汇编 - 快速指南
Assembly - Introduction
什么是汇编语言?
每台个人计算机都有一个微处理器,用于管理计算机的算术,逻辑和控制活动。
每个处理器系列都有自己的一套指令,用于处理各种操作,例如从键盘输入,在屏幕上显示信息以及执行各种其他工作。 这些指令集称为“机器语言指令”。
处理器只能理解机器语言指令,它们是1和0的字符串。 但是,在软件开发中使用机器语言过于模糊和复杂。 因此,低级汇编语言是针对特定的处理器系列而设计的,这些处理器代表符号代码中的各种指令和更易理解的形式。
汇编语言的优点
了解汇编语言让人意识到 -
- 程序如何与OS,处理器和BIOS连接;
- 如何在内存和其他外部设备中表示数据;
- 处理器如何访问和执行指令;
- 指令如何访问和处理数据;
- 程序如何访问外部设备。
使用汇编语言的其他优点是 -
它需要更少的内存和执行时间;
它以更简单的方式允许特定于硬件的复杂作业;
它适用于对时间要求严格的工作;
它最适合编写中断服务程序和其他内存驻留程序。
PC硬件的基本功能
PC的主要内部硬件包括处理器,存储器和寄存器。 寄存器是保存数据和地址的处理器组件。 要执行程序,系统会将其从外部设备复制到内部存储器中。 处理器执行程序指令。
计算机存储的基本单位有点; 它可以是ON(1)或OFF(0)。 一组九个相关位产生一个字节,其中8位用于数据,最后一位用于奇偶校验。 根据奇偶校验规则,每个字节中ON(1)的位数应始终为奇数。
因此,奇偶校验位用于使字节中的位数奇数。 如果奇偶校验是偶数,则系统假定存在奇偶校验错误(尽管很少),这可能是由于硬件故障或电气干扰引起的。
处理器支持以下数据大小 -
- 字:一个2字节的数据项
- 双字:4字节(32位)数据项
- 四字:8字节(64位)数据项
- 段落:16字节(128位)区域
- Kilobyte:1024字节
- 兆字节:1,048,576字节
二进制数字系统 (Binary Number System)
每个数字系统使用位置表示法,即,写入数字的每个位置具有不同的位置值。 每个位置是基数的幂,对于二进制数系统是2,并且这些幂从0开始并且增加1。
下表显示了8位二进制数的位置值,其中所有位都设置为ON。
| 比特值 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| 位置值作为基数2的幂 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| 位号 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
二进制数的值基于1位的存在及其位置值。 所以,给定二进制数的值是 -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
与2 8 - 1相同。
十六进制记数系统 (Hexadecimal Number System)
十六进制数系统使用基数16.此系统中的数字范围为0到15.按照惯例,字母A到F用于表示与十进制值10到15对应的十六进制数字。
计算中的十六进制数用于缩写冗长的二进制表示。 基本上,十六进制数系统通过将每个字节分成两半并表示每个半字节的值来表示二进制数据。 下表提供了十进制,二进制和十六进制等效项 -
| 十进制数 | 二进制表示 | 十六进制表示 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | A |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
要将二进制数转换为十六进制等效值,请从右侧开始将其分为4个连续组的组,并将这些组写在十六进制数的相应数字上。
Example - 二进制数1000 1100 1101 0001相当于十六进制 - 8CD1
要将十六进制数转换为二进制数,只需将每个十六进制数写入其4位二进制数。
Example - 十六进制数FAD8等效于二进制 - 1111 1010 1101 1000
二进制算术
下表说明了二元加法的四个简单规则 -
| (一世) | (ⅱ) | (ⅲ) | (ⅳ) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| =0 | =1 | =10 | =11 |
规则(iii)和(iv)显示1位进位到下一个左位置。
Example
| 十进制 | 二进制 |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
负二进制值以二进制two's complement notation 。 根据此规则,将二进制数转换为其负值是reverse its bit values and add 1 。
Example
| 53号 | 00110101 |
| 反转位 | 11001010 |
| Add 1 | 0000000 1 |
| Number -53 | 11001011 |
要从另一个值中减去一个值, convert the number being subtracted to two's complement format and add the numbers要减去convert the number being subtracted to two's complement format and add the numbers 。
Example
从53减去42
| 53号 | 00110101 |
| Number 42 | 00101010 |
| 反转42位 | 11010101 |
| Add 1 | 0000000 1 |
| Number -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
最后1位的溢出丢失。
寻址内存中的数据
处理器控制指令执行的过程称为fetch-decode-execute cycle或execution cycle 。 它由三个连续步骤组成 -
- 从内存中获取指令
- 解码或识别指令
- 执行指令
处理器可以一次访问一个或多个字节的存储器。 我们考虑一个十六进制数0725H。 这个数字需要两个字节的内存。 高位字节或最高有效字节为07,低位字节为25。
处理器以反向字节序列存储数据,即低位字节存储在低存储器地址中,高位字节存储在高存储器地址中。 因此,如果处理器将值0725H从寄存器带到存储器,它将首先将25传输到较低的存储器地址,将07传输到下一个存储器地址。
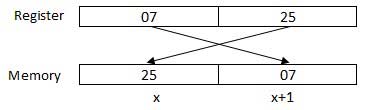
x:内存地址
当处理器从存储器中获取数字数据以进行寄存时,它再次反转字节。 有两种内存地址 -
绝对地址 - 特定位置的直接参考。
段地址(或偏移量) - 具有偏移值的存储器段的起始地址。
Assembly - Environment Setup
本地环境设置 (Local Environment Setup)
汇编语言取决于指令集和处理器的体系结构。 在本教程中,我们将重点介绍Pentium等Intel-32处理器。 要学习本教程,您需要 -
- IBM PC或任何等效的兼容计算机
- Linux操作系统的副本
- NASM汇编程序的副本
有许多好的汇编程序,例如 -
- Microsoft Assembler(MASM)
- Borland Turbo Assembler(TASM)
- GNU汇编程序(GAS)
我们将使用NASM汇编程序,因为它是 -
- 自由。 您可以从各种Web源下载它。
- 记录良好,您将获得有关网络的大量信息。
- 可以在Linux和Windows上使用。
安装NASM
如果在安装Linux时选择“开发工具”,则可能会随Linux操作系统一起安装NASM,而无需单独下载和安装。 要检查是否已安装NASM,请执行以下步骤 -
打开Linux终端。
键入whereis nasm并按ENTER键。
如果已经安装,则会出现类似nasm: /usr/bin/nasm 。 否则,您将看到只是nasm: ,那么您需要安装NASM。
要安装NASM,请执行以下步骤 -
查看The netwide assembler (NASM)网站以获取最新版本。
下载Linux源存档nasm-X.XX.ta.gz ,其中X.XX是存档中的NASM版本号。
将存档解压缩到创建子目录nasm-X. XX的目录中nasm-X. XX nasm-X. XX 。
cd到nasm-X.XX并输入./configure 。 这个shell脚本将找到最好的C编译器来使用并相应地设置Makefile。
键入make以构建nasm和ndisasm二进制文件。
输入make install以在/ usr/local/bin中安装nasm和ndisasm并安装手册页。
这应该在您的系统上安装NASM。 或者,您可以为Fedora Linux使用RPM分发。 此版本更易于安装,只需双击RPM文件即可。
Assembly - Basic Syntax
装配程序可分为三个部分 -
data部分,
bss部分,和
text部分。
data部分
data部分用于声明初始化数据或常量。 此数据在运行时不会更改。 您可以在本节中声明各种常量值,文件名或缓冲区大小等。
声明数据部分的语法是 -
section.data
bss部分
bss部分用于声明变量。 声明bss部分的语法是 -
section.bss
text部分
text部分用于保存实际代码。 本节必须以声明global _start开头,它告诉内核程序执行的开始位置。
声明文本部分的语法是 -
section.text
global _start
_start:
注释 (Comments)
汇编语言注释以分号(;)开头。 它可能包含任何可打印的字符,包括空白。 它可以单独出现在一条线上,如 -
; This program displays a message on screen
或者,在同一条线上连同指令,如 -
add eax, ebx ; adds ebx to eax
汇编语言陈述
汇编语言程序包含三种语句 -
- 可执行的指令或说明,
- 汇编程序指令或伪操作,以及
- Macros.
