这里,我们获得了与上例中所示相同的结果。
Example
[jerry]$ awk -f command.awk marks.txt
执行此代码时,您将获得以下结果 -
Output
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
AWK标准选项
AWK支持以下标准选项,可以从命令行提供。
-v选项
此选项为变量赋值。 它允许在程序执行之前进行分配。 以下示例描述了-v选项的用法。
Example
[jerry]$ awk -v name=Jerry 'BEGIN{printf "Name = %s\n", name}'
执行此代码时,您将获得以下结果 -
Output
Name = Jerry
--dump-variables [= file]选项
它将全局变量的排序列表及其最终值打印到文件中。 默认文件是awkvars.out 。
Example
[jerry]$ awk --dump-variables ''
[jerry]$ cat awkvars.out
执行上面的代码时,您会得到以下结果 -
Output
ARGC: 1
ARGIND: 0
ARGV: array, 1 elements
BINMODE: 0
CONVFMT: "%.6g"
ERRNO: ""
FIELDWIDTHS: ""
FILENAME: ""
FNR: 0
FPAT: "[^[:space:]]+"
FS: " "
IGNORECASE: 0
LINT: 0
NF: 0
NR: 0
OFMT: "%.6g"
OFS: " "
ORS: "\n"
RLENGTH: 0
RS: "\n"
RSTART: 0
RT: ""
SUBSEP: "\034"
TEXTDOMAIN: "messages"
--help选项
此选项在标准输出上打印帮助消息。
Example
[jerry]$ awk --help
执行此代码时,您将获得以下结果 -
Output
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options : GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options : GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-L [fatal] --lint[=fatal]
-n --non-decimal-data
-N --use-lc-numeric
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
--lint [=致命]选项
此选项可以检查非可移植或可疑的构造。 当提供fatal参数时,它会将警告消息视为错误。 以下示例演示了这一点 -
Example
[jerry]$ awk --lint '' /bin/ls
执行此代码时,您将获得以下结果 -
Output
awk: cmd. line:1: warning: empty program text on command line
awk: cmd. line:1: warning: source file does not end in newline
awk: warning: no program text at all!
--posix选项
此选项打开严格的POSIX兼容性,其中禁用所有常见和特定于gawk的扩展。
--profile [= file]选项
此选项在文件中生成漂亮的程序版本。 默认文件是awkprof.out 。 以下简单示例说明了这一点
Example
[jerry]$ awk --profile 'BEGIN{printf"---|Header|--\n"} {print}
END{printf"---|Footer|---\n"}' marks.txt > /dev/null
[jerry]$ cat awkprof.out
执行此代码时,您将获得以下结果 -
Output
# gawk profile, created Sun Oct 26 19:50:48 2014
# BEGIN block(s)
BEGIN {
printf "---|Header|--\n"
}
# Rule(s) {
print $0
}
# END block(s)
END {
printf "---|Footer|---\n"
}
- 传统选项
此选项禁用所有特定于gawk的扩展。
--version选项
此选项显示AWK程序的版本信息。
Example
[jerry]$ awk --version
执行此代码时,会产生以下结果 -
Output
GNU Awk 4.0.1
Copyright (C) 1989, 1991-2012 Free Software Foundation.
AWK - Basic Examples
本章介绍了几个有用的AWK命令及其相应的示例。 考虑使用以下内容处理的文本文件marks.txt -
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
打印列或字段
您可以指示AWK仅输入输入字段中的某些列。 以下示例演示了这一点 -
例子 (Example)
[jerry]$ awk '{print $3 "\t" $4}' marks.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Physics 80
Maths 90
Biology 87
English 85
History 89
在文件marks.txt ,第三列包含主题名称,第四列包含在特定主题中获得的标记。 让我们使用AWK打印命令打印这两列。 在上面的例子中, $3 and $4代表输入记录中的第三个和第四个字段。
打印所有行
默认情况下,AWK打印所有匹配模式的行。
例子 (Example)
[jerry]$ awk '/a/ {print $0}' marks.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
在上面的例子中,我们正在搜索表单模式a 。 当模式匹配成功时,它从主体块执行命令。 在没有体块的情况下 - 采取默认操作来打印记录。 因此,以下命令产生相同的结果 -
例子 (Example)
[jerry]$ awk '/a/' marks.txt
按模式打印列
当模式匹配成功时,AWK默认打印整个记录。 但是你可以指示AWK只打印某些字段。 例如,以下示例在模式匹配成功时打印第三个和第四个字段。
例子 (Example)
[jerry]$ awk '/a/ {print $3 "\t" $4}' marks.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Maths 90