executable instructions或简单instructions告诉处理器该做什么。 每条指令都包含一个operation code (操作码)。 每个可执行指令生成一个机器语言指令。
assembler directives或pseudo-ops告诉汇编程序有关汇编过程的各个方面。 这些是不可执行的,不会生成机器语言指令。
Macros基本上是文本替换机制。
汇编语言语句的语法
汇编语言语句每行输入一个语句。 每个声明都遵循以下格式 -
[label] mnemonic [operands] [;comment]
方括号中的字段是可选的。 基本指令有两部分,第一部分是要执行的指令(或助记符)的名称,第二部分是操作数或命令的参数。
以下是典型汇编语言陈述的一些示例 -
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL register
大会中的Hello World计划
以下汇编语言代码在屏幕上显示字符串'Hello World' -
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the string
编译并执行上述代码时,会产生以下结果 -
Hello, world!
编译和链接NASM中的汇编程序
确保在PATH环境变量中设置了nasm和ld二进制文件的路径。 现在,采取以下步骤来编译和链接上述程序 -
使用文本编辑器键入上面的代码并将其另存为hello.asm。
确保您与保存hello.asm目录位于同一目录中。
要组装程序,请键入nasm -f elf hello.asm
如果有任何错误,将在此阶段提示您。 否则,将创建名为hello.o的程序的目标文件。
要链接目标文件并创建名为hello的可执行文件,请键入ld -m elf_i386 -s -o hello hello.o
键入./hello执行该程序
如果你已经完成了所有事情,它将显示“Hello,World!” 屏幕上。
Assembly - Memory Segments
我们已经讨论过汇编程序的三个部分。 这些部分也代表各种存储器段。
有趣的是,如果将section关键字替换为segment,您将得到相同的结果。 请尝试以下代码 -
segment .text ;code segment
global_start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string
编译并执行上述代码时,会产生以下结果 -
Hello, world!
记忆段
分段存储器模型将系统存储器划分为由位于段寄存器中的指针引用的独立段组。 每个段用于包含特定类型的数据。 一个段用于包含指令代码,另一个段用于存储数据元素,第三个段用于保存程序堆栈。
根据上述讨论,我们可以指定各种内存段 -
Data segment - 由.data部分和.bss 。 .data部分用于声明内存区域,其中为程序存储数据元素。 声明数据元素后,此部分无法展开,并且在整个程序中保持静态。
.bss部分也是一个静态内存部分,它包含稍后在程序中声明的数据的缓冲区。 该缓冲存储器为零填充。
Code segment - 由.text部分表示。 这定义了存储器中存储指令代码的区域。 这也是一个固定的区域。
Stack - 此段包含传递给程序中的函数和过程的数据值。
Assembly - Registers
处理器操作主要涉及处理数据。 该数据可以存储在存储器中并从其上访问。 然而,从存储器读取数据和将数据存储到存储器中会降低处理器的速度,因为它涉及通过控制总线向存储器存储单元发送数据请求并通过相同通道获取数据的复杂过程。
为了加速处理器操作,处理器包括一些内部存储器存储位置,称为registers 。
寄存器存储数据元素以便处理而无需访问存储器。 处理器芯片内置有限数量的寄存器。
处理器寄存器
IA-32架构中有10个32位和6个16位处理器寄存器。 寄存器分为三类 -
- General registers,
- 控制寄存器,和
- 段寄存器。
一般登记册进一步分为以下几组 -
- 数据寄存器,
- 指针寄存器,和
- 索引寄存器。
数据寄存器
四个32位数据寄存器用于算术,逻辑和其他操作。 这些32位寄存器可以三种方式使用 -
作为完整的32位数据寄存器:EAX,EBX,ECX,EDX。
32位寄存器的下半部分可用作4个16位数据寄存器:AX,BX,CX和DX。
上述四个16位寄存器的低半部分和高半部分可用作8个8位数据寄存器:AH,AL,BH,BL,CH,CL,DH和DL。
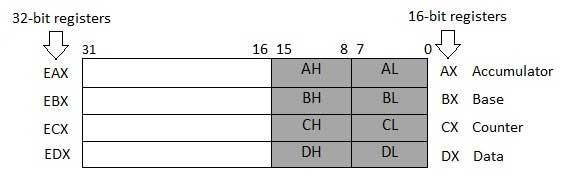
其中一些数据寄存器在算术运算中具有特定用途。
AX is the primary accumulator ; 它用于输入/输出和大多数算术指令。 例如,在乘法运算中,根据操作数的大小,一个操作数存储在EAX或AX或AL寄存器中。
BX is known as the base register ,因为它可以用于索引寻址。
CX is known as the count register ,因为ECX,CX寄存器在迭代操作中存储循环计数。
DX is known as the data register 。 它也用于输入/输出操作。 它还与AX寄存器以及DX一起用于涉及大值的乘法和除法运算。
指针寄存器
指针寄存器是32位EIP,ESP和EBP寄存器以及相应的16位右部分IP,SP和BP。 指针寄存器分为三类 -
Instruction Pointer (IP) - 16位IP寄存器存储下一条要执行的指令的偏移地址。 与CS寄存器相关联的IP(作为CS:IP)给出代码段中当前指令的完整地址。
Stack Pointer (SP) - 16位SP寄存器提供程序堆栈中的偏移值。 与SS寄存器(SS:SP)相关联的SP指的是程序堆栈内的数据或地址的当前位置。
Base Pointer (BP) - 16位BP寄存器主要用于引用传递给子程序的参数变量。 SS寄存器中的地址与BP中的偏移量组合以获得参数的位置。 BP也可以与DI和SI组合作为特殊寻址的基址寄存器。
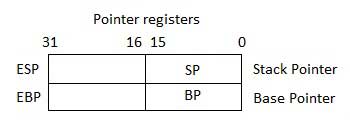
索引寄存器
32位索引寄存器,ESI和EDI,以及它们最右边的16位部分。 SI和DI用于索引寻址,有时用于加法和减法。 有两组索引指针 -
Source Index (SI) - 用作字符串操作的源索引。
Destination Index (DI) - 用作字符串操作的目标索引。

控制寄存器
32位指令指针寄存器和32位标志寄存器组合被认为是控制寄存器。
许多指令涉及比较和数学计算,并且更改标志的状态,并且一些其他条件指令测试这些状态标志的值以将控制流程带到其他位置。
公共标志位是:
Overflow Flag (OF) - 表示在带符号算术运算后数据的高位(最左位)溢出。
Direction Flag (DF) - 它确定移动或比较字符串数据的左或右方向。 当DF值为0时,字符串操作采用从左到右的方向,当值设置为1时,字符串操作采用从右到左的方向。
Interrupt Flag (IF) - 它确定是否要忽略或处理键盘输入等外部中断。 它在值为0时禁用外部中断,在设置为1时启用中断。
Trap Flag (TF) - 它允许以单步模式设置处理器的操作。 我们使用的DEBUG程序设置了陷阱标志,因此我们可以一次执行一条指令。
Sign Flag (SF) - 它显示算术运算结果的符号。 根据算术运算后的数据项的符号设置该标志。 符号由最左边的位的高位表示。 正结果将SF的值清除为0,否定结果将其设置为1。
Zero Flag (ZF) - 它表示算术或比较运算的结果。 非零结果将零标志清除为0,零结果将其设置为1。
Auxiliary Carry Flag (AF) - 它包含算术运算后从第3位到第4位的进位; 用于专业算术。 当1字节算术运算导致从第3位进位到第4位时,AF置位。
Parity Flag (PF) - 它表示从算术运算获得的结果中的1位总数。 偶数个1位将奇偶校验标志清除为0,奇数个1位将奇偶校验标志设置为1。
Carry Flag (CF) - 在算术运算后,它包含来自高位(最左边)的0或1的进位。 它还存储shift或rotate操作的最后一位的内容。
下表显示了16位Flags寄存器中标志位的位置:
| 旗: | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 位号: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
细分寄存器
段是在程序中定义的用于包含数据,代码和堆栈的特定区域。 主要有三个部分 -
Code Segment - 它包含要执行的所有指令。 16位代码段寄存器或CS寄存器存储代码段的起始地址。
Data Segment - 它包含数据,常量和工作区域。 16位数据段寄存器或DS寄存器存储数据段的起始地址。
Stack Segment - 它包含过程或子例程的数据和返回地址。 它被实现为“堆栈”数据结构。 堆栈段寄存器或SS寄存器存储堆栈的起始地址。
除DS,CS和SS寄存器外,还有其他额外的段寄存器 - ES(额外段),FS和GS,它们提供用于存储数据的附加段。
在汇编编程中,程序需要访问存储器位置。 段内的所有存储器位置都相对于段的起始地址。 段开始于可被16或十六进制10整除的地址。因此,所有这些存储器地址中最右边的十六进制数字是0,通常不存储在段寄存器中。
段寄存器存储段的起始地址。 要获得段内数据或指令的确切位置,需要偏移值(或位移)。 为了引用段中的任何存储器位置,处理器将段寄存器中的段地址与位置的偏移值组合。
例子 (Example)
查看以下简单程序,了解汇编编程中寄存器的使用。 该程序在屏幕上显示9颗星以及一条简单的信息 -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'
编译并执行上述代码时,会产生以下结果 -
Displaying 9 stars
*********
Assembly - System Calls
系统调用是用于用户空间和内核空间之间接口的API。 我们已经使用过系统调用。 sys_write和sys_exit,分别用于写入屏幕并退出程序。
Linux系统调用
您可以在汇编程序中使用Linux系统调用。 您需要采取以下步骤在程序中使用Linux系统调用 -
- 将系统调用号放在EAX寄存器中。
- 将参数存储在寄存器EBX,ECX等中的系统调用中。
- 调用相关的中断(80h)。
- 结果通常在EAX寄存器中返回。
有六个寄存器存储所使用的系统调用的参数。 这些是EBX,ECX,EDX,ESI,EDI和EBP。 这些寄存器采用连续参数,从EBX寄存器开始。 如果有超过六个参数,则第一个参数的存储单元存储在EBX寄存器中。
以下代码片段显示了系统调用sys_exit的用法 -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernel
以下代码片段显示了使用系统调用sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernel
所有系统调用都列在/usr/include/asm/unistd.h ,以及它们的编号(在调用int 80h之前放入EAX的值)。
下表显示了本教程中使用的一些系统调用 -
| EAX% | 名称 | EBX% | %ECX | %EDX | ESX% | EDI% |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | unsigned int | char * | size_t | - | - |
| 4 | sys_write | unsigned int | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | unsigned int | - | - | - | - |
例子 (Example)
以下示例从键盘读取数字并将其显示在屏幕上 -
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80h
编译并执行上述代码时,会产生以下结果 -
Please enter a number:
1234
You have entered:1234
Assembly - Addressing Modes
大多数汇编语言指令都需要处理操作数。 操作数地址提供存储要处理的数据的位置。 某些指令不需要操作数,而某些其他指令可能需要一个,两个或三个操作数。
当指令需要两个操作数时,第一个操作数通常是目标,它包含寄存器或存储单元中的数据,第二个操作数是源。 源包含要传递的数据(立即寻址)或数据的地址(寄存器或存储器)。 通常,源数据在操作后保持不变。
三种基本寻址方式是 -
- 寄存器寻址
- 立即寻址
- 内存寻址
注册寻址
在此寻址模式中,寄存器包含操作数。 根据指令,寄存器可以是第一个操作数,第二个操作数或两者。
例如,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registers
由于寄存器之间的处理数据不涉及存储器,因此它提供了最快的数据处理。
立即寻址
立即数操作数具有常量值或表达式。 当具有两个操作数的指令使用立即寻址时,第一个操作数可以是寄存器或存储器位置,第二个操作数是立即数。 第一个操作数定义数据的长度。
例如,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AX
直接内存寻址
在存储器寻址模式中指定操作数时,需要直接访问主存储器,通常是数据段。 这种寻址方式导致数据处理速度变慢。 要在存储器中找到数据的确切位置,我们需要段起始地址,该地址通常位于DS寄存器中,并且具有偏移值。 该偏移值也称为effective address 。
在直接寻址模式中,偏移值直接指定为指令的一部分,通常由变量名称表示。 汇编程序计算偏移值并维护一个符号表,该表存储程序中使用的所有变量的偏移值。
在直接存储器寻址中,其中一个操作数指的是存储器位置而另一个操作数指的是寄存器。
例如,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to register
Direct-Offset Addressing
该寻址模式使用算术运算符来修改地址。 例如,查看定义数据表的以下定义 -
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of words
以下操作将数据从内存中的表访问到寄存器中 -
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLE
间接内存寻址
该寻址模式利用计算机的Segment:Offset寻址能力。 通常,基址寄存器EBX,EBP(或BX,BP)和用于存储器引用的方括号内编码的索引寄存器(DI,SI)用于此目的。
间接寻址通常用于包含多个元素(如数组)的变量。 数组的起始地址存储在EBX寄存器中。
以下代码段显示了如何访问变量的不同元素。
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123
MOV指令
我们已经使用MOV指令将数据从一个存储空间移动到另一个存储空间。 MOV指令需要两个操作数。
语法 (Syntax)
MOV指令的语法是 -
MOV destination, source
MOV指令可能具有以下五种形式之一 -
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, register
请注意 -
- MOV操作中的两个操作数应该是相同的大小
- 源操作数的值保持不变
MOV指令有时会引起歧义。 例如,看一下这些陈述 -
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
目前尚不清楚是否要移动数字等效的字节或等效数字110.在这种情况下,使用type specifier是明智的。
下表显示了一些常见的类型说明符 -
| 类型说明符 | 字节已解决 |
|---|---|
| BYTE | 1 |
| WORD | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
例子 (Example)
以下程序说明了上面讨论的一些概念。 它在内存的数据部分中存储名称“Zara Ali”,然后以编程方式将其值更改为另一个名称“Nuha Ali”并显示这两个名称。
section .text
global_start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali '
编译并执行上述代码时,会产生以下结果 -
Zara Ali Nuha Ali
Assembly - Variables
NASM提供了各种define directives用于为变量保留存储空间。 define assembler指令用于分配存储空间。 它可用于保留以及初始化一个或多个字节。
为初始化数据分配存储空间
初始化数据的存储分配语句的语法是 -
[variable-name] define-directive initial-value [,initial-value]...
其中, variable-name是每个存储空间的标识符。 汇编程序为数据段中定义的每个变量名称关联一个偏移值。
define指令有五种基本形式 -
| 指示 | 目的 | 储存空间 |
|---|---|---|
| DB | 定义字节 | 分配1个字节 |
| DW | 定义Word | 分配2个字节 |
| DD | 定义双字 | 分配4个字节 |
| DQ | 定义四字 | 分配8个字节 |
| DT | 定义十个字节 | 分配10个字节 |
以下是使用define指令的一些示例 -
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456
请注意 -
字符的每个字节都以十六进制的ASCII值存储。
每个十进制值自动转换为16位二进制等效值并存储为十六进制数。
处理器使用little-endian字节排序。
负数转换为2的补码表示。
短和长浮点数分别使用32或64位表示。
以下程序显示了使用define指令 -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'
编译并执行上述代码时,会产生以下结果 -
y
为未初始化数据分配存储空间
保留指令用于为未初始化数据保留空间。 保留指令采用单个操作数,指定要保留的空间单元数。 每个define指令都有一个相关的保留指令。
保留指令有五种基本形式 -
| 指示 | 目的 |
|---|---|
| RESB | 预留一个字节 |
| RESW | Reserve a Word |
| RESD | Reserve a Doubleword |
| RESQ | Reserve a Quadword |
| REST | 预留十个字节 |
多个定义
您可以在程序中拥有多个数据定义语句。 例如 -
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15H
汇编程序为多个变量定义分配连续内存。
多次初始化
TIMES指令允许多次初始化为相同的值。 例如,可以使用以下语句定义名为9的标记数组并将其初始化为零 -
marks TIMES 9 DW 0
TIMES指令在定义数组和表时很有用。 以下程序在屏幕上显示9个星号 -
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'
编译并执行上述代码时,会产生以下结果 -
*********
Assembly - Constants
NASM提供了几个定义常量的指令。 我们在前面的章节中已经使用了EQU指令。 我们将特别讨论三项指令 -
- EQU
- %assign
- %define
EQU指令
EQU指令用于定义常量。 EQU指令的语法如下 -
CONSTANT_NAME EQU expression
例如,
TOTAL_STUDENTS equ 50
然后,您可以在代码中使用此常量值,例如 -
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTS
EQU语句的操作数可以是表达式 -
LENGTH equ 20
WIDTH equ 10
AREA equ length * width
上面的代码段将AREA定义为200。
例子 (Example)
以下示例说明了EQU指令的使用 -
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3
编译并执行上述代码时,会产生以下结果 -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!
%assign指令
%assign指令可用于定义EQU指令等数字常量。 该指令允许重新定义。 例如,您可以将常量TOTAL定义为 -
%assign TOTAL 10
稍后在代码中,您可以将其重新定义为 -
%assign TOTAL 20
该指令区分大小写。
%定义指令
%define指令允许定义数字和字符串常量。 该指令类似于C中的#define。例如,您可以将常量PTR定义为 -
%define PTR [EBP+4]
上面的代码用[EBP + 4]替换PTR 。
该指令还允许重新定义,并且区分大小写。
Assembly - Arithmetic Instructions
INC指令
INC指令用于将操作数递增1。 它适用于单个操作数,可以在寄存器或内存中。
语法 (Syntax)
INC指令具有以下语法 -
INC destination
操作数destination可以是8位,16位或32位操作数。
例子 (Example)
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variable
DEC指令
DEC指令用于将操作数递减1。 它适用于单个操作数,可以在寄存器或内存中。
语法 (Syntax)
DEC指令具有以下语法 -
DEC destination
操作数destination可以是8位,16位或32位操作数。
例子 (Example)
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]
ADD和SUB指令
ADD和SUB指令用于以字节,字和双字大小执行二进制数据的简单加/减,即分别用于加或减8位,16位或32位操作数。
语法 (Syntax)
ADD和SUB指令具有以下语法 -
ADD/SUB destination, source
ADD/SUB指令可以在 - 之间发生 -
- 注册注册
- 记忆要注册
- 注册到内存
- 注册恒定数据
- 内存到恒定数据
但是,与其他指令一样,使用ADD/SUB指令无法进行内存到内存操作。 ADD或SUB操作设置或清除溢出和进位标志。
例子 (Example)
以下示例将询问用户的两位数字,分别将数字存储在EAX和EBX寄存器中,添加值,将结果存储在内存位置“ res ”中,最后显示结果。
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1
msg2 db "Please enter a second digit", 0xA,0xD
len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80
编译并执行上述代码时,会产生以下结果 -
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7
The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1
编译并执行上述代码时,会产生以下结果 -
The sum is:
7
MUL/IMUL指令
有两个用于乘以二进制数据的指令。 MUL(Multiply)指令处理无符号数据,IMUL(整数乘)处理带符号数据。 这两条指令都会影响进位和溢出标志。
语法 (Syntax)
MUL/IMUL指令的语法如下 -
MUL/IMUL multiplier
两种情况下的复数将位于累加器中,具体取决于被乘数和乘数的大小,并且生成的乘积也根据操作数的大小存储在两个寄存器中。 以下部分介绍了具有三种不同情况的MUL指令 -
| Sr.No. | 方案 |
|---|---|
| 1 | When two bytes are multiplied − 被乘数位于AL寄存器中,乘数是存储器或另一个寄存器中的一个字节。 该产品在AX。 产品的高阶8位存储在AH中,低阶8位存储在AL中。
|
| 2 | When two one-word values are multiplied − 被乘数应位于AX寄存器中,乘数是存储器中的字或另一个寄存器。 例如,对于像MUL DX这样的指令,必须将乘数存储在DX中,将被乘数存储在AX中。 最终产品是双字,需要两个寄存器。 高阶(最左边)部分存储在DX中,低阶(最右边)部分存储在AX中。
|