Biology 87
English 85
History 89
按任意顺序打印列
您可以按任何顺序打印列。 例如,以下示例打印第四列,后跟第三列。
例子 (Example)
[jerry]$ awk '/a/ {print $4 "\t" $3}' marks.txt
执行上面的代码时,您会得到以下结果 -
输出 (Output)
90 Maths
87 Biology
85 English
89 History
计数和打印匹配模式
让我们看一个示例,您可以在其中计算并打印模式匹配成功的行数。
例子 (Example)
[jerry]$ awk '/a/{++cnt} END {print "Count = ", cnt}' marks.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Count = 4
在此示例中,我们在模式匹配成功时递增计数器的值,并在END块中打印此值。 请注意,与其他编程语言不同,在使用变量之前无需声明变量。
打印超过18个字符的行
让我们只打印那些包含超过18个字符的行。
例子 (Example)
[jerry]$ awk 'length($0) > 18' marks.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
3) Shyam Biology 87
4) Kedar English 85
AWK提供了一个内置的length函数,它返回字符串的长度。 $0变量存储整行,并且在没有主体块的情况下,采取默认操作,即打印操作。 因此,如果一行超过18个字符,则比较结果为true,并打印该行。
AWK - Built-in Variables
AWK提供了几个内置变量。 在编写AWK脚本时,它们发挥着重要作用。 本章演示了内置变量的用法。
标准AWK变量
标准AWK变量将在下面讨论。
ARGC
它表示命令行提供的参数数量。
Example
[jerry]$ awk 'BEGIN {print "Arguments =", ARGC}' One Two Three Four
执行此代码时,您将获得以下结果 -
Output
Arguments = 5
但是为什么当你只传递4个参数时AWK会显示5? 只需查看以下示例即可清除您的疑问。
ARGV
它是一个存储命令行参数的数组。 数组的有效索引范围从0到ARGC-1。
Example
[jerry]$ awk 'BEGIN {
for (i = 0; i < ARGC - 1; ++i) {
printf "ARGV[%d] = %s\n", i, ARGV[i]
}
}' one two three four
执行此代码时,您将获得以下结果 -
Output
ARGV[0] = awk
ARGV[1] = one
ARGV[2] = two
ARGV[3] = three
CONVFMT
它代表数字的转换格式。 其默认值为%.6g 。
Example
[jerry]$ awk 'BEGIN { print "Conversion Format =", CONVFMT }'
执行此代码时,您将获得以下结果 -
Output
Conversion Format = %.6g
ENVIRON
它是环境变量的关联数组。
Example
[jerry]$ awk 'BEGIN { print ENVIRON["USER"] }'
执行此代码时,您将获得以下结果 -
Output
jerry
要查找其他环境变量的名称,请使用env命令。
FILENAME
它表示当前文件名。
Example
[jerry]$ awk 'END {print FILENAME}' marks.txt
执行此代码时,您将获得以下结果 -
Output
marks.txt
请注意,BEGIN块中未定义FILENAME。
FS
它表示(输入)字段分隔符,其默认值为空格。 您也可以使用-F命令行选项更改此设置。
Example
[jerry]$ awk 'BEGIN {print "FS = " FS}' | cat -vte
执行此代码时,您将获得以下结果 -
Output
FS = $
NF
它表示当前记录中的字段数。 例如,以下示例仅打印包含两个以上字段的行。
Example
[jerry]$ echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NF > 2'
执行此代码时,您将获得以下结果 -
Output
One Two Three
One Two Three Four
NR
它代表当前记录的编号。 例如,以下示例在当前记录号小于3时打印记录。
Example
[jerry]$ echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NR < 3'
执行此代码时,您将获得以下结果 -
Output
One Two
One Two Three
FNR
它类似于NR,但相对于当前文件。 当AWK在多个文件上运行时,它很有用。 FNR的值重置为新文件。
OFMT
它表示输出格式编号,其默认值为%.6g 。
Example
[jerry]$ awk 'BEGIN {print "OFMT = " OFMT}'
执行此代码时,您将获得以下结果 -
Output
OFMT = %.6g
OFS
它表示输出字段分隔符,其默认值为space。
Example
[jerry]$ awk 'BEGIN {print "OFS = " OFS}' | cat -vte
执行此代码时,您将获得以下结果 -
Output
OFS = $
ORS
它表示输出记录分隔符,其默认值为换行符。
Example
[jerry]$ awk 'BEGIN {print "ORS = " ORS}' | cat -vte
执行上面的代码时,您会得到以下结果 -
Output
ORS = $
$
RLENGTH
它表示match函数匹配的字符串的长度。 AWK的匹配函数在输入字符串中搜索给定的字符串。
Example
[jerry]$ awk 'BEGIN { if (match("One Two Three", "re")) { print RLENGTH } }'
执行此代码时,您将获得以下结果 -
Output
2
RS
它表示(输入)记录分隔符,其默认值为换行符。
Example
[jerry]$ awk 'BEGIN {print "RS = " RS}' | cat -vte
执行此代码时,您将获得以下结果 -
Output
RS = $
$
RSTART
它表示match函数匹配的字符串中的第一个位置。
Example
[jerry]$ awk 'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }'
执行此代码时,您将获得以下结果 -
Output
9
SUBSEP
它表示数组下标的分隔符,其默认值为\034 。
Example
[jerry]$ awk 'BEGIN { print "SUBSEP = " SUBSEP }' | cat -vte
执行此代码时,您将获得以下结果 -
Output
SUBSEP = ^\$
$0
它代表整个输入记录。
Example
[jerry]$ awk '{print $0}' marks.txt
执行此代码时,您将获得以下结果 -
Output
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
$n
它表示当前记录中第 n 个字段,其中字段由FS分隔。
Example
[jerry]$ awk '{print $3 "\t" $4}' marks.txt
执行此代码时,您将获得以下结果 -
Output
Physics 80
Maths 90
Biology 87
English 85
History 89
GNU AWK特定变量
GNU AWK具体变量如下 -
ARGIND
它表示正在处理的当前文件的ARGV中的索引。
Example
[jerry]$ awk '{
print "ARGIND = ", ARGIND; print "Filename = ", ARGV[ARGIND]
}' junk1 junk2 junk3
执行此代码时,您将获得以下结果 -
Output
ARGIND = 1
Filename = junk1
ARGIND = 2
Filename = junk2
ARGIND = 3
Filename = junk3
BINMODE
它用于为非POSIX系统上的所有文件I/O指定二进制模式。 数字值1,2或3分别指定输入文件,输出文件或所有文件应使用二进制I/O. r或w字符串值分别指定输入文件或输出文件应使用二进制I/O. rw或wr字符串值指定所有文件都应使用二进制I/O.
ERRNO
字符串表示当getline重定向失败或者close调用失败时出错。
Example
[jerry]$ awk 'BEGIN { ret = getline < "junk.txt"; if (ret == -1) print "Error:", ERRNO }'
执行此代码时,您将获得以下结果 -
Output
Error: No such file or directory
FIELDWIDTHS
设置了以空格分隔的字段宽度变量列表,GAWK将输入解析为固定宽度的字段,而不是使用FS变量的值作为字段分隔符。
IGNORECASE
设置此变量后,GAWK将不区分大小写。 以下示例演示了这一点 -
Example
[jerry]$ awk 'BEGIN{IGNORECASE = 1} /amit/' marks.txt
执行此代码时,您将获得以下结果 -
Output
1) Amit Physics 80
LINT
它提供了GAWK程序中--lint选项的动态控制。 设置此变量后,GAWK会打印lint警告。 当分配字符串值致命时,lint警告会成为致命错误,就像--lint=fatal 。
Example
[jerry]$ awk 'BEGIN {LINT = 1; a}'
执行此代码时,您将获得以下结果 -
Output
awk: cmd. line:1: warning: reference to uninitialized variable `a'
awk: cmd. line:1: warning: statement has no effect
PROCINFO
这是一个关联数组,包含有关进程的信息,例如实际和有效的UID号,进程ID号等。
Example
[jerry]$ awk 'BEGIN { print PROCINFO["pid"] }'
执行此代码时,您将获得以下结果 -
Output
4316
TEXTDOMAIN
它代表AWK程序的文本域。 它用于查找程序字符串的本地化翻译。
Example
[jerry]$ awk 'BEGIN { print TEXTDOMAIN }'
执行此代码时,您将获得以下结果 -
Output
messages
由于en_IN语言环境,上面的输出显示英文文本
AWK - Operators
与其他编程语言一样,AWK也提供了大量的运算符。 本章通过合适的示例解释AWK运算符。
| S.No. | 运算符和描述 |
|---|---|
| 1 | 算术运算符 AWK支持以下算术运算符。 |
| 2 | 增量和减量运算符 AWK支持以下递增和递减运算符。 |
| 3 | 分配运算符 AWK支持以下赋值运算符。 |
| 4 | 关系运算符 AWK支持以下关系运算符。 |
| 5 | 逻辑运算符 AWK支持以下逻辑运算符。 |
| 6 | 三元运算符 我们可以使用三元运算符轻松实现条件表达式。 |
| 7 | 一元运算符 AWK支持以下一元运算符。 |
| 8 | 指数运算符 指数运算符有两种格式。 |
| 9 | 字符串连接运算符 Space是一个字符串连接运算符,它合并两个字符串。 |
| 10 | 阵列成员运算符 它由in表示。 访问数组元素时使用它。 |
| 11 | 正则表达式运算符 此示例解释了两种形式的正则表达式运算符。 |
AWK - Regular Expressions
AWK在处理正则表达式方面非常强大和高效。 使用简单的正则表达式可以解决许多复杂的任务。 任何命令行专家都知道正则表达式的强大功能。
本章介绍了带有合适示例的标准正则表达式。
Dot
它匹配除行尾字符之外的任何单个字符。 例如,以下示例匹配fin, fun, fan等。
例子 (Example)
[jerry]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/'
执行上面的代码时,您会得到以下结果 -
输出 (Output)
fun
fin
fan
开始行
它匹配行的开头。 例如,以下示例打印以模式The开头的所有行。
例子 (Example)
[jerry]$ echo -e "This\nThat\nThere\nTheir\nthese" | awk '/^The/'
执行此代码时,您将获得以下结果 -
输出 (Output)
There
Their
行结束
它匹配行尾。 例如,以下示例打印以字母n结尾的行。
例子 (Example)
[jerry]$ echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
输出 (Output)
执行此代码时,您将获得以下结果 -
fun
fin
fan