| 3 | When two doubleword values are multiplied − 当两个双字值相乘时,被乘数应为EAX,乘数为存储在存储器或另一个寄存器中的双字值。 生成的产品存储在EDX:EAX寄存器中,即高位32位存储在EDX寄存器中,低位32位存储在EAX寄存器中。
|



例子 (Example)
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DL
例子 (Example)
以下示例将3与2相乘,并显示结果 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1
编译并执行上述代码时,会产生以下结果 -
The result is:
6
DIV/IDIV指令
除法运算生成两个元素 - quotient和remainder 。 在乘法的情况下,不会发生溢出,因为使用双倍长度寄存器来保留产品。 但是,在分割的情况下,可能会发生溢出。 如果发生溢出,处理器会产生中断。
DIV(Divide)指令用于无符号数据,IDIV(整数除)用于签名数据。
语法 (Syntax)
DIV/IDIV指令的格式 -
DIV/IDIV divisor
股息在累加器中。 这两条指令都可以用于8位,16位或32位操作数。 该操作会影响所有六个状态标志。 以下部分介绍了具有不同操作数大小的三种划分案例 -
| Sr.No. | 方案 |
|---|---|
| 1 | When the divisor is 1 byte − 假设被除数在AX寄存器中(16位)。 除法后,商进入AL寄存器,余数进入AH寄存器。
|
| 2 | When the divisor is 1 word − 假设被除数为32位,在DX:AX寄存器中。 高阶16位在DX中,低阶16位在AX中。 除法后,16位商进入AX寄存器,16位余数进入DX寄存器。
|
| 3 | When the divisor is doubleword − 假设被除数为64位,并且在EDX:EAX寄存器中。 高阶32位在EDX中,低阶32位在EAX中。 除法后,32位商进入EAX寄存器,32位余数进入EDX寄存器。
|

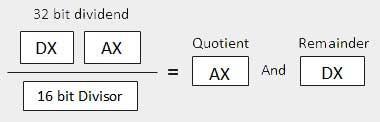
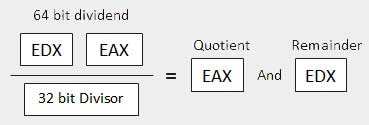
例子 (Example)
以下示例将8除以2. dividend 8存储在16-bit AX register , divisor 2存储在8-bit BL register 。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1
编译并执行上述代码时,会产生以下结果 -
The result is:
4
Assembly - Logical Instructions
处理器指令集提供指令AND,OR,XOR,TEST和NOT布尔逻辑,根据程序的需要测试,设置和清除位。
这些说明的格式 -
| Sr.No. | 指令 | 格式 |
|---|---|---|
| 1 | AND | AND operand1,operand2 |
| 2 | OR | 或操作数1,操作数2 |
| 3 | XOR | XOR operand1,operand2 |
| 4 | TEST | TEST操作数1,操作数2 |
| 5 | NOT | NOT operandrand1 |
所有情况下的第一个操作数可以是寄存器也可以是内存。 第二个操作数可以是寄存器/内存或立即(常量)值。 但是,内存到内存操作是不可能的。 这些指令比较或匹配操作数的位,并设置CF,OF,PF,SF和ZF标志。
AND指令
AND指令用于通过执行按位AND运算来支持逻辑表达式。 如果来自两个操作数的匹配位为1,则按位AND操作返回1,否则返回0.例如 -
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001
AND操作可用于清除一个或多个位。 例如,假设BL寄存器包含0011 1010.如果需要将高位清零,则将其与0FH进行AND运算。
AND BL, 0FH ; This sets BL to 0000 1010
让我们举另一个例子。 如果要检查给定数字是奇数还是偶数,一个简单的测试就是检查数字的最低有效位。 如果为1,则数字为奇数,否则数字为偶数。
假设数字在AL寄存器中,我们可以写 -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBER
以下程序说明了这一点 -
例子 (Example)
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg
odd_msg db 'Odd Number!' ;message showing odd number
len2 equ $ - odd_msg
编译并执行上述代码时,会产生以下结果 -
Even Number!
使用奇数位更改ax寄存器中的值,如 -
mov ax, 9h ; getting 9 in the ax
该程序将显示:
Odd Number!
同样清除整个寄存器,你可以用00H清除它。
OR指令
OR指令用于通过执行按位OR运算来支持逻辑表达式。 如果来自任一操作数或两个操作数的匹配位为1,则按位OR运算符返回1。 如果两个位都为零,则返回0。
例如,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111
OR运算可用于设置一个或多个位。 例如,让我们假设AL寄存器包含0011 1010,您需要设置四个低位,您可以使用值0000 1111进行OR运算,即FH。
OR BL, 0FH ; This sets BL to 0011 1111
例子 (Example)
以下示例演示OR指令。 让我们分别在AL和BL寄存器中存储值5和3,然后是指令,
OR AL, BL
应该在AL寄存器中存储7个 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1
编译并执行上述代码时,会产生以下结果 -
7
XOR指令
XOR指令实现按位XOR运算。 当且仅当来自操作数的位不同时,XOR操作将结果位设置为1。 如果来自操作数的位相同(均为0或均为1),则结果位清零。
例如,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110
对操作数进行XORing操作XORing操作数更改为0 。 这用于清除寄存器。
XOR EAX, EAX
测试指令
TEST指令与AND操作的作用相同,但与AND指令不同,它不会更改第一个操作数。 因此,如果我们需要检查寄存器中的数字是偶数还是奇数,我们也可以使用TEST指令执行此操作而不更改原始数字。
TEST AL, 01H
JZ EVEN_NUMBER
NOT指令
NOT指令实现按位NOT操作。 NOT操作会反转操作数中的位。 操作数可以在寄存器中,也可以在内存中。
例如,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100
Assembly - Conditions
汇编语言中的条件执行是通过几个循环和分支指令完成的。 这些指令可以改变程序中的控制流程。 在两种情况下观察到条件执行 -
| Sr.No. | 条件指令 |
|---|---|
| 1 | Unconditional jump 这是由JMP指令执行的。 条件执行通常涉及将控制转移到不遵循当前正在执行的指令的指令的地址。 控制转移可以是转发,执行一组新指令或反向转移,以重新执行相同的步骤。 |
| 2 | Conditional jump 这是由一组跳转指令j |
在讨论条件指令之前,让我们讨论CMP指令。
CMP指令
CMP指令比较两个操作数。 它通常用于条件执行。 该指令基本上从另一个操作数中减去一个操作数,以比较操作数是否相等。 它不会干扰目标或源操作数。 它与条件跳转指令一起用于决策。
语法 (Syntax)
CMP destination, source
CMP比较两个数字数据字段。 目标操作数可以在寄存器中,也可以在内存中。 源操作数可以是常量(立即)数据,寄存器或存储器。
例子 (Example)
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...