匹配字符集
它仅用于匹配多个字符中的一个。 例如,以下示例匹配模式Call和Tall但不匹配Ball 。
例子 (Example)
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[CT]all/'
输出 (Output)
执行此代码时,您将获得以下结果 -
Call
Tall
独家套装
在专用集中,克拉否定了方括号中的字符集。 例如,以下示例仅打印Ball 。
例子 (Example)
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[^CT]all/'
执行此代码时,您将获得以下结果 -
输出 (Output)
Ball
改变(Alteration)
垂直条允许正则表达式进行逻辑OR运算。 例如,以下示例打印Ball和Call 。
例子 (Example)
[jerry]$ echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
执行此代码时,您将获得以下结果 -
输出 (Output)
Call
Ball
零或一次出现
它匹配前一个字符的零次或一次出现。 例如,以下示例匹配Colour和Color 。 我们使用?作为一个可选字符? 。
例子 (Example)
[jerry]$ echo -e "Colour\nColor" | awk '/Colou?r/'
执行此代码时,您将获得以下结果 -
输出 (Output)
Colour
Color
零次或多次出现
它匹配前一个字符的零次或多次出现。 例如,以下示例匹配ca, cat, catt,等。
例子 (Example)
[jerry]$ echo -e "ca\ncat\ncatt" | awk '/cat*/'
执行此代码时,您将获得以下结果 -
输出 (Output)
ca
cat
catt
一次或多次发生
它匹配前一个字符的一个或多个匹配项。 例如,下面的示例匹配2的一个或多个匹配项。
例子 (Example)
[jerry]$ echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
执行上面的代码时,您会得到以下结果 -
输出 (Output)
22
123
234
222
Grouping
Parentheses ()用于分组和字符| 用于替代品。 例如,以下正则表达式匹配包含Apple Juice or Apple Cake 。
例子 (Example)
[jerry]$ echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk
'/Apple (Juice|Cake)/'
执行此代码时,您将获得以下结果 -
输出 (Output)
Apple Juice
Apple Cake
AWK - Arrays
AWK有关联数组,关于它的最好的事情之一是 - 索引不需要是连续的数字集; 您可以使用字符串或数字作为数组索引。 此外,不需要事先声明数组的大小 - 数组可以在运行时扩展/收缩。
其语法如下 -
语法 (Syntax)
array_name[index] = value
其中array_name是数组的名称, index是数组索引, value是分配给数组元素的任何值。
创建数组
为了更深入地了解数组,让我们创建和访问数组的元素。
例子 (Example)
[jerry]$ awk 'BEGIN {
fruits["mango"] = "yellow";
fruits["orange"] = "orange"
print fruits["orange"] "\n" fruits["mango"]
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
orange
yellow
在上面的例子中,我们将数组声明为fruits其索引是fruit名称,值是fruit的颜色。 要访问数组元素,我们使用array_name[index]格式。
删除数组元素
对于插入,我们使用赋值运算符。 同样,我们可以使用delete语句从数组中删除一个元素。 delete语句的语法如下 -
语法 (Syntax)
delete array_name[index]
以下示例删除元素orange 。 因此该命令不显示任何输出。
例子 (Example)
[jerry]$ awk 'BEGIN {
fruits["mango"] = "yellow";
fruits["orange"] = "orange";
delete fruits["orange"];
print fruits["orange"]
}'
Multi-Dimensional arrays
AWK仅支持一维数组。 但您可以使用一维数组本身轻松模拟多维数组。
例如,下面给出的是一个3x3的三维阵列 -
100 200 300
400 500 600
700 800 900
在上面的例子中,array [0] [0]存储100,array [0] [1]存储200,依此类推。 要在数组位置[0] [0]存储100,我们可以使用以下语法 -
语法 (Syntax)
array["0,0"] = 100
虽然我们给0,0作为索引,但这些不是两个索引。 实际上,它只是一个字符串为0,0索引。
以下示例模拟二维数组 -
例子 (Example)
[jerry]$ awk 'BEGIN {
array["0,0"] = 100;
array["0,1"] = 200;
array["0,2"] = 300;
array["1,0"] = 400;
array["1,1"] = 500;
array["1,2"] = 600;
# print array elements
print "array[0,0] = " array["0,0"];
print "array[0,1] = " array["0,1"];
print "array[0,2] = " array["0,2"];
print "array[1,0] = " array["1,0"];
print "array[1,1] = " array["1,1"];
print "array[1,2] = " array["1,2"];
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
array[0,0] = 100
array[0,1] = 200
array[0,2] = 300
array[1,0] = 400
array[1,1] = 500
array[1,2] = 600
您还可以对数组执行各种操作,例如对元素/索引进行排序。 为此,您可以使用asorti和asorti函数
AWK - Control Flow
与其他编程语言一样,AWK提供条件语句来控制程序的流程。 本章通过适当的示例解释AWK的控制语句。
If 语句
它只是测试条件并根据条件执行某些操作。 下面给出if语句的语法 -
语法 (Syntax)
if (condition)
action
我们还可以使用下面给出的一对花括号来执行多个动作 -
语法 (Syntax)
if (condition) {
action-1
action-1
.
.
action-n
}
例如,以下示例检查数字是否均匀 -
例子 (Example)
[jerry]$ awk 'BEGIN {num = 10; if (num % 2 == 0) printf "%d is even number.\n", num }'
执行上面的代码时,您会得到以下结果 -
输出 (Output)
10 is even number.
If Else 语句
在if-else语法中,我们可以提供条件变为false时要执行的操作列表。
if-else语句的语法如下 -
语法 (Syntax)
if (condition)
action-1
else
action-2
在上面的语法中,当条件求值为true时执行action-1,当条件求值为false时执行action-2。 例如,以下示例检查数字是否均匀 -
例子 (Example)
[jerry]$ awk 'BEGIN {
num = 11; if (num % 2 == 0) printf "%d is even number.\n", num;
else printf "%d is odd number.\n", num
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
11 is odd number.
If-Else-If Ladder
我们可以使用多个if-else语句轻松创建if-else-if阶梯。 以下示例演示了这一点 -
例子 (Example)
[jerry]$ awk 'BEGIN {
a = 30;
if (a==10)
print "a = 10";
else if (a == 20)
print "a = 20";
else if (a == 30)
print "a = 30";
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
a = 30
AWK - Loops
本章通过合适的示例解释AWK的循环。 循环用于以重复方式执行一组动作。 只要循环条件为真,循环执行就会继续。
对于循环
for循环的语法是 -
语法 (Syntax)
for (initialization; condition; increment/decrement)
action
最初, for语句执行初始化操作,然后检查条件。 如果条件为真,则执行操作,然后执行递增或递减操作。 只要条件为真,循环执行就会继续。 例如,以下示例使用for循环打印1到5 -
例子 (Example)
[jerry]$ awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
执行此代码时,您将获得以下结果 -
输出 (Output)
1
2
3
4
5
而Loop
while循环继续执行操作,直到特定逻辑条件的计算结果为true。 这是while循环的语法 -
语法 (Syntax)
while (condition)
action
AWK首先检查条件; 如果条件为真,则执行操作。 只要循环条件的计算结果为true,就会重复此过程。 例如,以下示例使用while循环打印1到5 -
例子 (Example)
[jerry]$ awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }'
执行此代码时,您将获得以下结果 -
输出 (Output)
1
2
3
4
5
Do-While Loop
do-while循环类似于while循环,除了在循环结束时计算测试条件。 这是do-while循环的语法 -
语法 (Syntax)
do
action
while (condition)
在do-while循环中,即使条件语句的计算结果为false,action语句也至少执行一次。 例如,以下示例使用do-while循环打印1到5个数字 -
例子 (Example)
[jerry]$ awk 'BEGIN {i = 1; do { print i; ++i } while (i < 6) }'
执行此代码时,您将获得以下结果 -
输出 (Output)
1
2
3
4
5
Break 语句
顾名思义,它用于结束循环执行。 这是一个当和总和大于50时结束循环的例子。
例子 (Example)
[jerry]$ awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) break; else print "Sum =", sum
}
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
Sum = 0
Sum = 1
Sum = 3
Sum = 6
Sum = 10
Sum = 15
Sum = 21
Sum = 28
Sum = 36
Sum = 45
Continue 语句
continue语句在循环内部使用,以跳转到循环的下一次迭代。 当您希望跳过循环内部某些数据的处理时,它非常有用。 例如,以下示例使用continue语句打印1到20之间的偶数。
例子 (Example)
[jerry]$ awk 'BEGIN {
for (i = 1; i <= 20; ++i) {
if (i % 2 == 0) print i ; else continue
}
}'
执行此代码时,您将获得以下结果 -
输出 (Output)
2
4
6
8
10
12
14
16
18
20
Exit 语句
它用于停止脚本的执行。 它接受一个整数作为参数,它是AWK进程的退出状态代码。 如果未提供参数,则exit返回状态零。 这是一个在sum总和大于50时停止执行的示例。
例子 (Example)
[jerry]$ awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) exit(10); else print "Sum =", sum
}
}'
输出 (Output)
执行此代码时,您将获得以下结果 -
Sum = 0
Sum = 1
Sum = 3
Sum = 6
Sum = 10
Sum = 15
Sum = 21
Sum = 28
Sum = 36
Sum = 45
让我们检查一下脚本的返回状态。
例子 (Example)
[jerry]$ echo $?