CMP通常用于比较计数器值是否已达到循环需要运行的次数。 考虑以下典型情况 -
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1
无条件跳转
如前所述,这是由JMP指令执行的。 条件执行通常涉及将控制转移到不遵循当前正在执行的指令的指令的地址。 控制转移可以是转发,执行一组新指令或反向转移,以重新执行相同的步骤。
语法 (Syntax)
JMP指令提供标签名称,其中控制流立即传输。 JMP指令的语法是 -
JMP label
例子 (Example)
以下代码片段说明了JMP指令 -
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statements
有条件的跳转
如果在条件跳转中满足某些指定条件,则控制流被转移到目标指令。 根据条件和数据,有许多条件跳转指令。
以下是用于算术运算的带符号数据的条件跳转指令 -
| 指令 | 描述 | 标志测试 |
|---|---|---|
| JE/JZ | 跳跃等于或跳零 | ZF |
| JNE/JNZ | 跳不等或跳不零 | ZF |
| JG/JNLE | 跳得更大或跳不少/等 | OF, SF, ZF |
| JGE/JNL | 跳跃更大/相等或跳跃不少 | OF, SF |
| JL/JNGE | 跳得少或跳得不大/等于 | OF, SF |
| JLE/JNG | 跳得少/等等或跳得不大 | OF, SF, ZF |
以下是用于逻辑运算的无符号数据的条件跳转指令 -
| 指令 | 描述 | 标志测试 |
|---|---|---|
| JE/JZ | 跳跃等于或跳零 | ZF |
| JNE/JNZ | 跳不等或跳不零 | ZF |
| JA/JNBE | 跳到上方或跳不低于/等于 | CF, ZF |
| JAE/JNB | 跳到上方/等于或跳不到下方 | CF |
| JB/JNAE | 跳到下面或跳不高于/等于 | CF |
| JBE/JNA | 跳低于/等于或跳不高于 | AF, CF |
以下条件跳转指令有特殊用途并检查标志的值 -
| 指令 | 描述 | 标志测试 |
|---|---|---|
| JXCZ | 如果CX为零则跳转 | none |
| JC | Jump If Carry | CF |
| JNC | Jump If No Carry | CF |
| JO | Jump If Overflow | OF |
| JNO | Jump If No Overflow | OF |
| JP/JPE | 跳跃奇偶校验或跳跃奇偶校验 | PF |
| JNP/JPO | 跳跃没有奇偶校验或跳跃奇偶校验 | PF |
| JS | Jump Sign (negative value) | SF |
| JNS | 跳号码(正值) | SF |
J
例,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...
例子 (Example)
以下程序显示三个变量中最大的一个。 变量是两位数的变量。 三个变量num1,num2和num3分别具有值47,22和31 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2
编译并执行上述代码时,会产生以下结果 -
The largest digit is:
47
Assembly - Loops
JMP指令可用于实现循环。 例如,以下代码片段可用于执行循环体10次。
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1
然而,处理器指令集包括一组用于实现迭代的循环指令。 基本LOOP指令具有以下语法 -
LOOP label
其中, label是标识目标指令的目标标签,如跳转指令中所示。 LOOP指令假定ECX register contains the loop count 。 执行循环指令时,ECX寄存器递减,控制跳转到目标标签,直到ECX寄存器值,即计数器达到零值。
上面的代码片段可以写成 -
mov ECX,10
l1:
<loop body>
loop l1
例子 (Example)
以下程序在屏幕上打印数字1到9 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1
编译并执行上述代码时,会产生以下结果 -
123456789:
Assembly - Numbers
数值数据通常以二元系统表示。 算术指令对二进制数据进行操作。 当数字显示在屏幕上或从键盘输入时,它们是ASCII格式。
到目前为止,我们已将ASCII格式的输入数据转换为二进制以进行算术计算,并将结果转换回二进制。 以下代码显示了这一点 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1
编译并执行上述代码时,会产生以下结果 -
The sum is:
7
然而,这种转换具有开销,并且汇编语言编程允许以二进制形式以更有效的方式处理数字。 十进制数字可以用两种形式表示 -
- ASCII格式
- BCD或二进制编码的十进制形式
ASCII表示
在ASCII表示中,十进制数字存储为ASCII字符串。 例如,十进制值1234存储为 -
31 32 33 34H
其中,31H是1的ASCII值,32H是2的ASCII值,依此类推。 在ASCII表示中有四个处理数字的指令 -
AAA - 添加后的ASCII调整
AAS - 减法后的ASCII调整
AAM - 乘法后的ASCII调整
AAD - 划分前的ASCII调整
这些指令不接受任何操作数,并假设所需的操作数位于AL寄存器中。
以下示例使用AAS指令演示该概念 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1
编译并执行上述代码时,会产生以下结果 -
The Result is:
6
BCD表示
有两种类型的BCD表示 -
- 解包BCD表示
- 打包BCD表示
在解包的BCD表示中,每个字节存储十进制数的二进制等值。 例如,数字1234存储为 -
01 02 03 04H
处理这些数字有两条说明 -
AAM - 乘法后的ASCII调整
AAD - 划分前的ASCII调整
四个ASCII调整指令AAA,AAS,AAM和AAD也可以与解压缩的BCD表示一起使用。 在打包的BCD表示中,每个数字使用四位存储。 两个十进制数字打包成一个字节。 例如,数字1234存储为 -
12 34H
处理这些数字有两条说明 -
DAA - 添加后的十进制调整
DAS - 减法后的十进制调整
在打包的BCD表示中不支持乘法和除法。
例子 (Example)
以下程序将两个5位十进制数相加并显示总和。 它使用了上述概念 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' '
编译并执行上述代码时,会产生以下结果 -
The Sum is:
35801
Assembly - Strings
我们在前面的例子中已经使用了可变长度字符串。 可变长度字符串可以包含所需的字符数。 通常,我们通过两种方式之一指定字符串的长度 -
- 显式存储字符串长度
- Using a sentinel character
我们可以使用$ location计数器符号显式存储字符串长度,该符号表示位置计数器的当前值。 在以下示例中 -
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string
$指向字符串变量msg的最后一个字符后的字节。 因此, $-msg给出字符串的长度。 我们也可以写
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear string
或者,您可以存储带有尾随sentinel字符的字符串来分隔字符串,而不是显式地存储字符串长度。 sentinel字符应该是一个不出现在字符串中的特殊字符。
例如 -
message DB 'I am loving it!', 0
字符串说明
每个字符串指令可能需要源操作数,目标操作数或两者。 对于32位段,字符串指令使用ESI和EDI寄存器分别指向源和目标操作数。
但是,对于16位段,SI和DI寄存器分别用于指向源和目标。
处理字符串有五个基本指令。 他们是 -
MOVS - 该指令将1字节,字或双字数据从内存位置移动到另一个位置。
LODS - 该指令从内存加载。 如果操作数是一个字节,则将其加载到AL寄存器中,如果操作数是一个字,则将其加载到AX寄存器中,并将双字加载到EAX寄存器中。
STOS - 该指令将寄存器(AL,AX或EAX)中的数据存储到存储器中。
CMPS - 该指令比较内存中的两个数据项。 数据可以是字节大小,字或双字。
SCAS - 该指令将寄存器(AL,AX或EAX)的内容与内存中项目的内容进行比较。
上述指令中的每一个都具有字节,字和双字版本,并且可以通过使用重复前缀来重复字符串指令。
这些指令使用ES:DI和DS:SI寄存器对,其中DI和SI寄存器包含有效的偏移地址,指向存储在存储器中的字节。 SI通常与DS(数据段)相关联,DI始终与ES(额外段)相关联。
DS:SI(或ESI)和ES:DI(或EDI)寄存器分别指向源和目标操作数。 假设源操作数为DS:SI(或ESI),ES中的目标操作数:内存中的DI(或EDI)。
对于16位地址,使用SI和DI寄存器,对于32位地址,使用ESI和EDI寄存器。
下表提供了各种版本的字符串指令和操作数的假定空间。
| 基本教学 | 操作数在 | 字节操作 | 单词操作 | 双字操作 |
|---|---|---|---|---|
| MOVS | ES:DI, DS:SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS:SI | LODSB | LODSW | LODSD |
| STOS | ES:DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS:SI,ES:DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES:DI, AX | SCASB | SCASW | SCASD |
重复前缀
REP字符串在字符串指令之前设置时,例如REP MOVSB,会根据放置在CX寄存器中的计数器重复该指令。 REP执行指令,将CX减1,并检查CX是否为零。 它重复指令处理直到CX为零。
方向标志(DF)确定操作的方向。
- 使用CLD(清除方向标志,DF = 0)使操作从左到右。
- 使用STD(设置方向标志,DF = 1)使操作从右向左。
REP前缀还具有以下变体:
记者:这是无条件的重复。 它重复操作直到CX为零。
REPE或REPZ:有条件重复。 它重复操作,而零标志指示等于/零。 当ZF指示不等于/零或CX为零时停止。
REPNE或REPNZ:这也是有条件的重复。 它在零标志指示不等于/零时重复该操作。 当ZF指示等于/零或CX递减为零时停止。
Assembly - Arrays
我们已经讨论过汇编程序的数据定义指令用于为变量分配存储空间。 变量也可以用一些特定值初始化。 初始化值可以以十六进制,十进制或二进制形式指定。
例如,我们可以通过以下任一方式定义单词变量'months' -
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110B
数据定义指令也可用于定义一维数组。 让我们定义一维数字数组。
NUMBERS DW 34, 45, 56, 67, 75, 89
上面的定义声明了一个由六个字组成的数组,每个字用数字34,45,56,67,75,89初始化。这分配了2x6 = 12字节的连续存储空间。 第一个数字的符号地址为NUMBERS,第二个数字的符号地址为NUMBERS + 2,依此类推。
让我们再举一个例子。 您可以定义名为inventory的大小为8的数组,并将所有值初始化为零,如 -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
可以缩写为 -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0
TIMES指令还可用于对同一值的多次初始化。 使用TIMES,INVENTORY数组可以定义为:
INVENTORY TIMES 8 DW 0
例子 (Example)
以下示例通过定义3元素数组x来演示上述概念,该数组存储三个值:2,3和4.它在数组中添加值并显示总和9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0
编译并执行上述代码时,会产生以下结果 -
9
Assembly - Procedures
程序或子程序在汇编语言中非常重要,因为汇编语言程序的大小往往很大。 程序由名称标识。 遵循此名称,描述了执行明确定义的作业的过程的主体。 程序结束由return语句指示。
语法 (Syntax)
以下是定义过程的语法 -
proc_name:
procedure body
...
ret
通过使用CALL指令从另一个函数调用该过程。 CALL指令应该将被调用过程的名称作为参数,如下所示 -
CALL proc_name
被调用过程使用RET指令将控制返回给调用过程。
例子 (Example)
让我们编写一个名为sum的非常简单的过程,它添加存储在ECX和EDX寄存器中的变量并返回EAX寄存器中的总和 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1
编译并执行上述代码时,会产生以下结果 -
The sum is:
9
堆栈数据结构
堆栈是存储器中类似于阵列的数据结构,其中数据可以被存储并从称为堆栈的“顶部”的位置移除。 需要存储的数据被“推送”到堆栈中,要检索的数据从堆栈中“弹出”。 Stack是LIFO数据结构,即最后检索的数据是最后检索的。
汇编语言提供了两种堆栈操作说明:PUSH和POP。 这些说明的语法如下 -
PUSH operand
POP address/register
堆栈段中保留的内存空间用于实现堆栈。 寄存器SS和ESP(或SP)用于实现堆栈。 堆栈的顶部指向插入堆栈的最后一个数据项,由SS:ESP寄存器指向,其中SS寄存器指向堆栈段的开头,SP(或ESP)将偏移量指向堆栈段。
堆栈实现具有以下特征 -
只有words或doublewords可以保存到堆栈中,而不是字节。
堆栈沿相反方向增长,即朝向较低的存储器地址
堆栈顶部指向堆栈中插入的最后一项; 它指向插入的最后一个单词的低位字节。
正如我们讨论的那样,在将寄存器的值用于某些用途之前将其存储在堆栈中; 它可以通过以下方式完成 -
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP AX
POP BX
例子 (Example)
以下程序显示整个ASCII字符集。 主程序调用名为display的过程,该过程显示ASCII字符集。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'
编译并执行上述代码时,会产生以下结果 -
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...