执行此代码时,您将获得以下结果 -
输出 (Output)
10
AWK - 内置函数
AWK内置了许多功能,程序员始终可以使用它们。 本章通过合适的示例描述了算术,字符串,时间,位操作和其他各种功能。
| S.No. | 内置功能和说明 |
|---|---|
| 1 | 算术函数 AWK具有以下内置算术功能。 |
| 2 | 字符串函数 AWK具有以下内置String函数。 |
| 3 | 时间函数 AWK具有以下内置时间功能。 |
| 4 | 位操作函数 AWK具有以下内置位操作功能。 |
| 5 | Miscellaneous Functions AWK具有以下杂项功能。 |
AWK - User Defined Functions
函数是程序的基本构建块。 AWK允许我们定义自己的功能。 大型程序可以分为多个功能,每个功能可以独立编写/测试。 它提供了代码的可重用性。
以下是用户定义函数的一般格式 -
语法 (Syntax)
function function_name(argument1, argument2, ...) {
function body
}
在此语法中, function_name是用户定义函数的名称。 函数名称应以字母开头,其余字符可以是数字,字母字符或下划线的任意组合。 AWK的保留字不能用作函数名。
函数可以接受以逗号分隔的多个参数。 参数不是强制性的。 您也可以创建一个没有任何参数的用户定义函数。
function body由一个或多个AWK语句组成。
让我们编写两个函数来计算最小和最大数,并从另一个名为main函数中调用这些函数。 functions.awk文件包含 -
例子 (Example)
# Returns minimum number
function find_min(num1, num2){
if (num1 < num2)
return num1
return num2
}
# Returns maximum number
function find_max(num1, num2){
if (num1 > num2)
return num1
return num2
}
# Main function
function main(num1, num2){
# Find minimum number
result = find_min(10, 20)
print "Minimum =", result
# Find maximum number
result = find_max(10, 20)
print "Maximum =", result
}
# Script execution starts here
BEGIN {
main(10, 20)
}
执行此代码时,您将获得以下结果 -
输出 (Output)
Minimum = 10
Maximum = 20
AWK - Output Redirection
到目前为止,我们在标准输出流上显示了数据。 我们还可以将数据重定向到文件。 print或printf语句后出现重定向。 AWK中的重定向就像shell命令中的重定向一样,除了它们是在AWK程序中编写的。 本章通过合适的示例解释重定向。
重定向运算符
重定向运算符的语法是 -
语法 (Syntax)
print DATA > output-file
它将数据写入output-file 。 如果输出文件不存在,则创建一个。 使用此类重定向时,输出文件将在写入第一个输出之前被擦除。 对同一输出文件的后续写入操作不会擦除输出文件,而是附加到输出文件。 例如,以下示例写入Hello, World !!! 到文件。
让我们创建一个包含一些文本数据的文件。
例子 (Example)
[jerry]$ echo "Old data" > /tmp/message.txt
[jerry]$ cat /tmp/message.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Old data
现在让我们使用AWK的重定向运算符将一些内容重定向到它。
例子 (Example)
[jerry]$ awk 'BEGIN { print "Hello, World !!!" > "/tmp/message.txt" }'
[jerry]$ cat /tmp/message.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Hello, World !!!
附加运算符
append运算符的语法如下 -
语法 (Syntax)
print DATA >> output-file
它将数据附加到output-file 。 如果输出文件不存在,则创建一个。 使用此类重定向时,会在文件末尾附加新内容。 例如,以下示例附加Hello, World !!! 到文件。
让我们创建一个包含一些文本数据的文件。
例子 (Example)
[jerry]$ echo "Old data" > /tmp/message.txt
[jerry]$ cat /tmp/message.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Old data
现在让我们使用AWK的append运算符向它添加一些内容。
例子 (Example)
[jerry]$ awk 'BEGIN { print "Hello, World !!!" >> "/tmp/message.txt" }'
[jerry]$ cat /tmp/message.txt
执行此代码时,您将获得以下结果 -
输出 (Output)
Old data
Hello, World !!!
Pipe
可以通过管道而不是使用文件将输出发送到另一个程序。 此重定向打开管道命令,并通过此管道将项目的值写入另一个进程以执行该命令。 重定向参数命令实际上是AWK表达式。 这是管道的语法 -
语法 (Syntax)
print items | command
让我们使用tr命令将小写字母转换为大写。
例子 (Example)
[jerry]$ awk 'BEGIN { print "hello, world !!!" | "tr [a-z] [A-Z]" }'
执行此代码时,您将获得以下结果 -
输出 (Output)
HELLO, WORLD !!!
双向沟通
AWK可以使用|&进行与外部进程的通信,这是双向通信。 例如,以下示例使用tr命令将小写字母转换为大写。 我们的command.awk文件包含 -
例子 (Example)
BEGIN {
cmd = "tr [a-z] [A-Z]"
print "hello, world !!!" |& cmd
close(cmd, "to")
cmd |& getline out
print out;
close(cmd);
}
执行此代码时,您将获得以下结果 -
输出 (Output)
HELLO, WORLD !!!
脚本看起来神秘吗? 让我们揭开它的神秘面纱。
第一个语句cmd = "tr [az] [AZ]"是我们从AWK建立双向通信的命令。
下一个语句,即print命令提供tr命令的输入。 这里&| 表示双向通信。
第三个语句,即close(cmd, "to") ,在竞争执行后关闭to进程。
下一个语句cmd |& getline out借助getline函数将output存储到out变量中。
下一个print语句打印输出,最后close函数关闭命令。
AWK - Pretty Printing
到目前为止,我们已经使用AWK的print和printf函数在标准输出上显示数据。 但是printf比我们之前看到的要强大得多。 此函数借用C语言,在生成格式化输出时非常有用。 以下是printf语句的语法 -
语法 (Syntax)
printf fmt, expr-list
在上面的语法中, fmt是一串格式规范和常量。 expr-list是与格式说明符对应的参数列表。
转义序列 (Escape Sequences)
与任何字符串类似,格式可以包含嵌入的转义序列。 下面讨论的是AWK支持的转义序列 -
新队
以下示例使用换行符在单独的行中打印Hello和World -
Example
[jerry]$ awk 'BEGIN { printf "Hello\nWorld\n" }'
执行此代码时,您将获得以下结果 -
Output
Hello
World
水平标签
以下示例使用水平选项卡显示不同的字段 -
Example
[jerry]$ awk 'BEGIN { printf "Sr No\tName\tSub\tMarks\n" }'
执行上面的代码时,您会得到以下结果 -
Output
Sr No Name Sub Marks
垂直标签
以下示例在每个归档后使用垂直制表符 -
Example
[jerry]$ awk 'BEGIN { printf "Sr No\vName\vSub\vMarks\n" }'
执行此代码时,您将获得以下结果 -
Output
Sr No
Name
Sub
Marks
Backspace
以下示例在除最后一个字段之外的每个字段之后打印退格。 它会删除前三个字段中的最后一个数字。 例如, Field 1显示为Field ,因为最后一个字符用退格键擦除。 但是,最后一个字段Field 4按原样显示,因为我们在Field 4之后没有\b 。
Example
[jerry]$ awk 'BEGIN { printf "Field 1\bField 2\bField 3\bField 4\n" }'
执行此代码时,您将获得以下结果 -
Output
Field Field Field Field 4
回程
在以下示例中,在打印每个字段后,我们执行Carriage Return并在当前打印值的顶部打印下一个值。 这意味着,在最终输出中,您只能看到Field 4 ,因为它是在所有先前字段之上打印的最后一个。
Example
[jerry]$ awk 'BEGIN { printf "Field 1\rField 2\rField 3\rField 4\n" }'
执行此代码时,您将获得以下结果 -
Output
Field 4
换页
以下示例在打印每个字段后使用换页。
Example
[jerry]$ awk 'BEGIN { printf "Sr No\fName\fSub\fMarks\n" }'
执行此代码时,您将获得以下结果 -
Output
Sr No
Name
Sub
Marks
格式说明符
与在C语言中一样,AWK也有格式说明符。 printf语句的AWK版本接受以下转换规范格式 -
%c
它打印一个字符。 如果用于%c的参数是数字,则将其视为字符并打印。 否则,假定参数是一个字符串,并且打印该字符串的唯一第一个字符。
Example
[jerry]$ awk 'BEGIN { printf "ASCII value 65 = character %c\n", 65 }'
Output
执行此代码时,您将获得以下结果 -
ASCII value 65 = character A
%d和%i
它只打印十进制数的整数部分。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %d\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 80