Assembly - Recursion
递归过程就是自称过程。 有两种递归:直接和间接。 在直接递归中,过程调用自身并在间接递归中,第一个过程调用第二个过程,该过程又调用第一个过程。
可以在许多数学算法中观察到递归。 例如,考虑计算数字的阶乘的情况。 一个数的因子由等式给出 -
Fact (n) = n * fact (n-1) for n > 0
例如:5的阶乘是1 x 2 x 3 x 4 x 5 = 5 x阶乘4,这可以是显示递归过程的一个很好的例子。 每个递归算法必须具有结束条件,即,当满足条件时应该停止程序的递归调用。 在阶乘算法的情况下,当n为0时达到结束条件。
以下程序显示了如何使用汇编语言实现factorial n。 为了简化程序,我们将计算阶乘3。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1
编译并执行上述代码时,会产生以下结果 -
Factorial 3 is:
6
Assembly - Macros
编写宏是确保汇编语言模块化编程的另一种方法。
宏是一系列指令,由名称分配,可以在程序中的任何位置使用。
在NASM中,使用%macro和%endmacro指令定义%macro 。
宏以%宏指令开头,以%endmacro指令结束。
宏定义的语法 -
%macro macro_name number_of_params
<macro body>
%endmacro
其中, number_of_params指定数字参数, macro_name指定宏的名称。
通过使用宏名称和必要的参数来调用宏。 当您需要在程序中多次使用某些指令序列时,您可以将这些指令放在宏中并使用它而不是一直写入指令。
例如,对程序的一个非常普遍的需求是在屏幕上写入一串字符。 要显示一串字符,您需要以下一系列说明 -
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
在上面显示字符串的示例中,INT 80H函数调用已使用寄存器EAX,EBX,ECX和EDX。 因此,每次需要在屏幕上显示时,需要将这些寄存器保存在堆栈中,调用INT 80H,然后从堆栈中恢复寄存器的原始值。 因此,编写两个用于保存和恢复数据的宏可能很有用。
我们已经观察到,诸如IMUL,IDIV,INT等的一些指令需要将一些信息存储在某些特定寄存器中,甚至在某些特定寄存器中返回值。 如果程序已经使用这些寄存器来保存重要数据,那么来自这些寄存器的现有数据应该保存在堆栈中并在执行指令后恢复。
例子 (Example)
以下示例显示了定义和使用宏 -
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3
编译并执行上述代码时,会产生以下结果 -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!
Assembly - File Management
系统将任何输入或输出数据视为字节流。 有三个标准文件流 -
- 标准输入(stdin),
- 标准输出(标准输出),和
- 标准错误(stderr)。
文件描述符
file descriptor是作为文件ID分配给文件的16位整数。 创建新文件或打开现有文件时,文件描述符用于访问文件。
标准文件流的文件描述符 - stdin, stdout和stderr分别为0,1和2。
文件指针
file pointer以字节为单位指定file pointer后续读/写操作的位置。 每个文件都被视为一个字节序列。 每个打开的文件都与一个文件指针相关联,该文件指针指定相对于文件开头的字节偏移量。 打开文件时,文件指针设置为零。
文件处理系统调用
下表简要描述了与文件处理相关的系统调用 -
| EAX% | 名称 | EBX% | %ECX | %EDX |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
正如我们之前讨论的那样,使用系统调用所需的步骤是相同的 -
- 将系统调用号放在EAX寄存器中。
- 将参数存储在寄存器EBX,ECX等中的系统调用中。
- 调用相关的中断(80h)。
- 结果通常在EAX寄存器中返回。
创建和打开文件
要创建和打开文件,请执行以下任务 -
- 将系统调用sys_creat()编号8放在EAX寄存器中。
- 将文件名放在EBX寄存器中。
- 将文件权限放在ECX寄存器中。
系统调用在EAX寄存器中返回创建文件的文件描述符,如果出错,则错误代码在EAX寄存器中。
打开现有文件
要打开现有文件,请执行以下任务 -
- 将系统调用sys_open()编号5放在EAX寄存器中。
- 将文件名放在EBX寄存器中。
- 将文件访问模式放在ECX寄存器中。
- 将文件权限放在EDX寄存器中。
系统调用在EAX寄存器中返回创建文件的文件描述符,如果出错,则错误代码在EAX寄存器中。
在文件访问模式中,最常用的是:只读(0),只写(1)和读写(2)。
从文件中读取 (Reading from a File)
要从文件中读取,请执行以下任务 -
将系统调用sys_read()编号3放在EAX寄存器中。
将文件描述符放在EBX寄存器中。
将指针指向ECX寄存器中的输入缓冲区。
将缓冲区大小(即要读取的字节数)放在EDX寄存器中。
系统调用返回EAX寄存器中读取的字节数,如果出错,则错误代码位于EAX寄存器中。
写入文件
要写入文件,请执行以下任务 -
将系统调用sys_write()编号4放入EAX寄存器中。
将文件描述符放在EBX寄存器中。
将指针指向ECX寄存器中的输出缓冲区。
将缓冲区大小(即要写入的字节数)放在EDX寄存器中。
系统调用返回EAX寄存器中写入的实际字节数,如果出错,则错误代码位于EAX寄存器中。
关闭一个文件 (Closing a File)
要关闭文件,请执行以下任务 -
- 将系统调用sys_close()编号6放入EAX寄存器中。
- 将文件描述符放在EBX寄存器中。
如果出错,系统调用将返回EAX寄存器中的错误代码。
更新文件
要更新文件,请执行以下任务 -
- 将系统调用sys_lseek()编号19放在EAX寄存器中。
- 将文件描述符放在EBX寄存器中。
- 将偏移值放在ECX寄存器中。
- 将偏移的参考位置放在EDX寄存器中。
参考位置可以是:
- 文件的开头 - 值为0
- 当前位置 - 值1
- 文件结束 - 值2
如果出错,系统调用将返回EAX寄存器中的错误代码。
例子 (Example)
以下程序创建并打开名为myfile.txt的文件,并在此文件中写入文本“Welcome to IOWIKI”。 接下来,程序从文件中读取并将数据存储到名为info的缓冲区中。 最后,它显示存储在info的文本。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to IOWIKI'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26
编译并执行上述代码时,会产生以下结果 -
Written to file
Welcome to IOWIKI
Assembly - Memory Management
sys_brk()系统调用由内核提供,用于分配内存而无需在以后移动它。 此调用在内存中的应用程序映像后面分配内存。 此系统功能允许您在数据部分中设置最高可用地址。
此系统调用采用一个参数,这是需要设置的最高内存地址。 该值存储在EBX寄存器中。
如果有任何错误,sys_brk()返回-1或返回负错误代码本身。 以下示例演示了动态内存分配。
例子 (Example)
以下程序使用sys_brk()系统调用分配16kb的内存 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msg
编译并执行上述代码时,会产生以下结果 -
Allocated 16 kb of memory!