%e和%E
它打印形式为[ - ] d.dddddde [+ - ] dd的浮点数。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %E\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 8.066000e+01
%E格式使用E而不是e。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %e\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 8.066000E+01
%f
它打印形式为[ - ] ddd.dddddd的浮点数。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %f\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 80.660000
%g和%G
使用%e或%f转换,以较短者为准,抑制非重要零。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %g\n", 80.66 }'
Output
执行此代码时,您将获得以下结果 -
Percentags = 80.66
%G格式使用%E而不是%e。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %G\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 80.66
%o
它打印一个无符号的八进制数。
Example
[jerry]$ awk 'BEGIN { printf "Octal representation of decimal number 10 = %o\n", 10}'
执行此代码时,您将获得以下结果 -
Output
Octal representation of decimal number 10 = 12
%u
它打印无符号十进制数。
Example
[jerry]$ awk 'BEGIN { printf "Unsigned 10 = %u\n", 10 }'
执行此代码时,您将获得以下结果 -
Output
Unsigned 10 = 10
%s
它打印一个字符串。
Example
[jerry]$ awk 'BEGIN { printf "Name = %s\n", "Sherlock Holmes" }'
执行此代码时,您将获得以下结果 -
Output
Name = Sherlock Holmes
%x和%X
它打印一个无符号的十六进制数。 %X格式使用大写字母而不是小写。
Example
[jerry]$ awk 'BEGIN {
printf "Hexadecimal representation of decimal number 15 = %x\n", 15
}'
执行此代码时,您将获得以下结果 -
Output
Hexadecimal representation of decimal number 15 = f
现在让我们使用%X并观察结果 -
Example
[jerry]$ awk 'BEGIN {
printf "Hexadecimal representation of decimal number 15 = %X\n", 15
}'
执行此代码时,您将获得以下结果 -
Output
Hexadecimal representation of decimal number 15 = F
%%
它打印一个%字符,不转换任何参数。
Example
[jerry]$ awk 'BEGIN { printf "Percentags = %d%%\n", 80.66 }'
执行此代码时,您将获得以下结果 -
Output
Percentags = 80%
带%的可选参数
使用%我们可以使用以下可选参数 -
Width
该字段填充到width 。 默认情况下,字段用空格填充,但是当使用0标志时,它用零填充。
Example
[jerry]$ awk 'BEGIN {
num1 = 10; num2 = 20; printf "Num1 = %10d\nNum2 = %10d\n", num1, num2
}'
执行此代码时,您将获得以下结果 -
Output
Num1 = 10
Num2 = 20
领先的零
前导零作为标志,表示输出应填充零而不是空格。 请注意,当该字段宽于要打印的值时,此标志仅起作用。 以下示例描述了这一点 -
Example
[jerry]$ awk 'BEGIN {
num1 = -10; num2 = 20; printf "Num1 = %05d\nNum2 = %05d\n", num1, num2
}'
执行此代码时,您将获得以下结果 -
Output
Num1 = -0010
Num2 = 00020
左对齐
表达式应在其字段内左对齐。 当输入字符串小于指定的字符数,并且您希望它左对齐时,即通过向右添加空格,在%之后和数字之前立即使用减号( - )。
在以下示例中,AWK命令的输出通过管道传递给cat命令以显示END OF LINE($)字符。
Example
[jerry]$ awk 'BEGIN { num = 10; printf "Num = %-5d\n", num }' | cat -vte
执行此代码时,您将获得以下结果 -
Output
Num = 10 $
前缀符号
它总是在数字值前加一个符号,即使该值为正数。
Example
[jerry]$ awk 'BEGIN {
num1 = -10; num2 = 20; printf "Num1 = %+d\nNum2 = %+d\n", num1, num2
}'
执行此代码时,您将获得以下结果 -
Output
Num1 = -10
Num2 = +20
Hash
对于%o,它提供前导零。 对于%x和%X,仅当结果为非零时,它才分别提供前导0x或0X。 对于%e,%E,%f和%F,结果始终包含小数点。 对于%g和%G,不会从结果中删除尾随零。 以下示例描述了这一点 -
Example
[jerry]$ awk 'BEGIN {
printf "Octal representation = %#o\nHexadecimal representaion = %#X\n", 10, 10
}'
执行此代码时,您将获得以下结果 -
Output
Octal representation = 012
Hexadecimal representation = 0XA
